目录
2.基于JWT技术及RSA非对称加密实现真正无状态的单点登录
4.基于 Django 的后台管理平台,采用 RBAC 权限管理机制
6.借助xterm.js、paramiko、Dwebsocket、SSH完成WebSSH在线编程
8.集成支付宝、微信、银联等进行聚合支付(怎么保证接口安全)
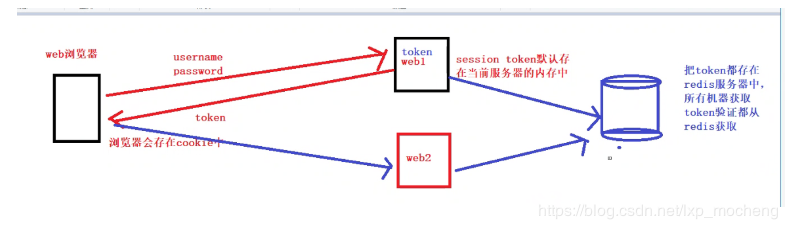
1.使用Redis实现分布式部署单点登录(单点登录第一种方法:redis分布式存储解决方案)
因为这个项目是一个分布式部署的项目,而且我们采用的是nginx负载均衡的策略,导致了每一个服务器都需要开辟一个空间来进行用户信息的维护,消耗了大量的资源,所以,我当时使用到了Redis来作为维护用户信息的空间,将用户登录的信息存入Redis中,并且在存入时设置key的过期时间,所有的服务器共用一个Redis,每次进行操作时只需要去Redis中去判断这个用户是否存在,存在的话就说明这个用户现在是登录状态,不存在就说明这个用户没有登录,或者登录已经失效,让用户进行重新登录。
- 为什么会存在单点登录的问题
session默认是存储在当前服务器的内存中,如果是集群,那么只有登录那台机器的内存中才有这个session
比如说我在A机器登录,B机器是没有这个session存在的,所以需要重新验证
- 如何解决这个单点登录问题
不管在那一台web服务器登录,都会把token值存放到我们的一个集中管理的redis服务器中
但客户端携带token验证的时候,会先从redis中获取,就实现单点登录
- 现实举例
比如你写的一个tornado项目,分别部署到A,B两台机器上
如果直接使用session,那么如果在A机器登录,token只会在A服务器的内存
因为请求会封不到A,b连个机器,如果这个请求到了B机器,B的内存中没有就会让重新登录
所以登录A机器的时候我们应该把token值写入到redis中,A/B机器登录,都从redis中获取token进行校验
2.基于JWT技术及RSA非对称加密实现真正无状态的单点登录(单点等第二种方法:JWT)
- 无状态登录原理
1 在分布式系统中,传统的登录会失效。 2 3 原因是因为各个微服务之间用的不是同一台服务器,我们以前登录判断用户状态是通过服务器中session存的数据,也就是把用户信息保存在session中,现在我们有几台不同的服务器,在这台登录完会有一个session信息,但是跳到另外一个服务器,登录状态就会消失,所以登录状态是无法共享的。 4 5 因此之前我们学的登录在分布式系统中是无法使用的,不能存储到session中。
- 什么是有状态?
就是服务端需要记录一下每次会话的客户端信息,从而识别客户端他的身份,根据用户的身份进行请求的处理。 比如: 服务器中的session存储
例如登录:
用户登录后,我们把登录者的信息保存在服务端session中,并且给用户一个cookie值,记录对应的session。然后下次请求,用户携带cookie值来,我们就能识别到对应session,从而找到用户的信息。
缺点是什么? 1.服务端如果搭建集群,集群之间的数据无法共享,于是用户状态无法共享,就不能实现一个跨服务的登录 2.服务端保存大量数据,增加服务端压力 3.服务端保存用户状态,无法进行水平扩展 4.客户端请求依赖服务端,多次请求必须访问同一台服务器
- 什么是无状态?
识别用户的身份信息是由客户端自己去携带
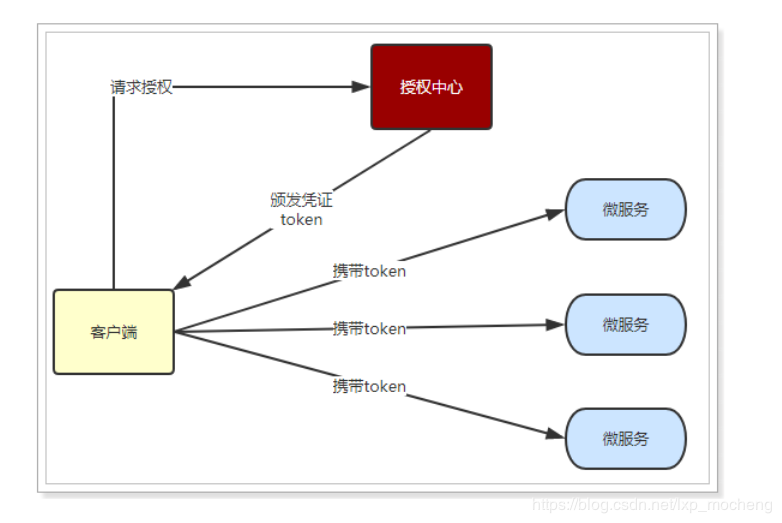
微服务集群中的每个服务,对外提供的都是Rest风格的接口。而Rest风格的一个最重要的规范就是:服务的无状态性,即:
服务端不保存任何客户端请求者信息
客户端的每次请求必须具备自描述信息,通过这些信息识别客户端身份
带来的好处是什么呢? 1.客户端请求不依赖服务端的信息,任何多次请求不需要必须访问到同一台服务 2.服务端的集群和状态对客户端透明 3.服务端可以任意的迁移和伸缩 4.减小服务端存储压力
如何实现无状态
1 无状态登录的流程: 2 1.当客户端第一次请求服务时,服务端对用户进行信息认证(登录) 3 2.认证通过,将用户信息进行加密形成token,返回给客户端,作为登录凭证 4 3.以后每次请求,客户端都携带认证的token 5 4.服务的对token进行解密,判断是否有效。
1 整个登录过程中,最关键的点是:token的安全性 2 3 token是识别客户端身份的唯一标示,如果加密不够严密,被人伪造那就完蛋了。 4 5 采用何种方式加密才是安全可靠的呢? 6 7 我们将采用JWT + RSA非对称加密
jwt
- 简介
JWT,全称是Json Web Token, 是JSON风格轻量级的授权和身份认证规范,可实现无状态、分布式的Web应用授权
- 数据格式
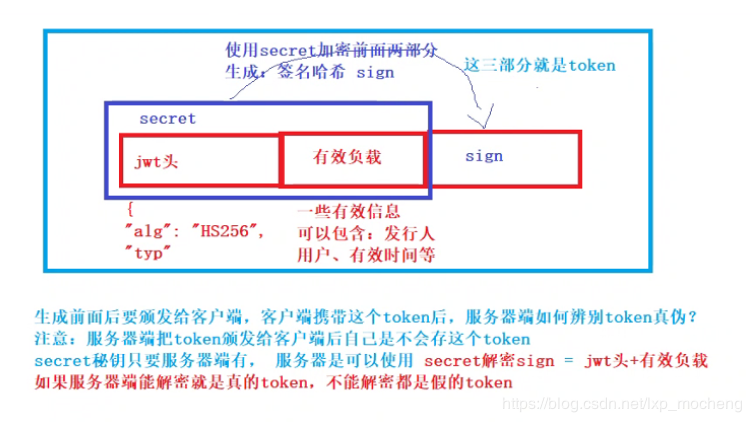
JWT包含三部分数据:
Header:头部,通常头部有两部分信息:
声明类型,这里是JWT
加密算法,自定义(我们用的RSA)
我们会对头部进行base64加密(可解密),得到第一部分数据
Payload:载荷,就是有效数据,一般包含下面信息:
用户身份信息(注意,这里因为采用base64加密,可解密,因此不要存放敏感信息)
注册声明:如token的签发时间,过期时间,签发人等
这部分也会采用base64加密,得到第二部分数据
Signature:签名,是整个数据的认证信息。通过base64对头和载荷进行编码,一般根据前两步的数据,再加上服务的的密钥(secret)(不要泄漏,最好周期性更换),通过加密算法生成(RSA算法进行加密,无法进行篡改)。用于验证整个数据完整和可靠性

jwt交互流程
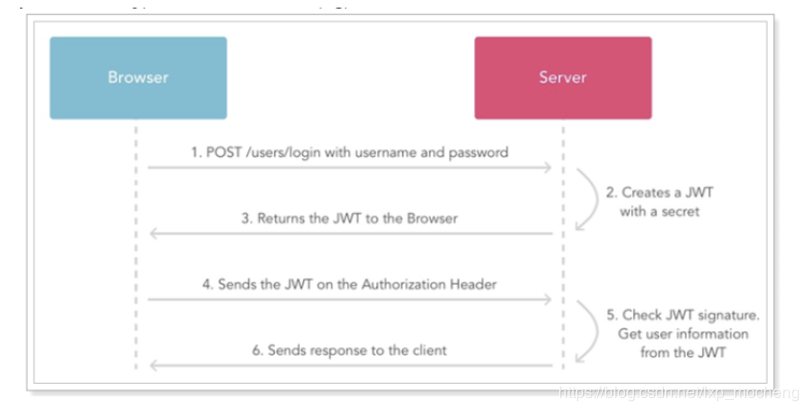
1、用户登录 2、服务的认证,通过后根据secret生成token 3、将生成的token返回给用户 4、用户每次请求携带token 5、服务端利用公钥解读jwt签名,判断签名有效后,从Payload中获取用户信息 6、处理请求,返回响应结果
因为JWT签发的token中已经包含了用户的身份信息,并且每次请求都会携带,这样服务的就无需保存用户信息,甚至无需去数据库查询,完全符合了Rest的无状态规范。
非对称加密
加密技术是对信息进行编码和解码的技术,编码是把原来可读信息(又称明文)译成代码形式(又称密文),其逆过程就是解码(解密),加密技术的要点是加密算法,加密算法可以分为三类:
对称加密、非对称加密、不可逆加密
1 对称加密,如AES(通信双方都持有相同秘钥) 2 3 基本原理:将明文分成N个组,然后使用密钥对各个组进行加密,形成各自的密文,最后把所有的分组密文进行合并,形成最终的密文。 4 5 优势:算法公开、计算量小、加密速度快、加密效率高 6 缺陷:双方都使用同样密钥,安全性得不到保证
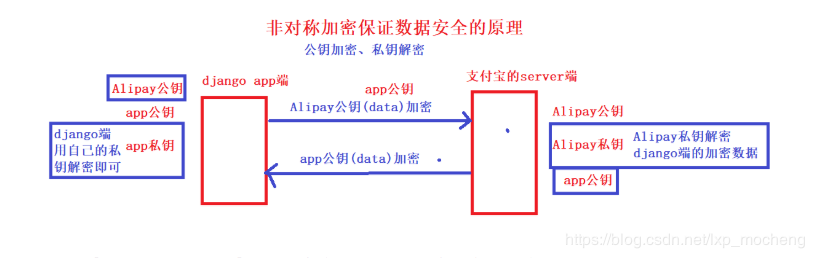
1 非对称加密,如RSA 2 3 基本原理:同时生成两把密钥:私钥和公钥,私钥隐秘保存,公钥可以下发给信任客户端 4 私钥加密,持有私钥或公钥才可以解密 5 公钥加密,持有私钥才可解密 6 7 优点:安全,难以破解 8 缺点:算法比较耗时
不可逆加密,如MD5,SHA
基本原理:加密过程中不需要使用密钥,输入明文后由系统直接经过加密算法处理成密文,这种加密后的数据是无法被解密的,无法根据密文推算出明文。
RSA算法历史:
1977年,三位数学家Rivest、Shamir 和 Adleman 设计了一种算法,可以实现非对称加密。这种算法用他们三个人的名字缩写:RSA
3.用户登录对接QQ、微信、微博等三方登录
参考博客:https://www.cnblogs.com/xiaonq/p/12271345.html
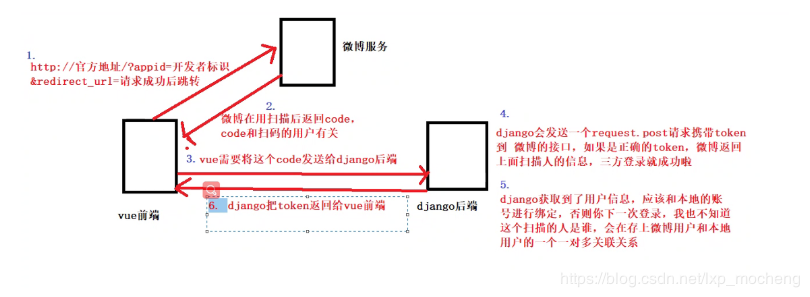
4.基于 Django 的后台管理平台,采用 RBAC 权限管理机制
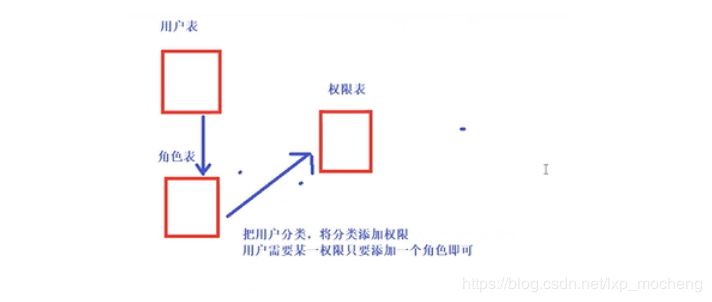
- 用户表、角色表、权限表
1 用户与角色进行关联,角色与权限进行关联 2 django本身自带角色权限管理机制
5.结合DRF框架提供标准RESTful API接口
https://www.cnblogs.com/xiaonq/p/10053234.html
RESTful不是一种技术,而是一种接口规范,主要规范包括:1.请求方式、2.状态码、3、url规范、4、传参规范
- 请求方式method
GET :从服务器取出资源(一项或多项)
POST :在服务器新建一个资源
PUT :在服务器更新资源(客户端提供改变后的完整资源)
PATCH :在服务器更新资源(客户端提供改变的属性)
DELETE :从服务器删除资源
- 状态码
1 '''1. 2XX请求成功''' 2 # 200 请求成功,一般用于GET与POST请求 3 # 201 Created - [POST/PUT/PATCH]:用户新建或修改数据成功。 4 # 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 5 # 204 NO CONTENT - [DELETE]:用户删除数据成功。 6 '''2. 3XX重定向''' 7 # 301 NO CONTENT - 永久重定向 8 # 302 NO CONTENT - 临时重定向 9 '''3. 4XX客户端错误''' 10 # 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误。 11 # 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 12 # 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 13 # 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录。 14 # 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 15 # 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 16 # 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 17 '''4. 5XX服务端错误''' 18 # 500 INTERNAL SERVER ERROR - [*]:服务器内部错误,无法完成请求 19 # 501 Not Implemented 服务器不支持请求的功能,无法完成请求
- 面向资源编程: 路径,视网络上任何东西都是资源,均使用名词表示(可复数)
所有请求实际操作的都是数据库中的表,每一个表当做一个资源
资源是一个名称,所以RESTful规范中URL只能有名称或名词的复数形式
https://api.example.com/v1/zoos
https://api.example.com/v1/animals
https://api.example.com/v1/employees
过滤,通过在url上传参的形式传递搜索条件
- https://api.example.com/v1/zoos?limit=10:指定返回记录的数量
https://api.example.com/v1/zoos?offset=10:指定返回记录的开始位置
https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数
https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件
django的DRF
https://www.cnblogs.com/xiaonq/p/10987889.html
- 认证
- 权限
- 序列化
- 版本号
- 限流
要求:对照上面的博客把,认证,权限,序列化
6.借助xterm.js、paramiko、Dwebsocket、SSH完成WebSSH在线编程
websocket:https://www.cnblogs.com/xiaonq/p/12238651.html
webssh:https://www.cnblogs.com/xiaonq/p/12243024.html
1.什么是WebSSH?
- webssh 泛指一种技术可以在网页上实现一个 SSH 终端。
- ssh终端:用来通过ssh协议,连接服务器进行管理
- 运维开发方向:堡垒机登录、线上机器管理(因为运维人员不肯能24小时携带电脑)
- 在线编程:提供一个编程环境
2.websocket
- 什么是websocket
webSocket是一种在单个TCP连接上进行全双工通信的协议
客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。
浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输
- 远古时期解决方案就是轮训
客户端以设定的时间间隔周期性地向服务端发送请求,频繁地查询是否有新的数据改动(浪费流量和资源)
- webSocket应用场景?
聊天软件:最著名的就是微信,QQ,这一类社交聊天的app
弹幕:各种直播的弹幕窗口
在线教育:可以视频聊天、即时聊天以及其与别人合作一起在网上讨论问题…
- websocket与http区别
http请求建立连接只能发送一次请求
websocket建立的长连接,一次连接,后续一直通信,这样节省资源
- websocket原理
websocket首先借助http协议(通过在http头部设置属性,请求和服务器进行协议升级,升级协议为websocket的应用层协议)
建立好和服务器之间的数据流,数据流之间底层还是依靠TCP协议;
websocket会接着使用这条建立好的数据流和服务器之间保持通信;
由于复杂的网络环境,数据流可能会断开,在实际使用过程中,我们在onFailure或者onClosing回调方法中,实现重连
- websocket实现心跳检测的思路
通过setInterval定时任务每个3秒钟调用一次reconnect函数
reconnect会通过socket.readyState来判断这个websocket连接是否正常
如果不正常就会触发定时连接,每4s钟重试一次,直到连接成功
如果是网络断开的情况下,在指定的时间内服务器端并没有返回心跳响应消息,因此服务器端断开了。
服务断开我们使用ws.close关闭连接,在一段时间后,可以通过 onclose事件监听到。
redis常用命令


1 import redis 2 r = redis.Redis(host='1.1.1.3', port=6379) 3 4 #1、打印这个Redis缓存所有key以列表形式返回:[b'name222', b'foo'] 5 print( r.keys() ) # keys * 6 7 #2、清空redis 8 r.flushall() 9 10 #3、设置存在时间: ex=1指这个变量只会存在1秒,1秒后就不存在了 11 r.set('name', 'Alex') # ssetex name Alex 12 r.set('name', 'Alex',ex=1) # ssetex name 1 Alex 13 14 #4、获取对应key的value 15 print(r.get('name')) # get name 16 17 #5、删除指定的key 18 r.delete('name') # del 'name' 19 20 #6、避免覆盖已有的值: nx=True指只有当字典中没有name这个key才会执行 21 r.set('name', 'Tom',nx=True) # setnx name alex 22 23 #7、重新赋值: xx=True只有当字典中已经有key值name才会执行 24 r.set('name', 'Fly',xx=True) # set name alex xx 25 26 #8、psetex(name, time_ms, value) time_ms,过期时间(数字毫秒 或 timedelta对象) 27 r.psetex('name',10,'Tom') # psetex name 10000 alex 28 29 #10、mset 批量设置值; mget 批量获取 30 r.mset(key1='value1', key2='value2') # mset k1 v1 k2 v2 k3 v3 31 print(r.mget({'key1', 'key2'})) # mget k1 k2 k3 32 33 #11、getset(name, value) 设置新值并获取原来的值 34 print(r.getset('age','100')) # getset name tom 35 36 #12、getrange(key, start, end) 下面例子就是获取name值abcdef切片的0-2间的字符(b'abc') 37 r.set('name','abcdef') 38 print(r.getrange('name',0,2)) 39 40 #13、setbit(name, offset, value) #对name对应值的二进制表示的位进行操作 41 r.set('name','abcdef') 42 r.setbit('name',6,1) #将a(1100001)的第二位值改成1,就变成了c(1100011) 43 print(r.get('name')) #最后打印结果:b'cbcdef' 44 45 #14、bitcount(key, start=None, end=None) 获取name对应的值的二进制表示中 1 的个数 46 47 #15、incr(self,name,amount=1) 自增 name对应的值,当name不存在时,则创建name=amount,否则自增 48 49 #16、derc 自动减1:利用incr和derc可以简单统计用户在线数量 50 #如果以前有count就在以前基础加1,没有就第一次就是1,以后每运行一次就自动加1 51 num = r.incr('count') 52 53 #17、num = r.decr('count') #每运行一次就自动减1 54 #每运行一次incr('count')num值加1每运行一次decr后num值减1 55 print(num) 56 57 #18、append(key, value) 在redis name对应的值后面追加内容 58 r.set('name','aaaa') 59 r.append('name','bbbb') 60 print(r.get('name')) #运行结果: b'aaaabbbb'
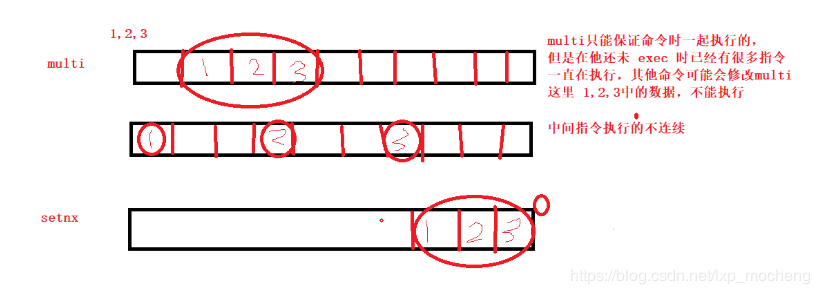
7.redis集群实现秒杀和解决超卖问题
redis命令:https://www.cnblogs.com/xiaonq/p/7919111.html
redis解决超卖问题:https://www.cnblogs.com/xiaonq/p/12328934.html
8.集成支付宝、微信、银联等进行聚合支付(怎么保证接口安全)
支付宝支付:https://www.cnblogs.com/xiaonq/p/12332990.html
- 相关的资源:appid、支付宝公钥、app公钥、app私钥、django环境
- 流程
生成公钥(app公钥、app私钥)
APP的公钥要上传到沙箱环境,然后我们要下载支付宝公钥
- 代码如何实现
第一:生成支付的url
在电脑本地生成公钥、私钥(app公钥、app私钥)
APP的公钥要上传到沙箱环境,然后我们要下载支付宝公钥
提供(实例化Alipay对象):appid、支付宝公钥、app私钥
提供(拼接付款的url):订单id、金额、标题、return_url(付款成功的回调接口)、notify_url(付款成功后的异步通知)
第二:主动查询支付结果
提供(实例化Alipay对象):appid、支付宝公钥、app私钥
提供一个 订单id就可以查询当前订单支付结果
- 支付宝是如何保证数据安全的(数据传输如何保证安全)
9.课程加入路径celery触发更新提醒
- celery原理

- celery应用场景
异步任务
发邮件、发送消息
自动化工单中耗时任务
所有需要异步处理的请求都可以
定时任务
工单系统定时获取超时工单进行延时报警
对过期会员进行清理
- celery的场景(生产者消费者)可以使用多线程解决吗
前端发送一个请求,执行自动化工单需要半个小时,这时候如果使用多线程页面会等待吗?
10.进程
- 进程
https://www.cnblogs.com/xiaonq/p/7905347.html#i3
进程是资源分配的最小单位( 内存、cpu、网络、io)
一个运行起来的程序就是一个进程
什么是程序(程序是我们存储在硬盘里的代码)
硬盘(256G)、内存条(8G)
当我们双击图标,打开程序的时候,实际上就是通过I/O操作(读写)内存条里面
内存条就是我们所指的资源
CPU分时
CPU比你的手速快多了,分时处理每个线程,但是由于太快然你觉得每个线程都是独占cpu
cpu是计算,只有时间片到了,获取cpu,线程真正执行
当你想使用 网络、磁盘等资源的时候,需要cpu的调度
进程具有独立的内存空间,所以没有办法相互通信
进程如何通信
进程queue
pipe
managers
RabbitMQ、redis等
为什么需要进程池
一次性开启指定数量的进程
如果有十个进程,有一百个任务,一次可以处理多少个(一次性只能处理十个)
防止进程开启数量过多导致服务器压力过大
11.线程
- 有了进程为什么还需要线程
因为进程不能同一时间只能做一个事情
- 什么是线程
线程是操作系统调度的最小单位
线程是进程正真的执行者,是一些指令的集合(进程资源的拥有者)
同一个进程下的读多个线程共享内存空间,数据直接访问(数据共享)
为了保证数据安全,必须使用线程锁
- GIL全局解释器锁
在python全局解释器下,保证同一时间只有一个线程运行
防止多个线程都修改数据
- 线程锁(互斥锁)
GIL锁只能保证同一时间只能有一个线程对某个资源操作,但当上一个线程还未执行完毕时可能就会释放GIL,其他线程就可以操作了
线程锁本质把线程中的数据加了一把互斥锁
mysql中共享锁 & 互斥锁
mysql共享锁:共享锁,所有线程都能读,而不能写
mysql排它锁:排它,任何线程读取这个这个数据的权利都没有
加上线程锁之后所有其他线程,读都不能读这个数据
有了GIL全局解释器锁为什么还需要线程锁
因为cpu是分时使用的
- 死锁定义
两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去
12.协程
- 什么是协程
协程微线程,纤程,本质是一个单线程
协程能在单线程处理高并发
线程遇到I/O操作会等待、阻塞,协程遇到I/O会自动切换(剩下的只有CPU操作)
线程的状态保存在CPU的寄存器和栈里而协程拥有自己的空间,所以无需上下文切换的开销,所以快、
为甚么协程能够遇到I/O自动切换
协程有一个gevent模块(封装了greenlet模块),遇到I/O自动切换
- 协程缺点
无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上
线程阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
13.select、epool、pool
https://www.cnblogs.com/xiaonq/p/7907871.html
- I/O的实质是什么?
I/O的实质是将硬盘中的数据,或收到的数据实现从内核态 copy到 用户态的过程
本文讨论的背景是Linux环境下的network IO。
比如微信读取本地硬盘的过程
微信进程会发送一个读取硬盘的请求----》操作系统
只有内核才能够读取硬盘中的数据—》数据返回给微信程序(看上去就好像是微信直接读取)
- 用户态 & 内核态
系统空间分为两个部分,一部分是内核态,一部分是用户态的部分
内核态:内核态的空间资源只有操作系统能够访问
用户态:我们写的普通程序使用的空间
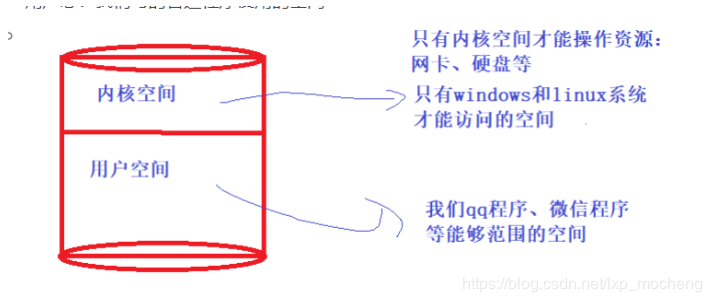
- select
只能处理1024个连接(每一个请求都可以理解为一个连接)
不能告诉用户程序,哪一个连接是活跃的
- pool
只是取消了最大1024个活跃的限制
不能告诉用户程序,哪一个连接是活跃的
- epool
不仅取消了1024这个最大连接限制
而且能告诉用户程序哪一个是活跃的
