写在前面的话:读书破万卷,编码如有神
----------------------------------------------------------------------------------------
1、手工创建集群
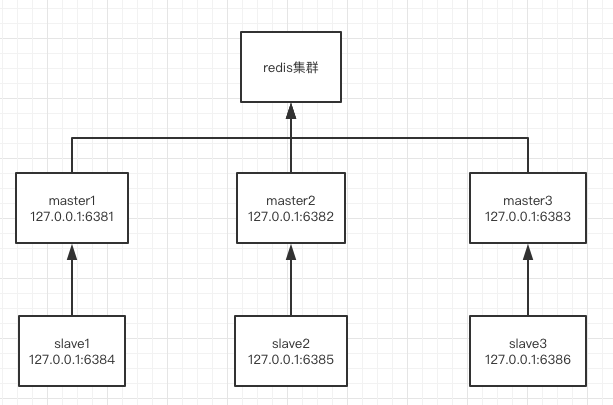
需要搭建的redis集群如下图所示:
1.1、首先进行集群配置
(1)拷贝redis.conf文件6份,分别命名为:redis6381.conf、redis6382.conf、redis6383.conf、redis6384.conf、redis6385.conf、redis6386.conf
(2)只需要将每个数据库配置文件中的cluster-enable配置选项打开,然后再修改如下内容:pidfile、port、logfile、dbfilename、cluster-config-file
redis6381.conf 具体的配置如下:


1 # Redis configuration file example. 2 # 3 # Note that in order to read the configuration file, Redis must be 4 # started with the file path as first argument: 5 # 6 # ./redis-server /path/to/redis.conf 7 8 # Note on units: when memory size is needed, it is possible to specify 9 # it in the usual form of 1k 5GB 4M and so forth: 10 # 11 # 1k => 1000 bytes 12 # 1kb => 1024 bytes 13 # 1m => 1000000 bytes 14 # 1mb => 1024*1024 bytes 15 # 1g => 1000000000 bytes 16 # 1gb => 1024*1024*1024 bytes 17 # 18 # units are case insensitive so 1GB 1Gb 1gB are all the same. 19 20 ################################## INCLUDES ################################### 21 22 # Include one or more other config files here. This is useful if you 23 # have a standard template that goes to all Redis servers but also need 24 # to customize a few per-server settings. Include files can include 25 # other files, so use this wisely. 26 # 27 # Notice option "include" won't be rewritten by command "CONFIG REWRITE" 28 # from admin or Redis Sentinel. Since Redis always uses the last processed 29 # line as value of a configuration directive, you'd better put includes 30 # at the beginning of this file to avoid overwriting config change at runtime. 31 # 32 # If instead you are interested in using includes to override configuration 33 # options, it is better to use include as the last line. 34 # 35 # include /path/to/local.conf 36 # include /path/to/other.conf 37 38 ################################## MODULES ##################################### 39 40 # Load modules at startup. If the server is not able to load modules 41 # it will abort. It is possible to use multiple loadmodule directives. 42 # 43 # loadmodule /path/to/my_module.so 44 # loadmodule /path/to/other_module.so 45 46 ################################## NETWORK ##################################### 47 48 # By default, if no "bind" configuration directive is specified, Redis listens 49 # for connections from all the network interfaces available on the server. 50 # It is possible to listen to just one or multiple selected interfaces using 51 # the "bind" configuration directive, followed by one or more IP addresses. 52 # 53 # Examples: 54 # 55 # bind 192.168.1.100 10.0.0.1 56 # bind 127.0.0.1 ::1 57 # 58 # ~~~ WARNING ~~~ If the computer running Redis is directly exposed to the 59 # internet, binding to all the interfaces is dangerous and will expose the 60 # instance to everybody on the internet. So by default we uncomment the 61 # following bind directive, that will force Redis to listen only into 62 # the IPv4 lookback interface address (this means Redis will be able to 63 # accept connections only from clients running into the same computer it 64 # is running). 65 # 66 # IF YOU ARE SURE YOU WANT YOUR INSTANCE TO LISTEN TO ALL THE INTERFACES 67 # JUST COMMENT THE FOLLOWING LINE. 68 # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ 69 bind 127.0.0.1 70 71 # Protected mode is a layer of security protection, in order to avoid that 72 # Redis instances left open on the internet are accessed and exploited. 73 # 74 # When protected mode is on and if: 75 # 76 # 1) The server is not binding explicitly to a set of addresses using the 77 # "bind" directive. 78 # 2) No password is configured. 79 # 80 # The server only accepts connections from clients connecting from the 81 # IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain 82 # sockets. 83 # 84 # By default protected mode is enabled. You should disable it only if 85 # you are sure you want clients from other hosts to connect to Redis 86 # even if no authentication is configured, nor a specific set of interfaces 87 # are explicitly listed using the "bind" directive. 88 protected-mode yes 89 90 # Accept connections on the specified port, default is 6379 (IANA #815344). 91 # If port 0 is specified Redis will not listen on a TCP socket. 92 port 6381 93 94 # TCP listen() backlog. 95 # 96 # In high requests-per-second environments you need an high backlog in order 97 # to avoid slow clients connections issues. Note that the Linux kernel 98 # will silently truncate it to the value of /proc/sys/net/core/somaxconn so 99 # make sure to raise both the value of somaxconn and tcp_max_syn_backlog 100 # in order to get the desired effect. 101 tcp-backlog 511 102 103 # Unix socket. 104 # 105 # Specify the path for the Unix socket that will be used to listen for 106 # incoming connections. There is no default, so Redis will not listen 107 # on a unix socket when not specified. 108 # 109 # unixsocket /tmp/redis.sock 110 # unixsocketperm 700 111 112 # Close the connection after a client is idle for N seconds (0 to disable) 113 timeout 0 114 115 # TCP keepalive. 116 # 117 # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence 118 # of communication. This is useful for two reasons: 119 # 120 # 1) Detect dead peers. 121 # 2) Take the connection alive from the point of view of network 122 # equipment in the middle. 123 # 124 # On Linux, the specified value (in seconds) is the period used to send ACKs. 125 # Note that to close the connection the double of the time is needed. 126 # On other kernels the period depends on the kernel configuration. 127 # 128 # A reasonable value for this option is 300 seconds, which is the new 129 # Redis default starting with Redis 3.2.1. 130 tcp-keepalive 300 131 132 ################################# GENERAL ##################################### 133 134 # By default Redis does not run as a daemon. Use 'yes' if you need it. 135 # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. 136 daemonize yes 137 138 # If you run Redis from upstart or systemd, Redis can interact with your 139 # supervision tree. Options: 140 # supervised no - no supervision interaction 141 # supervised upstart - signal upstart by putting Redis into SIGSTOP mode 142 # supervised systemd - signal systemd by writing READY=1 to $NOTIFY_SOCKET 143 # supervised auto - detect upstart or systemd method based on 144 # UPSTART_JOB or NOTIFY_SOCKET environment variables 145 # Note: these supervision methods only signal "process is ready." 146 # They do not enable continuous liveness pings back to your supervisor. 147 supervised no 148 149 # If a pid file is specified, Redis writes it where specified at startup 150 # and removes it at exit. 151 # 152 # When the server runs non daemonized, no pid file is created if none is 153 # specified in the configuration. When the server is daemonized, the pid file 154 # is used even if not specified, defaulting to "/var/run/redis.pid". 155 # 156 # Creating a pid file is best effort: if Redis is not able to create it 157 # nothing bad happens, the server will start and run normally. 158 pidfile /var/run/redis_6381.pid 159 160 # Specify the server verbosity level. 161 # This can be one of: 162 # debug (a lot of information, useful for development/testing) 163 # verbose (many rarely useful info, but not a mess like the debug level) 164 # notice (moderately verbose, what you want in production probably) 165 # warning (only very important / critical messages are logged) 166 loglevel notice 167 168 # Specify the log file name. Also the empty string can be used to force 169 # Redis to log on the standard output. Note that if you use standard 170 # output for logging but daemonize, logs will be sent to /dev/null 171 logfile "redis_6381.log" 172 173 # To enable logging to the system logger, just set 'syslog-enabled' to yes, 174 # and optionally update the other syslog parameters to suit your needs. 175 # syslog-enabled no 176 177 # Specify the syslog identity. 178 # syslog-ident redis 179 180 # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. 181 # syslog-facility local0 182 183 # Set the number of databases. The default database is DB 0, you can select 184 # a different one on a per-connection basis using SELECT <dbid> where 185 # dbid is a number between 0 and 'databases'-1 186 databases 16 187 188 # By default Redis shows an ASCII art logo only when started to log to the 189 # standard output and if the standard output is a TTY. Basically this means 190 # that normally a logo is displayed only in interactive sessions. 191 # 192 # However it is possible to force the pre-4.0 behavior and always show a 193 # ASCII art logo in startup logs by setting the following option to yes. 194 always-show-logo yes 195 196 ################################ SNAPSHOTTING ################################ 197 # 198 # Save the DB on disk: 199 # 200 # save <seconds> <changes> 201 # 202 # Will save the DB if both the given number of seconds and the given 203 # number of write operations against the DB occurred. 204 # 205 # In the example below the behaviour will be to save: 206 # after 900 sec (15 min) if at least 1 key changed 207 # after 300 sec (5 min) if at least 10 keys changed 208 # after 60 sec if at least 10000 keys changed 209 # 210 # Note: you can disable saving completely by commenting out all "save" lines. 211 # 212 # It is also possible to remove all the previously configured save 213 # points by adding a save directive with a single empty string argument 214 # like in the following example: 215 # 216 # save "" 217 218 save 900 1 219 save 300 10 220 save 60 10000 221 222 # By default Redis will stop accepting writes if RDB snapshots are enabled 223 # (at least one save point) and the latest background save failed. 224 # This will make the user aware (in a hard way) that data is not persisting 225 # on disk properly, otherwise chances are that no one will notice and some 226 # disaster will happen. 227 # 228 # If the background saving process will start working again Redis will 229 # automatically allow writes again. 230 # 231 # However if you have setup your proper monitoring of the Redis server 232 # and persistence, you may want to disable this feature so that Redis will 233 # continue to work as usual even if there are problems with disk, 234 # permissions, and so forth. 235 stop-writes-on-bgsave-error yes 236 237 # Compress string objects using LZF when dump .rdb databases? 238 # For default that's set to 'yes' as it's almost always a win. 239 # If you want to save some CPU in the saving child set it to 'no' but 240 # the dataset will likely be bigger if you have compressible values or keys. 241 rdbcompression yes 242 243 # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. 244 # This makes the format more resistant to corruption but there is a performance 245 # hit to pay (around 10%) when saving and loading RDB files, so you can disable it 246 # for maximum performances. 247 # 248 # RDB files created with checksum disabled have a checksum of zero that will 249 # tell the loading code to skip the check. 250 rdbchecksum yes 251 252 # The filename where to dump the DB 253 dbfilename dump_6381.rdb 254 255 # The working directory. 256 # 257 # The DB will be written inside this directory, with the filename specified 258 # above using the 'dbfilename' configuration directive. 259 # 260 # The Append Only File will also be created inside this directory. 261 # 262 # Note that you must specify a directory here, not a file name. 263 dir ./ 264 265 ################################# REPLICATION ################################# 266 267 # Master-Slave replication. Use slaveof to make a Redis instance a copy of 268 # another Redis server. A few things to understand ASAP about Redis replication. 269 # 270 # 1) Redis replication is asynchronous, but you can configure a master to 271 # stop accepting writes if it appears to be not connected with at least 272 # a given number of slaves. 273 # 2) Redis slaves are able to perform a partial resynchronization with the 274 # master if the replication link is lost for a relatively small amount of 275 # time. You may want to configure the replication backlog size (see the next 276 # sections of this file) with a sensible value depending on your needs. 277 # 3) Replication is automatic and does not need user intervention. After a 278 # network partition slaves automatically try to reconnect to masters 279 # and resynchronize with them. 280 # 281 # slaveof <masterip> <masterport> 282 283 # If the master is password protected (using the "requirepass" configuration 284 # directive below) it is possible to tell the slave to authenticate before 285 # starting the replication synchronization process, otherwise the master will 286 # refuse the slave request. 287 # 288 # masterauth <master-password> 289 290 # When a slave loses its connection with the master, or when the replication 291 # is still in progress, the slave can act in two different ways: 292 # 293 # 1) if slave-serve-stale-data is set to 'yes' (the default) the slave will 294 # still reply to client requests, possibly with out of date data, or the 295 # data set may just be empty if this is the first synchronization. 296 # 297 # 2) if slave-serve-stale-data is set to 'no' the slave will reply with 298 # an error "SYNC with master in progress" to all the kind of commands 299 # but to INFO and SLAVEOF. 300 # 301 slave-serve-stale-data yes 302 303 # You can configure a slave instance to accept writes or not. Writing against 304 # a slave instance may be useful to store some ephemeral data (because data 305 # written on a slave will be easily deleted after resync with the master) but 306 # may also cause problems if clients are writing to it because of a 307 # misconfiguration. 308 # 309 # Since Redis 2.6 by default slaves are read-only. 310 # 311 # Note: read only slaves are not designed to be exposed to untrusted clients 312 # on the internet. It's just a protection layer against misuse of the instance. 313 # Still a read only slave exports by default all the administrative commands 314 # such as CONFIG, DEBUG, and so forth. To a limited extent you can improve 315 # security of read only slaves using 'rename-command' to shadow all the 316 # administrative / dangerous commands. 317 slave-read-only yes 318 319 # Replication SYNC strategy: disk or socket. 320 # 321 # ------------------------------------------------------- 322 # WARNING: DISKLESS REPLICATION IS EXPERIMENTAL CURRENTLY 323 # ------------------------------------------------------- 324 # 325 # New slaves and reconnecting slaves that are not able to continue the replication 326 # process just receiving differences, need to do what is called a "full 327 # synchronization". An RDB file is transmitted from the master to the slaves. 328 # The transmission can happen in two different ways: 329 # 330 # 1) Disk-backed: The Redis master creates a new process that writes the RDB 331 # file on disk. Later the file is transferred by the parent 332 # process to the slaves incrementally. 333 # 2) Diskless: The Redis master creates a new process that directly writes the 334 # RDB file to slave sockets, without touching the disk at all. 335 # 336 # With disk-backed replication, while the RDB file is generated, more slaves 337 # can be queued and served with the RDB file as soon as the current child producing 338 # the RDB file finishes its work. With diskless replication instead once 339 # the transfer starts, new slaves arriving will be queued and a new transfer 340 # will start when the current one terminates. 341 # 342 # When diskless replication is used, the master waits a configurable amount of 343 # time (in seconds) before starting the transfer in the hope that multiple slaves 344 # will arrive and the transfer can be parallelized. 345 # 346 # With slow disks and fast (large bandwidth) networks, diskless replication 347 # works better. 348 repl-diskless-sync no 349 350 # When diskless replication is enabled, it is possible to configure the delay 351 # the server waits in order to spawn the child that transfers the RDB via socket 352 # to the slaves. 353 # 354 # This is important since once the transfer starts, it is not possible to serve 355 # new slaves arriving, that will be queued for the next RDB transfer, so the server 356 # waits a delay in order to let more slaves arrive. 357 # 358 # The delay is specified in seconds, and by default is 5 seconds. To disable 359 # it entirely just set it to 0 seconds and the transfer will start ASAP. 360 repl-diskless-sync-delay 5 361 362 # Slaves send PINGs to server in a predefined interval. It's possible to change 363 # this interval with the repl_ping_slave_period option. The default value is 10 364 # seconds. 365 # 366 # repl-ping-slave-period 10 367 368 # The following option sets the replication timeout for: 369 # 370 # 1) Bulk transfer I/O during SYNC, from the point of view of slave. 371 # 2) Master timeout from the point of view of slaves (data, pings). 372 # 3) Slave timeout from the point of view of masters (REPLCONF ACK pings). 373 # 374 # It is important to make sure that this value is greater than the value 375 # specified for repl-ping-slave-period otherwise a timeout will be detected 376 # every time there is low traffic between the master and the slave. 377 # 378 # repl-timeout 60 379 380 # Disable TCP_NODELAY on the slave socket after SYNC? 381 # 382 # If you select "yes" Redis will use a smaller number of TCP packets and 383 # less bandwidth to send data to slaves. But this can add a delay for 384 # the data to appear on the slave side, up to 40 milliseconds with 385 # Linux kernels using a default configuration. 386 # 387 # If you select "no" the delay for data to appear on the slave side will 388 # be reduced but more bandwidth will be used for replication. 389 # 390 # By default we optimize for low latency, but in very high traffic conditions 391 # or when the master and slaves are many hops away, turning this to "yes" may 392 # be a good idea. 393 repl-disable-tcp-nodelay no 394 395 # Set the replication backlog size. The backlog is a buffer that accumulates 396 # slave data when slaves are disconnected for some time, so that when a slave 397 # wants to reconnect again, often a full resync is not needed, but a partial 398 # resync is enough, just passing the portion of data the slave missed while 399 # disconnected. 400 # 401 # The bigger the replication backlog, the longer the time the slave can be 402 # disconnected and later be able to perform a partial resynchronization. 403 # 404 # The backlog is only allocated once there is at least a slave connected. 405 # 406 # repl-backlog-size 1mb 407 408 # After a master has no longer connected slaves for some time, the backlog 409 # will be freed. The following option configures the amount of seconds that 410 # need to elapse, starting from the time the last slave disconnected, for 411 # the backlog buffer to be freed. 412 # 413 # Note that slaves never free the backlog for timeout, since they may be 414 # promoted to masters later, and should be able to correctly "partially 415 # resynchronize" with the slaves: hence they should always accumulate backlog. 416 # 417 # A value of 0 means to never release the backlog. 418 # 419 # repl-backlog-ttl 3600 420 421 # The slave priority is an integer number published by Redis in the INFO output. 422 # It is used by Redis Sentinel in order to select a slave to promote into a 423 # master if the master is no longer working correctly. 424 # 425 # A slave with a low priority number is considered better for promotion, so 426 # for instance if there are three slaves with priority 10, 100, 25 Sentinel will 427 # pick the one with priority 10, that is the lowest. 428 # 429 # However a special priority of 0 marks the slave as not able to perform the 430 # role of master, so a slave with priority of 0 will never be selected by 431 # Redis Sentinel for promotion. 432 # 433 # By default the priority is 100. 434 slave-priority 100 435 436 # It is possible for a master to stop accepting writes if there are less than 437 # N slaves connected, having a lag less or equal than M seconds. 438 # 439 # The N slaves need to be in "online" state. 440 # 441 # The lag in seconds, that must be <= the specified value, is calculated from 442 # the last ping received from the slave, that is usually sent every second. 443 # 444 # This option does not GUARANTEE that N replicas will accept the write, but 445 # will limit the window of exposure for lost writes in case not enough slaves 446 # are available, to the specified number of seconds. 447 # 448 # For example to require at least 3 slaves with a lag <= 10 seconds use: 449 # 450 # min-slaves-to-write 3 451 # min-slaves-max-lag 10 452 # 453 # Setting one or the other to 0 disables the feature. 454 # 455 # By default min-slaves-to-write is set to 0 (feature disabled) and 456 # min-slaves-max-lag is set to 10. 457 458 # A Redis master is able to list the address and port of the attached 459 # slaves in different ways. For example the "INFO replication" section 460 # offers this information, which is used, among other tools, by 461 # Redis Sentinel in order to discover slave instances. 462 # Another place where this info is available is in the output of the 463 # "ROLE" command of a master. 464 # 465 # The listed IP and address normally reported by a slave is obtained 466 # in the following way: 467 # 468 # IP: The address is auto detected by checking the peer address 469 # of the socket used by the slave to connect with the master. 470 # 471 # Port: The port is communicated by the slave during the replication 472 # handshake, and is normally the port that the slave is using to 473 # list for connections. 474 # 475 # However when port forwarding or Network Address Translation (NAT) is 476 # used, the slave may be actually reachable via different IP and port 477 # pairs. The following two options can be used by a slave in order to 478 # report to its master a specific set of IP and port, so that both INFO 479 # and ROLE will report those values. 480 # 481 # There is no need to use both the options if you need to override just 482 # the port or the IP address. 483 # 484 # slave-announce-ip 5.5.5.5 485 # slave-announce-port 1234 486 487 ################################## SECURITY ################################### 488 489 # Require clients to issue AUTH <PASSWORD> before processing any other 490 # commands. This might be useful in environments in which you do not trust 491 # others with access to the host running redis-server. 492 # 493 # This should stay commented out for backward compatibility and because most 494 # people do not need auth (e.g. they run their own servers). 495 # 496 # Warning: since Redis is pretty fast an outside user can try up to 497 # 150k passwords per second against a good box. This means that you should 498 # use a very strong password otherwise it will be very easy to break. 499 # 500 # requirepass foobared 501 502 # Command renaming. 503 # 504 # It is possible to change the name of dangerous commands in a shared 505 # environment. For instance the CONFIG command may be renamed into something 506 # hard to guess so that it will still be available for internal-use tools 507 # but not available for general clients. 508 # 509 # Example: 510 # 511 # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 512 # 513 # It is also possible to completely kill a command by renaming it into 514 # an empty string: 515 # 516 # rename-command CONFIG "" 517 # 518 # Please note that changing the name of commands that are logged into the 519 # AOF file or transmitted to slaves may cause problems. 520 521 ################################### CLIENTS #################################### 522 523 # Set the max number of connected clients at the same time. By default 524 # this limit is set to 10000 clients, however if the Redis server is not 525 # able to configure the process file limit to allow for the specified limit 526 # the max number of allowed clients is set to the current file limit 527 # minus 32 (as Redis reserves a few file descriptors for internal uses). 528 # 529 # Once the limit is reached Redis will close all the new connections sending 530 # an error 'max number of clients reached'. 531 # 532 # maxclients 10000 533 534 ############################## MEMORY MANAGEMENT ################################ 535 536 # Set a memory usage limit to the specified amount of bytes. 537 # When the memory limit is reached Redis will try to remove keys 538 # according to the eviction policy selected (see maxmemory-policy). 539 # 540 # If Redis can't remove keys according to the policy, or if the policy is 541 # set to 'noeviction', Redis will start to reply with errors to commands 542 # that would use more memory, like SET, LPUSH, and so on, and will continue 543 # to reply to read-only commands like GET. 544 # 545 # This option is usually useful when using Redis as an LRU or LFU cache, or to 546 # set a hard memory limit for an instance (using the 'noeviction' policy). 547 # 548 # WARNING: If you have slaves attached to an instance with maxmemory on, 549 # the size of the output buffers needed to feed the slaves are subtracted 550 # from the used memory count, so that network problems / resyncs will 551 # not trigger a loop where keys are evicted, and in turn the output 552 # buffer of slaves is full with DELs of keys evicted triggering the deletion 553 # of more keys, and so forth until the database is completely emptied. 554 # 555 # In short... if you have slaves attached it is suggested that you set a lower 556 # limit for maxmemory so that there is some free RAM on the system for slave 557 # output buffers (but this is not needed if the policy is 'noeviction'). 558 # 559 # maxmemory <bytes> 560 561 # MAXMEMORY POLICY: how Redis will select what to remove when maxmemory 562 # is reached. You can select among five behaviors: 563 # 564 # volatile-lru -> Evict using approximated LRU among the keys with an expire set. 565 # allkeys-lru -> Evict any key using approximated LRU. 566 # volatile-lfu -> Evict using approximated LFU among the keys with an expire set. 567 # allkeys-lfu -> Evict any key using approximated LFU. 568 # volatile-random -> Remove a random key among the ones with an expire set. 569 # allkeys-random -> Remove a random key, any key. 570 # volatile-ttl -> Remove the key with the nearest expire time (minor TTL) 571 # noeviction -> Don't evict anything, just return an error on write operations. 572 # 573 # LRU means Least Recently Used 574 # LFU means Least Frequently Used 575 # 576 # Both LRU, LFU and volatile-ttl are implemented using approximated 577 # randomized algorithms. 578 # 579 # Note: with any of the above policies, Redis will return an error on write 580 # operations, when there are no suitable keys for eviction. 581 # 582 # At the date of writing these commands are: set setnx setex append 583 # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd 584 # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby 585 # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby 586 # getset mset msetnx exec sort 587 # 588 # The default is: 589 # 590 # maxmemory-policy noeviction 591 592 # LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated 593 # algorithms (in order to save memory), so you can tune it for speed or 594 # accuracy. For default Redis will check five keys and pick the one that was 595 # used less recently, you can change the sample size using the following 596 # configuration directive. 597 # 598 # The default of 5 produces good enough results. 10 Approximates very closely 599 # true LRU but costs more CPU. 3 is faster but not very accurate. 600 # 601 # maxmemory-samples 5 602 603 ############################# LAZY FREEING #################################### 604 605 # Redis has two primitives to delete keys. One is called DEL and is a blocking 606 # deletion of the object. It means that the server stops processing new commands 607 # in order to reclaim all the memory associated with an object in a synchronous 608 # way. If the key deleted is associated with a small object, the time needed 609 # in order to execute the DEL command is very small and comparable to most other 610 # O(1) or O(log_N) commands in Redis. However if the key is associated with an 611 # aggregated value containing millions of elements, the server can block for 612 # a long time (even seconds) in order to complete the operation. 613 # 614 # For the above reasons Redis also offers non blocking deletion primitives 615 # such as UNLINK (non blocking DEL) and the ASYNC option of FLUSHALL and 616 # FLUSHDB commands, in order to reclaim memory in background. Those commands 617 # are executed in constant time. Another thread will incrementally free the 618 # object in the background as fast as possible. 619 # 620 # DEL, UNLINK and ASYNC option of FLUSHALL and FLUSHDB are user-controlled. 621 # It's up to the design of the application to understand when it is a good 622 # idea to use one or the other. However the Redis server sometimes has to 623 # delete keys or flush the whole database as a side effect of other operations. 624 # Specifically Redis deletes objects independently of a user call in the 625 # following scenarios: 626 # 627 # 1) On eviction, because of the maxmemory and maxmemory policy configurations, 628 # in order to make room for new data, without going over the specified 629 # memory limit. 630 # 2) Because of expire: when a key with an associated time to live (see the 631 # EXPIRE command) must be deleted from memory. 632 # 3) Because of a side effect of a command that stores data on a key that may 633 # already exist. For example the RENAME command may delete the old key 634 # content when it is replaced with another one. Similarly SUNIONSTORE 635 # or SORT with STORE option may delete existing keys. The SET command 636 # itself removes any old content of the specified key in order to replace 637 # it with the specified string. 638 # 4) During replication, when a slave performs a full resynchronization with 639 # its master, the content of the whole database is removed in order to 640 # load the RDB file just transfered. 641 # 642 # In all the above cases the default is to delete objects in a blocking way, 643 # like if DEL was called. However you can configure each case specifically 644 # in order to instead release memory in a non-blocking way like if UNLINK 645 # was called, using the following configuration directives: 646 647 lazyfree-lazy-eviction no 648 lazyfree-lazy-expire no 649 lazyfree-lazy-server-del no 650 slave-lazy-flush no 651 652 ############################## APPEND ONLY MODE ############################### 653 654 # By default Redis asynchronously dumps the dataset on disk. This mode is 655 # good enough in many applications, but an issue with the Redis process or 656 # a power outage may result into a few minutes of writes lost (depending on 657 # the configured save points). 658 # 659 # The Append Only File is an alternative persistence mode that provides 660 # much better durability. For instance using the default data fsync policy 661 # (see later in the config file) Redis can lose just one second of writes in a 662 # dramatic event like a server power outage, or a single write if something 663 # wrong with the Redis process itself happens, but the operating system is 664 # still running correctly. 665 # 666 # AOF and RDB persistence can be enabled at the same time without problems. 667 # If the AOF is enabled on startup Redis will load the AOF, that is the file 668 # with the better durability guarantees. 669 # 670 # Please check http://redis.io/topics/persistence for more information. 671 672 appendonly no 673 674 # The name of the append only file (default: "appendonly.aof") 675 676 appendfilename "appendonly6381.aof" 677 678 # The fsync() call tells the Operating System to actually write data on disk 679 # instead of waiting for more data in the output buffer. Some OS will really flush 680 # data on disk, some other OS will just try to do it ASAP. 681 # 682 # Redis supports three different modes: 683 # 684 # no: don't fsync, just let the OS flush the data when it wants. Faster. 685 # always: fsync after every write to the append only log. Slow, Safest. 686 # everysec: fsync only one time every second. Compromise. 687 # 688 # The default is "everysec", as that's usually the right compromise between 689 # speed and data safety. It's up to you to understand if you can relax this to 690 # "no" that will let the operating system flush the output buffer when 691 # it wants, for better performances (but if you can live with the idea of 692 # some data loss consider the default persistence mode that's snapshotting), 693 # or on the contrary, use "always" that's very slow but a bit safer than 694 # everysec. 695 # 696 # More details please check the following article: 697 # http://antirez.com/post/redis-persistence-demystified.html 698 # 699 # If unsure, use "everysec". 700 701 # appendfsync always 702 appendfsync everysec 703 # appendfsync no 704 705 # When the AOF fsync policy is set to always or everysec, and a background 706 # saving process (a background save or AOF log background rewriting) is 707 # performing a lot of I/O against the disk, in some Linux configurations 708 # Redis may block too long on the fsync() call. Note that there is no fix for 709 # this currently, as even performing fsync in a different thread will block 710 # our synchronous write(2) call. 711 # 712 # In order to mitigate this problem it's possible to use the following option 713 # that will prevent fsync() from being called in the main process while a 714 # BGSAVE or BGREWRITEAOF is in progress. 715 # 716 # This means that while another child is saving, the durability of Redis is 717 # the same as "appendfsync none". In practical terms, this means that it is 718 # possible to lose up to 30 seconds of log in the worst scenario (with the 719 # default Linux settings). 720 # 721 # If you have latency problems turn this to "yes". Otherwise leave it as 722 # "no" that is the safest pick from the point of view of durability. 723 724 no-appendfsync-on-rewrite no 725 726 # Automatic rewrite of the append only file. 727 # Redis is able to automatically rewrite the log file implicitly calling 728 # BGREWRITEAOF when the AOF log size grows by the specified percentage. 729 # 730 # This is how it works: Redis remembers the size of the AOF file after the 731 # latest rewrite (if no rewrite has happened since the restart, the size of 732 # the AOF at startup is used). 733 # 734 # This base size is compared to the current size. If the current size is 735 # bigger than the specified percentage, the rewrite is triggered. Also 736 # you need to specify a minimal size for the AOF file to be rewritten, this 737 # is useful to avoid rewriting the AOF file even if the percentage increase 738 # is reached but it is still pretty small. 739 # 740 # Specify a percentage of zero in order to disable the automatic AOF 741 # rewrite feature. 742 743 auto-aof-rewrite-percentage 100 744 auto-aof-rewrite-min-size 64mb 745 746 # An AOF file may be found to be truncated at the end during the Redis 747 # startup process, when the AOF data gets loaded back into memory. 748 # This may happen when the system where Redis is running 749 # crashes, especially when an ext4 filesystem is mounted without the 750 # data=ordered option (however this can't happen when Redis itself 751 # crashes or aborts but the operating system still works correctly). 752 # 753 # Redis can either exit with an error when this happens, or load as much 754 # data as possible (the default now) and start if the AOF file is found 755 # to be truncated at the end. The following option controls this behavior. 756 # 757 # If aof-load-truncated is set to yes, a truncated AOF file is loaded and 758 # the Redis server starts emitting a log to inform the user of the event. 759 # Otherwise if the option is set to no, the server aborts with an error 760 # and refuses to start. When the option is set to no, the user requires 761 # to fix the AOF file using the "redis-check-aof" utility before to restart 762 # the server. 763 # 764 # Note that if the AOF file will be found to be corrupted in the middle 765 # the server will still exit with an error. This option only applies when 766 # Redis will try to read more data from the AOF file but not enough bytes 767 # will be found. 768 aof-load-truncated yes 769 770 # When rewriting the AOF file, Redis is able to use an RDB preamble in the 771 # AOF file for faster rewrites and recoveries. When this option is turned 772 # on the rewritten AOF file is composed of two different stanzas: 773 # 774 # [RDB file][AOF tail] 775 # 776 # When loading Redis recognizes that the AOF file starts with the "REDIS" 777 # string and loads the prefixed RDB file, and continues loading the AOF 778 # tail. 779 # 780 # This is currently turned off by default in order to avoid the surprise 781 # of a format change, but will at some point be used as the default. 782 aof-use-rdb-preamble no 783 784 ################################ LUA SCRIPTING ############################### 785 786 # Max execution time of a Lua script in milliseconds. 787 # 788 # If the maximum execution time is reached Redis will log that a script is 789 # still in execution after the maximum allowed time and will start to 790 # reply to queries with an error. 791 # 792 # When a long running script exceeds the maximum execution time only the 793 # SCRIPT KILL and SHUTDOWN NOSAVE commands are available. The first can be 794 # used to stop a script that did not yet called write commands. The second 795 # is the only way to shut down the server in the case a write command was 796 # already issued by the script but the user doesn't want to wait for the natural 797 # termination of the script. 798 # 799 # Set it to 0 or a negative value for unlimited execution without warnings. 800 lua-time-limit 5000 801 802 ################################ REDIS CLUSTER ############################### 803 # 804 # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 805 # WARNING EXPERIMENTAL: Redis Cluster is considered to be stable code, however 806 # in order to mark it as "mature" we need to wait for a non trivial percentage 807 # of users to deploy it in production. 808 # ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ 809 # 810 # Normal Redis instances can't be part of a Redis Cluster; only nodes that are 811 # started as cluster nodes can. In order to start a Redis instance as a 812 # cluster node enable the cluster support uncommenting the following: 813 # 814 cluster-enabled yes 815 816 # Every cluster node has a cluster configuration file. This file is not 817 # intended to be edited by hand. It is created and updated by Redis nodes. 818 # Every Redis Cluster node requires a different cluster configuration file. 819 # Make sure that instances running in the same system do not have 820 # overlapping cluster configuration file names. 821 # 822 cluster-config-file nodes-6381.conf 823 824 # Cluster node timeout is the amount of milliseconds a node must be unreachable 825 # for it to be considered in failure state. 826 # Most other internal time limits are multiple of the node timeout. 827 # 828 # cluster-node-timeout 15000 829 830 # A slave of a failing master will avoid to start a failover if its data 831 # looks too old. 832 # 833 # There is no simple way for a slave to actually have an exact measure of 834 # its "data age", so the following two checks are performed: 835 # 836 # 1) If there are multiple slaves able to failover, they exchange messages 837 # in order to try to give an advantage to the slave with the best 838 # replication offset (more data from the master processed). 839 # Slaves will try to get their rank by offset, and apply to the start 840 # of the failover a delay proportional to their rank. 841 # 842 # 2) Every single slave computes the time of the last interaction with 843 # its master. This can be the last ping or command received (if the master 844 # is still in the "connected" state), or the time that elapsed since the 845 # disconnection with the master (if the replication link is currently down). 846 # If the last interaction is too old, the slave will not try to failover 847 # at all. 848 # 849 # The point "2" can be tuned by user. Specifically a slave will not perform 850 # the failover if, since the last interaction with the master, the time 851 # elapsed is greater than: 852 # 853 # (node-timeout * slave-validity-factor) + repl-ping-slave-period 854 # 855 # So for example if node-timeout is 30 seconds, and the slave-validity-factor 856 # is 10, and assuming a default repl-ping-slave-period of 10 seconds, the 857 # slave will not try to failover if it was not able to talk with the master 858 # for longer than 310 seconds. 859 # 860 # A large slave-validity-factor may allow slaves with too old data to failover 861 # a master, while a too small value may prevent the cluster from being able to 862 # elect a slave at all. 863 # 864 # For maximum availability, it is possible to set the slave-validity-factor 865 # to a value of 0, which means, that slaves will always try to failover the 866 # master regardless of the last time they interacted with the master. 867 # (However they'll always try to apply a delay proportional to their 868 # offset rank). 869 # 870 # Zero is the only value able to guarantee that when all the partitions heal 871 # the cluster will always be able to continue. 872 # 873 # cluster-slave-validity-factor 10 874 875 # Cluster slaves are able to migrate to orphaned masters, that are masters 876 # that are left without working slaves. This improves the cluster ability 877 # to resist to failures as otherwise an orphaned master can't be failed over 878 # in case of failure if it has no working slaves. 879 # 880 # Slaves migrate to orphaned masters only if there are still at least a 881 # given number of other working slaves for their old master. This number 882 # is the "migration barrier". A migration barrier of 1 means that a slave 883 # will migrate only if there is at least 1 other working slave for its master 884 # and so forth. It usually reflects the number of slaves you want for every 885 # master in your cluster. 886 # 887 # Default is 1 (slaves migrate only if their masters remain with at least 888 # one slave). To disable migration just set it to a very large value. 889 # A value of 0 can be set but is useful only for debugging and dangerous 890 # in production. 891 # 892 # cluster-migration-barrier 1 893 894 # By default Redis Cluster nodes stop accepting queries if they detect there 895 # is at least an hash slot uncovered (no available node is serving it). 896 # This way if the cluster is partially down (for example a range of hash slots 897 # are no longer covered) all the cluster becomes, eventually, unavailable. 898 # It automatically returns available as soon as all the slots are covered again. 899 # 900 # However sometimes you want the subset of the cluster which is working, 901 # to continue to accept queries for the part of the key space that is still 902 # covered. In order to do so, just set the cluster-require-full-coverage 903 # option to no. 904 # 905 # cluster-require-full-coverage yes 906 907 # In order to setup your cluster make sure to read the documentation 908 # available at http://redis.io web site. 909 910 ########################## CLUSTER DOCKER/NAT support ######################## 911 912 # In certain deployments, Redis Cluster nodes address discovery fails, because 913 # addresses are NAT-ted or because ports are forwarded (the typical case is 914 # Docker and other containers). 915 # 916 # In order to make Redis Cluster working in such environments, a static 917 # configuration where each node knows its public address is needed. The 918 # following two options are used for this scope, and are: 919 # 920 # * cluster-announce-ip 921 # * cluster-announce-port 922 # * cluster-announce-bus-port 923 # 924 # Each instruct the node about its address, client port, and cluster message 925 # bus port. The information is then published in the header of the bus packets 926 # so that other nodes will be able to correctly map the address of the node 927 # publishing the information. 928 # 929 # If the above options are not used, the normal Redis Cluster auto-detection 930 # will be used instead. 931 # 932 # Note that when remapped, the bus port may not be at the fixed offset of 933 # clients port + 10000, so you can specify any port and bus-port depending 934 # on how they get remapped. If the bus-port is not set, a fixed offset of 935 # 10000 will be used as usually. 936 # 937 # Example: 938 # 939 # cluster-announce-ip 10.1.1.5 940 # cluster-announce-port 6379 941 # cluster-announce-bus-port 6380 942 943 ################################## SLOW LOG ################################### 944 945 # The Redis Slow Log is a system to log queries that exceeded a specified 946 # execution time. The execution time does not include the I/O operations 947 # like talking with the client, sending the reply and so forth, 948 # but just the time needed to actually execute the command (this is the only 949 # stage of command execution where the thread is blocked and can not serve 950 # other requests in the meantime). 951 # 952 # You can configure the slow log with two parameters: one tells Redis 953 # what is the execution time, in microseconds, to exceed in order for the 954 # command to get logged, and the other parameter is the length of the 955 # slow log. When a new command is logged the oldest one is removed from the 956 # queue of logged commands. 957 958 # The following time is expressed in microseconds, so 1000000 is equivalent 959 # to one second. Note that a negative number disables the slow log, while 960 # a value of zero forces the logging of every command. 961 slowlog-log-slower-than 10000 962 963 # There is no limit to this length. Just be aware that it will consume memory. 964 # You can reclaim memory used by the slow log with SLOWLOG RESET. 965 slowlog-max-len 128 966 967 ################################ LATENCY MONITOR ############################## 968 969 # The Redis latency monitoring subsystem samples different operations 970 # at runtime in order to collect data related to possible sources of 971 # latency of a Redis instance. 972 # 973 # Via the LATENCY command this information is available to the user that can 974 # print graphs and obtain reports. 975 # 976 # The system only logs operations that were performed in a time equal or 977 # greater than the amount of milliseconds specified via the 978 # latency-monitor-threshold configuration directive. When its value is set 979 # to zero, the latency monitor is turned off. 980 # 981 # By default latency monitoring is disabled since it is mostly not needed 982 # if you don't have latency issues, and collecting data has a performance 983 # impact, that while very small, can be measured under big load. Latency 984 # monitoring can easily be enabled at runtime using the command 985 # "CONFIG SET latency-monitor-threshold <milliseconds>" if needed. 986 latency-monitor-threshold 0 987 988 ############################# EVENT NOTIFICATION ############################## 989 990 # Redis can notify Pub/Sub clients about events happening in the key space. 991 # This feature is documented at http://redis.io/topics/notifications 992 # 993 # For instance if keyspace events notification is enabled, and a client 994 # performs a DEL operation on key "foo" stored in the Database 0, two 995 # messages will be published via Pub/Sub: 996 # 997 # PUBLISH __keyspace@0__:foo del 998 # PUBLISH __keyevent@0__:del foo 999 # 1000 # It is possible to select the events that Redis will notify among a set 1001 # of classes. Every class is identified by a single character: 1002 # 1003 # K Keyspace events, published with __keyspace@<db>__ prefix. 1004 # E Keyevent events, published with __keyevent@<db>__ prefix. 1005 # g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ... 1006 # $ String commands 1007 # l List commands 1008 # s Set commands 1009 # h Hash commands 1010 # z Sorted set commands 1011 # x Expired events (events generated every time a key expires) 1012 # e Evicted events (events generated when a key is evicted for maxmemory) 1013 # A Alias for g$lshzxe, so that the "AKE" string means all the events. 1014 # 1015 # The "notify-keyspace-events" takes as argument a string that is composed 1016 # of zero or multiple characters. The empty string means that notifications 1017 # are disabled. 1018 # 1019 # Example: to enable list and generic events, from the point of view of the 1020 # event name, use: 1021 # 1022 # notify-keyspace-events Elg 1023 # 1024 # Example 2: to get the stream of the expired keys subscribing to channel 1025 # name __keyevent@0__:expired use: 1026 # 1027 # notify-keyspace-events Ex 1028 # 1029 # By default all notifications are disabled because most users don't need 1030 # this feature and the feature has some overhead. Note that if you don't 1031 # specify at least one of K or E, no events will be delivered. 1032 notify-keyspace-events "" 1033 1034 ############################### ADVANCED CONFIG ############################### 1035 1036 # Hashes are encoded using a memory efficient data structure when they have a 1037 # small number of entries, and the biggest entry does not exceed a given 1038 # threshold. These thresholds can be configured using the following directives. 1039 hash-max-ziplist-entries 512 1040 hash-max-ziplist-value 64 1041 1042 # Lists are also encoded in a special way to save a lot of space. 1043 # The number of entries allowed per internal list node can be specified 1044 # as a fixed maximum size or a maximum number of elements. 1045 # For a fixed maximum size, use -5 through -1, meaning: 1046 # -5: max size: 64 Kb <-- not recommended for normal workloads 1047 # -4: max size: 32 Kb <-- not recommended 1048 # -3: max size: 16 Kb <-- probably not recommended 1049 # -2: max size: 8 Kb <-- good 1050 # -1: max size: 4 Kb <-- good 1051 # Positive numbers mean store up to _exactly_ that number of elements 1052 # per list node. 1053 # The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size), 1054 # but if your use case is unique, adjust the settings as necessary. 1055 list-max-ziplist-size -2 1056 1057 # Lists may also be compressed. 1058 # Compress depth is the number of quicklist ziplist nodes from *each* side of 1059 # the list to *exclude* from compression. The head and tail of the list 1060 # are always uncompressed for fast push/pop operations. Settings are: 1061 # 0: disable all list compression 1062 # 1: depth 1 means "don't start compressing until after 1 node into the list, 1063 # going from either the head or tail" 1064 # So: [head]->node->node->...->node->[tail] 1065 # [head], [tail] will always be uncompressed; inner nodes will compress. 1066 # 2: [head]->[next]->node->node->...->node->[prev]->[tail] 1067 # 2 here means: don't compress head or head->next or tail->prev or tail, 1068 # but compress all nodes between them. 1069 # 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail] 1070 # etc. 1071 list-compress-depth 0 1072 1073 # Sets have a special encoding in just one case: when a set is composed 1074 # of just strings that happen to be integers in radix 10 in the range 1075 # of 64 bit signed integers. 1076 # The following configuration setting sets the limit in the size of the 1077 # set in order to use this special memory saving encoding. 1078 set-max-intset-entries 512 1079 1080 # Similarly to hashes and lists, sorted sets are also specially encoded in 1081 # order to save a lot of space. This encoding is only used when the length and 1082 # elements of a sorted set are below the following limits: 1083 zset-max-ziplist-entries 128 1084 zset-max-ziplist-value 64 1085 1086 # HyperLogLog sparse representation bytes limit. The limit includes the 1087 # 16 bytes header. When an HyperLogLog using the sparse representation crosses 1088 # this limit, it is converted into the dense representation. 1089 # 1090 # A value greater than 16000 is totally useless, since at that point the 1091 # dense representation is more memory efficient. 1092 # 1093 # The suggested value is ~ 3000 in order to have the benefits of 1094 # the space efficient encoding without slowing down too much PFADD, 1095 # which is O(N) with the sparse encoding. The value can be raised to 1096 # ~ 10000 when CPU is not a concern, but space is, and the data set is 1097 # composed of many HyperLogLogs with cardinality in the 0 - 15000 range. 1098 hll-sparse-max-bytes 3000 1099 1100 # Active rehashing uses 1 millisecond every 100 milliseconds of CPU time in 1101 # order to help rehashing the main Redis hash table (the one mapping top-level 1102 # keys to values). The hash table implementation Redis uses (see dict.c) 1103 # performs a lazy rehashing: the more operation you run into a hash table 1104 # that is rehashing, the more rehashing "steps" are performed, so if the 1105 # server is idle the rehashing is never complete and some more memory is used 1106 # by the hash table. 1107 # 1108 # The default is to use this millisecond 10 times every second in order to 1109 # actively rehash the main dictionaries, freeing memory when possible. 1110 # 1111 # If unsure: 1112 # use "activerehashing no" if you have hard latency requirements and it is 1113 # not a good thing in your environment that Redis can reply from time to time 1114 # to queries with 2 milliseconds delay. 1115 # 1116 # use "activerehashing yes" if you don't have such hard requirements but 1117 # want to free memory asap when possible. 1118 activerehashing yes 1119 1120 # The client output buffer limits can be used to force disconnection of clients 1121 # that are not reading data from the server fast enough for some reason (a 1122 # common reason is that a Pub/Sub client can't consume messages as fast as the 1123 # publisher can produce them). 1124 # 1125 # The limit can be set differently for the three different classes of clients: 1126 # 1127 # normal -> normal clients including MONITOR clients 1128 # slave -> slave clients 1129 # pubsub -> clients subscribed to at least one pubsub channel or pattern 1130 # 1131 # The syntax of every client-output-buffer-limit directive is the following: 1132 # 1133 # client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds> 1134 # 1135 # A client is immediately disconnected once the hard limit is reached, or if 1136 # the soft limit is reached and remains reached for the specified number of 1137 # seconds (continuously). 1138 # So for instance if the hard limit is 32 megabytes and the soft limit is 1139 # 16 megabytes / 10 seconds, the client will get disconnected immediately 1140 # if the size of the output buffers reach 32 megabytes, but will also get 1141 # disconnected if the client reaches 16 megabytes and continuously overcomes 1142 # the limit for 10 seconds. 1143 # 1144 # By default normal clients are not limited because they don't receive data 1145 # without asking (in a push way), but just after a request, so only 1146 # asynchronous clients may create a scenario where data is requested faster 1147 # than it can read. 1148 # 1149 # Instead there is a default limit for pubsub and slave clients, since 1150 # subscribers and slaves receive data in a push fashion. 1151 # 1152 # Both the hard or the soft limit can be disabled by setting them to zero. 1153 client-output-buffer-limit normal 0 0 0 1154 client-output-buffer-limit slave 256mb 64mb 60 1155 client-output-buffer-limit pubsub 32mb 8mb 60 1156 1157 # Client query buffers accumulate new commands. They are limited to a fixed 1158 # amount by default in order to avoid that a protocol desynchronization (for 1159 # instance due to a bug in the client) will lead to unbound memory usage in 1160 # the query buffer. However you can configure it here if you have very special 1161 # needs, such us huge multi/exec requests or alike. 1162 # 1163 # client-query-buffer-limit 1gb 1164 1165 # In the Redis protocol, bulk requests, that are, elements representing single 1166 # strings, are normally limited ot 512 mb. However you can change this limit 1167 # here. 1168 # 1169 # proto-max-bulk-len 512mb 1170 1171 # Redis calls an internal function to perform many background tasks, like 1172 # closing connections of clients in timeout, purging expired keys that are 1173 # never requested, and so forth. 1174 # 1175 # Not all tasks are performed with the same frequency, but Redis checks for 1176 # tasks to perform according to the specified "hz" value. 1177 # 1178 # By default "hz" is set to 10. Raising the value will use more CPU when 1179 # Redis is idle, but at the same time will make Redis more responsive when 1180 # there are many keys expiring at the same time, and timeouts may be 1181 # handled with more precision. 1182 # 1183 # The range is between 1 and 500, however a value over 100 is usually not 1184 # a good idea. Most users should use the default of 10 and raise this up to 1185 # 100 only in environments where very low latency is required. 1186 hz 10 1187 1188 # When a child rewrites the AOF file, if the following option is enabled 1189 # the file will be fsync-ed every 32 MB of data generated. This is useful 1190 # in order to commit the file to the disk more incrementally and avoid 1191 # big latency spikes. 1192 aof-rewrite-incremental-fsync yes 1193 1194 # Redis LFU eviction (see maxmemory setting) can be tuned. However it is a good 1195 # idea to start with the default settings and only change them after investigating 1196 # how to improve the performances and how the keys LFU change over time, which 1197 # is possible to inspect via the OBJECT FREQ command. 1198 # 1199 # There are two tunable parameters in the Redis LFU implementation: the 1200 # counter logarithm factor and the counter decay time. It is important to 1201 # understand what the two parameters mean before changing them. 1202 # 1203 # The LFU counter is just 8 bits per key, it's maximum value is 255, so Redis 1204 # uses a probabilistic increment with logarithmic behavior. Given the value 1205 # of the old counter, when a key is accessed, the counter is incremented in 1206 # this way: 1207 # 1208 # 1. A random number R between 0 and 1 is extracted. 1209 # 2. A probability P is calculated as 1/(old_value*lfu_log_factor+1). 1210 # 3. The counter is incremented only if R < P. 1211 # 1212 # The default lfu-log-factor is 10. This is a table of how the frequency 1213 # counter changes with a different number of accesses with different 1214 # logarithmic factors: 1215 # 1216 # +--------+------------+------------+------------+------------+------------+ 1217 # | factor | 100 hits | 1000 hits | 100K hits | 1M hits | 10M hits | 1218 # +--------+------------+------------+------------+------------+------------+ 1219 # | 0 | 104 | 255 | 255 | 255 | 255 | 1220 # +--------+------------+------------+------------+------------+------------+ 1221 # | 1 | 18 | 49 | 255 | 255 | 255 | 1222 # +--------+------------+------------+------------+------------+------------+ 1223 # | 10 | 10 | 18 | 142 | 255 | 255 | 1224 # +--------+------------+------------+------------+------------+------------+ 1225 # | 100 | 8 | 11 | 49 | 143 | 255 | 1226 # +--------+------------+------------+------------+------------+------------+ 1227 # 1228 # NOTE: The above table was obtained by running the following commands: 1229 # 1230 # redis-benchmark -n 1000000 incr foo 1231 # redis-cli object freq foo 1232 # 1233 # NOTE 2: The counter initial value is 5 in order to give new objects a chance 1234 # to accumulate hits. 1235 # 1236 # The counter decay time is the time, in minutes, that must elapse in order 1237 # for the key counter to be divided by two (or decremented if it has a value 1238 # less <= 10). 1239 # 1240 # The default value for the lfu-decay-time is 1. A Special value of 0 means to 1241 # decay the counter every time it happens to be scanned. 1242 # 1243 # lfu-log-factor 10 1244 # lfu-decay-time 1 1245 1246 ########################### ACTIVE DEFRAGMENTATION ####################### 1247 # 1248 # WARNING THIS FEATURE IS EXPERIMENTAL. However it was stress tested 1249 # even in production and manually tested by multiple engineers for some 1250 # time. 1251 # 1252 # What is active defragmentation? 1253 # ------------------------------- 1254 # 1255 # Active (online) defragmentation allows a Redis server to compact the 1256 # spaces left between small allocations and deallocations of data in memory, 1257 # thus allowing to reclaim back memory. 1258 # 1259 # Fragmentation is a natural process that happens with every allocator (but 1260 # less so with Jemalloc, fortunately) and certain workloads. Normally a server 1261 # restart is needed in order to lower the fragmentation, or at least to flush 1262 # away all the data and create it again. However thanks to this feature 1263 # implemented by Oran Agra for Redis 4.0 this process can happen at runtime 1264 # in an "hot" way, while the server is running. 1265 # 1266 # Basically when the fragmentation is over a certain level (see the 1267 # configuration options below) Redis will start to create new copies of the 1268 # values in contiguous memory regions by exploiting certain specific Jemalloc 1269 # features (in order to understand if an allocation is causing fragmentation 1270 # and to allocate it in a better place), and at the same time, will release the 1271 # old copies of the data. This process, repeated incrementally for all the keys 1272 # will cause the fragmentation to drop back to normal values. 1273 # 1274 # Important things to understand: 1275 # 1276 # 1. This feature is disabled by default, and only works if you compiled Redis 1277 # to use the copy of Jemalloc we ship with the source code of Redis. 1278 # This is the default with Linux builds. 1279 # 1280 # 2. You never need to enable this feature if you don't have fragmentation 1281 # issues. 1282 # 1283 # 3. Once you experience fragmentation, you can enable this feature when 1284 # needed with the command "CONFIG SET activedefrag yes". 1285 # 1286 # The configuration parameters are able to fine tune the behavior of the 1287 # defragmentation process. If you are not sure about what they mean it is 1288 # a good idea to leave the defaults untouched. 1289 1290 # Enabled active defragmentation 1291 # activedefrag yes 1292 1293 # Minimum amount of fragmentation waste to start active defrag 1294 # active-defrag-ignore-bytes 100mb 1295 1296 # Minimum percentage of fragmentation to start active defrag 1297 # active-defrag-threshold-lower 10 1298 1299 # Maximum percentage of fragmentation at which we use maximum effort 1300 # active-defrag-threshold-upper 100 1301 1302 # Minimal effort for defrag in CPU percentage 1303 # active-defrag-cycle-min 25 1304 1305 # Maximal effort for defrag in CPU percentage 1306 # active-defrag-cycle-max 75
剩下的配置文件内容,只需要参考redis6381.conf,把其中涉及到6381修改为自己对应的6382、6383、6384...就可以了。
1.2、分别启动这些Redis数据库
(1)启动6个redis示例:
./redis-server redis6381.conf
./redis-server redis6382.conf
./redis-server redis6383.conf
./redis-server redis6384.conf
./redis-server redis6385.conf
./redis-server redis6386.conf
(2)执行命令:ps -ef|grep redis
501 12169 1 0 8:11上午 ?? 0:00.03 ./redis-server 127.0.0.1:6381 [cluster]
501 12171 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6382 [cluster]
501 12173 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6383 [cluster]
501 12175 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6384 [cluster]
501 12177 1 0 8:11上午 ?? 0:00.01 ./redis-server 127.0.0.1:6385 [cluster]
501 12179 1 0 8:11上午 ?? 0:00.01 ./redis-server 127.0.0.1:6386 [cluster]
501 12181 11792 0 8:11上午 ttys004 0:00.01 grep redis
./redis-server redis6381.conf
./redis-server redis6382.conf
./redis-server redis6383.conf
./redis-server redis6384.conf
./redis-server redis6385.conf
./redis-server redis6386.conf
(2)执行命令:ps -ef|grep redis
501 12169 1 0 8:11上午 ?? 0:00.03 ./redis-server 127.0.0.1:6381 [cluster]
501 12171 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6382 [cluster]
501 12173 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6383 [cluster]
501 12175 1 0 8:11上午 ?? 0:00.02 ./redis-server 127.0.0.1:6384 [cluster]
501 12177 1 0 8:11上午 ?? 0:00.01 ./redis-server 127.0.0.1:6385 [cluster]
501 12179 1 0 8:11上午 ?? 0:00.01 ./redis-server 127.0.0.1:6386 [cluster]
501 12181 11792 0 8:11上午 ttys004 0:00.01 grep redis
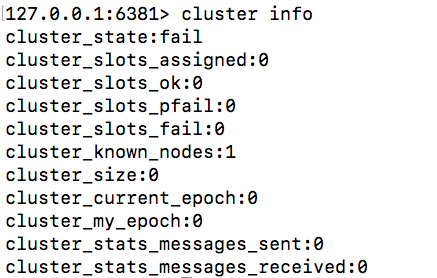
(3)可以用cluster info来进行查看,目前这6个redis实例是孤立的,它们之间还没有建立集群的关系
127.0.0.1:6381机器上执行命令:cluster info
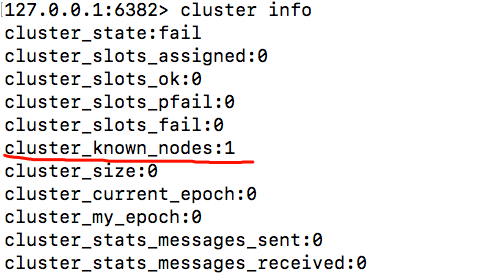
127.0.0.1:6382机器上执行命令:cluster info
1.3、连接节点,使用cluster meet,把所有的数据库都放到一个集群中来
在127.0.0.1:6381机器上执行如下命令:

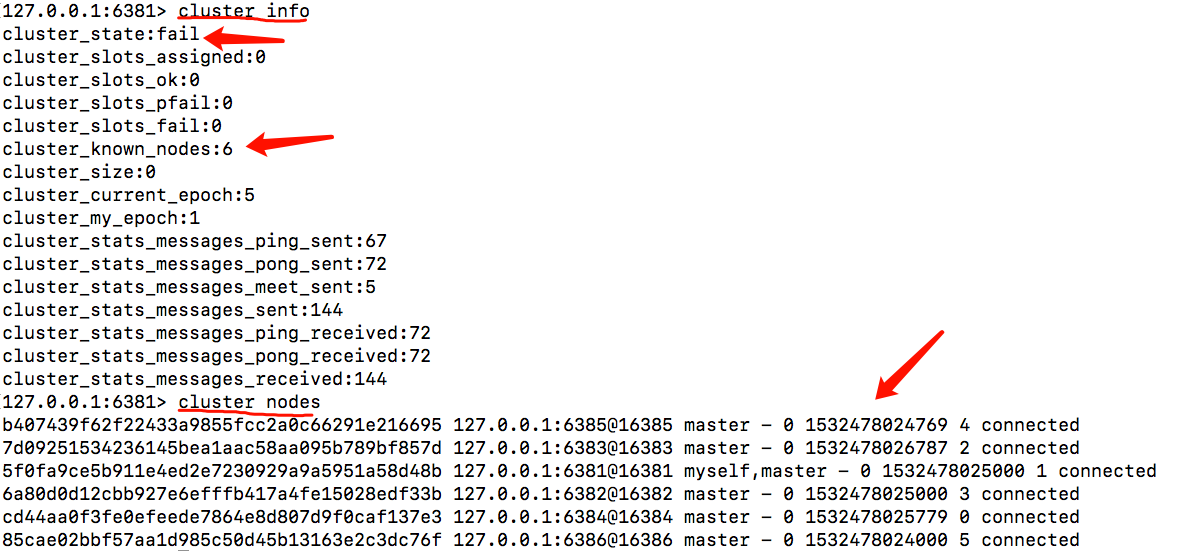
1.4、可以通过cluster info,或者cluster nodes查看信息
在127.0.0.1:6381机器上执行 cluster info、cluster nodes。(在其它的机器上执行也是一样的效果)
1.5、设置部分数据库为slave,使用cluster replicate
在127.0.0.1:6384机器上执行:cluster replicate 5f0fa9ce5b911e4ed2e7230929a9a5951a58d48b

在127.0.0.1:6385机器上执行:cluster replicate 6a80d0d12cbb927e6efffb417a4fe15028edf33b

在127.0.0.1:6386机器上执行:cluster replicate 7d09251534236145bea1aac58aa095b789bf857d

1.6、分配插槽
使用cluster addSlots,这个命令目前只能一个一个加,如果要加区间的话,就得客户端编写代码来循环添加了。
有个实用的技巧:把所有的Redis停下来,然后直接修改node的配置文件,只需要配置master的数据库就可以了,然后再重启数据库。
nodes-6381.conf的配置如下:(其它的5个文件也照着这样去配置)

重写启动6个redis数据库实例
./redis-server redis6381.conf
./redis-server redis6382.conf
./redis-server redis6383.conf
./redis-server redis6384.conf
./redis-server redis6385.conf
./redis-server redis6386.conf
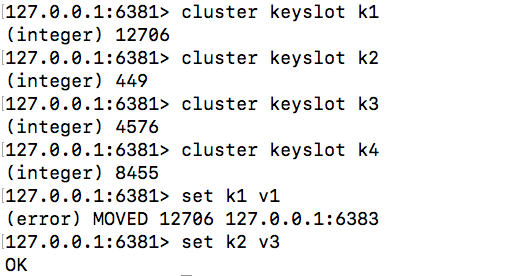
可以使用cluster keyslot key来查看每个key应该放到哪个插槽里面,如下:
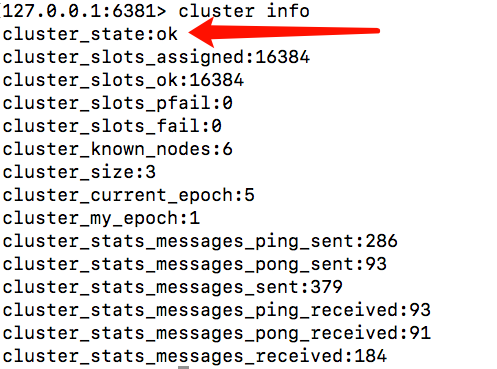
1.7、通过cluster info查看集群信息,如果显示ok,那就是可以使用了