首先这个网站存在反爬机制,第二,这个是以post的形式传入的,爬取这2点都有难度
我这里直接贴代码,有注释
import requests
import xlwt
from lxml import etree
import re
from fake_useragent import UserAgent
ua = UserAgent()
url='https://www.cnvd.org.cn/flaw/list.htm?flag=true'
headers = {
"User-Agent": ua.random,
}
resp = requests.post(url, data={'max': 20, 'offset': 0, 'keyword': 'office', 'condition': 1, 'baseinfoBeanbeginTime': '2016-01-01', 'baseinfoBeanendTime': '2020-08-26', 'referenceScope': 1, 'manufacturerId': -1, 'categoryId': -1, 'editionId': -1, 'baseinfoBeanFlag': 0, 'keywordFlag': 0, 'cnvdIdFlag': 0}, headers=headers) #post传参内容
text =resp.text
urlhref = re.findall(r'href="/flaw/show(.*?)"', text)
domain = "https://www.cnvd.org.cn/flaw/show"
for urlhrefs in urlhref:
aas = domain + urlhrefs #此段url为真实的url,需要上一段代码提取cnvd的编号与domain的网端组成真正需要爬取的url
resps = requests.get(aas, headers=headers)
texts = resps.text
html = etree.HTML(texts)
title = html.xpath("//div[@class='blkContainerSblk']//h1/text()")
CVE = re.findall(r'target="_blank">(.*?) </a><br>', texts) #用正则爬取
CNVD = html.xpath("normalize-space(//table[@class='gg_detail']//tr[1]/td[2]/text())")
shijian = html.xpath("normalize-space(//table[@class='gg_detail']//tr[2]/td[2]/text())")
product = html.xpath("normalize-space(//table[@class='gg_detail']//tr[4]/td[2]/text())")
miaosu = html.xpath("normalize-space(//table[@class='gg_detail']/tbody/tr[6]/td[2]//text())")
leixing = html.xpath("normalize-space(//table[@class='gg_detail']//tr[7]/td[2]/text())")
print(miaosu)
对于反爬机制,我们可以用随机ua,也可以用代理ip,关于爬取代理ip,我上一篇文章有源码,也可以将header里面的内容增多,将线程变为单线程
https://www.cnblogs.com/xinxin999/p/13418524.html
爬取cnvd,需要注意的是他post里面的参数keywords是关键词,max是一页最大的内容,我现在设置的是20篇,最大可以是100.offset是位移量,比如你设置的max为20,你想要爬取5页,offset就设为100.
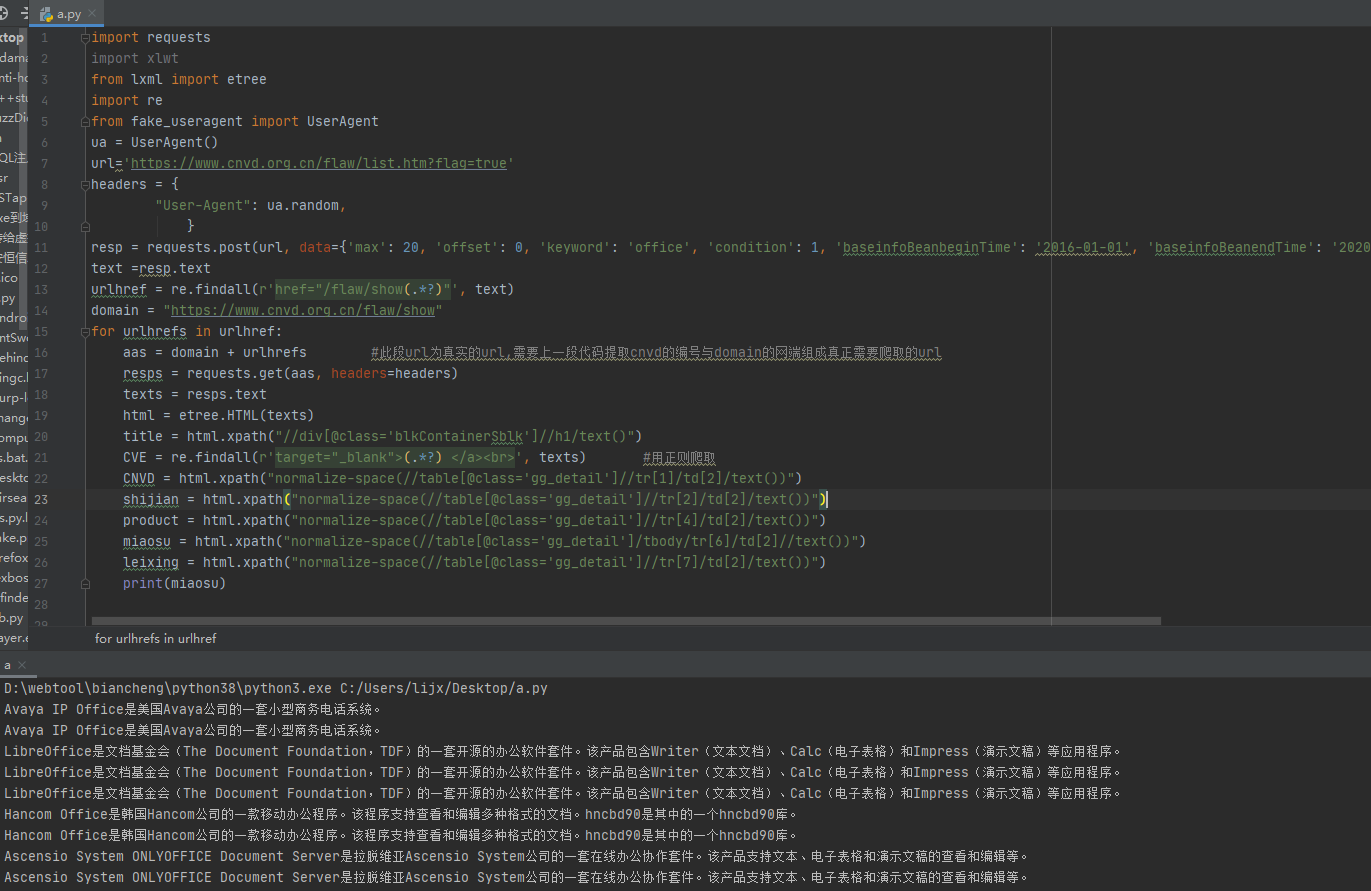
这里只截了部分图,数据处理各位兄弟们自行完善。