线性数据结构
- 我们从四个简单但重要的概念开始研究数据结构。栈,队列,deques(双向队列), 列表是一类数据的容器,它们数据元素之间的顺序由添加或删除的顺序决定。一旦一个数据元素被添加,它相对于前后元素一直保持该位置不变。诸如此类的数据结构被称为线性数据结构。
- 线性数据结构有两端,有时被称为左右,某些情况被称为前后。你也可以称为顶部和底部,名字都不重要。将两个线性数据结构区分开的方法是添加和移除元素的方式,特别是添加和移除元素的位置。例如一些结构允许从一端添加元素,另一些允许从另一端移除元素。
栈
- 概念:栈(有时称为“后进先出栈”)是一个元素的有序集合,其中添加移除新元素总发生在同一端。这一端通常称为“顶部”。与顶部对应的端称为“底部”。栈的底部很重要,因为在栈中靠近底部的元素是存储时间最长的。最近添加的元素是最先会被移除的。这种排序原则有时被称为 LIFO,后进先出。它基于在集合内的时间长度做排序。较新的项靠近顶部,较旧的项靠近底部。
- 案例:栈的例子很常见。几乎所有的自助餐厅都有一堆托盘或盘子,你从顶部拿一个,就会有一个新的托盘给下一个客人。想象桌上有一堆书, 只有顶部的那本书封面可见,要看到其他书的封面,只有先移除他们上面的书。下图展示了另一个栈,包含了很多 Python 对象。
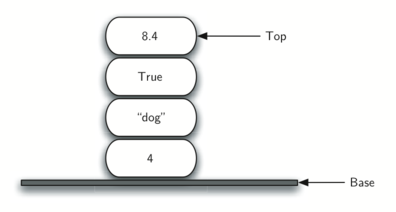
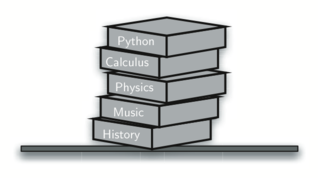
栈的分析与应用
- 分析:和栈相关的最有用的想法之一来自对它的观察。假设从一个干净的桌面开始,现在把书一本本叠起来,你在构造一个栈。考虑下移除一本书会发生什么。移除的顺序跟刚刚被放置的顺序相反。栈之所以重要是因为它能反转项的顺序。插入跟删除顺序相反。
- 应用:每个 web 浏览器都有一个返回按钮。当你浏览网页时,这些网页被放置在一个栈中(实际是网页的网址)。你现在查看的网页在顶部,你第一个查看的网页在底部。如果按‘返回’按钮,将按相反的顺序浏览刚才的页面。
python实现栈
- 栈的抽象数据类型定义:栈的抽象数据类型应该由以下结构和操作定义。栈操作如下:
Stack() 创建一个空的新栈。 它不需要参数,并返回一个空栈。 push(item)将一个新项添加到栈的顶部。它需要 item 做参数并不返回任何内容。 pop() 从栈中删除顶部项。它不需要参数并返回 item 。栈被修改。 peek() 从栈返回顶部项,但不会删除它。不需要参数。 不修改栈。 isEmpty() 测试栈是否为空。不需要参数,并返回布尔值。 size() 返回栈中的 item 数量。不需要参数,并返回一个整数。
- 代码实现:Python 中的列表类提供了有序集合机制和一组方法。例如,如果我们有列表 [2,5,3,6,7,4],我们只需要确定列表的哪一端将被认为是栈的顶部。一旦确定,可以使用诸如 append 和 pop 的列表方法来实现操作。
class Stack():
def __init__(self):
self.items = []
def push(self,item):
self.items.append(item)
def pop(self):
if self.isEmpty():
return '空'
else:
return self.items.pop()
def isEmpty(self):
#空=》True
return self.items == []
def peek(self):
return self.items[len(self.items) - 1]
def size(self):
return len(self.items)
应用:
stack = Stack() stack.push(1) stack.push(2) stack.push(3) print(stack.size()) print(stack.pop()) print(stack.pop()) print(stack.pop()) print(stack.pop()) print(stack.peek()) 3 3 2 1 空
案例2:
s = Stack()
#模拟浏览器回退按钮
def getRequest(url):
s.push(url)
def showCurrentPage():
print(s.pop())
def back():
return s.pop()
getRequest('www.1.com')
getRequest('www.2.com')
getRequest('www.3.com')
showCurrentPage()
print(back())
print(back())
执行结果:
www.3.com
www.2.com
www.1.com