之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片。
今天我们在豆瓣上获取一些热门电影的信息。
页面分析
首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影,啥都不点了。
【插入图片,豆瓣热门电影页面】
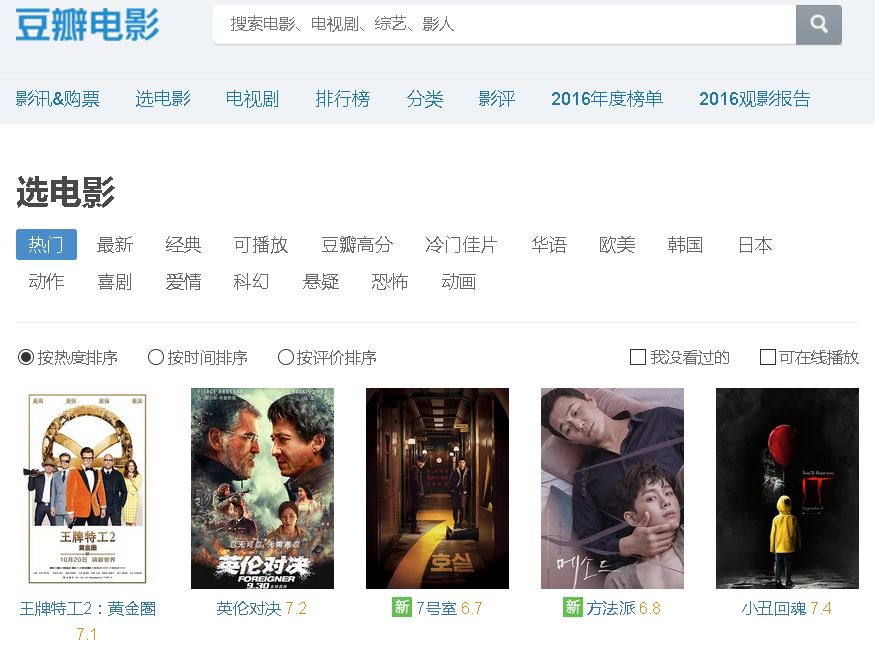
在选电影这个框中其实有很多标签的,这个其实可以在url设置,后面讲,现在就用热门好了。
下面每部电影罗列出来,包括电影封面,评分,电影名称等信息。
最下面是加载更多选项,其实看到这个加载更多,我就意识到这个页面肯定是用ajax技术实现的,就跟今日头条街拍那次一样,只不过不采用向下滚动,而是点击按钮加载的方式。
是不是这样的?我们看一下源代码。
果然都是一些js,我就不放图了,大家自己看一下就好了。
那么来看一下XHR了,果然下面有几个json文件,哈哈,猜测是正确的。
【插入图片,XHR分析】
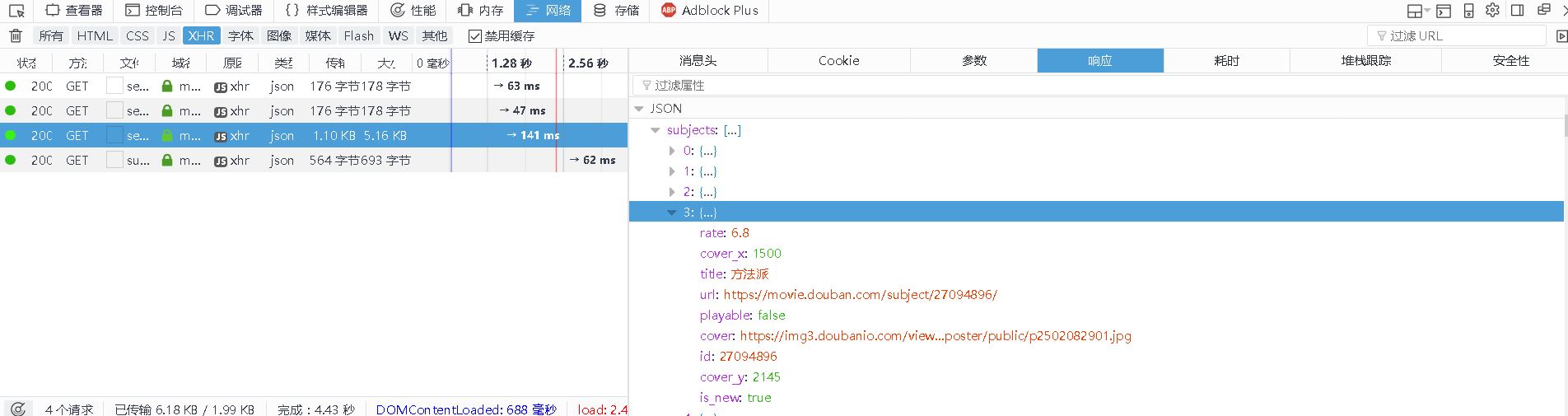
这次的json信息很简介,一个subjects下面就是各个电影的具体内容了,我们通过json的loads方法,就能够得到里面的信息了。
仍然是通过requests库来获取json信息,消息头的话,我们来看一下:
【插入图片,消息头分析】

这个url的前面部分是固定的,后面是一些参数,我们可以用urlencode来编码。
如果我们想要加载不同的页面,只要改变这个url里面的page_start参数就好了
【插入图片,加载更多】
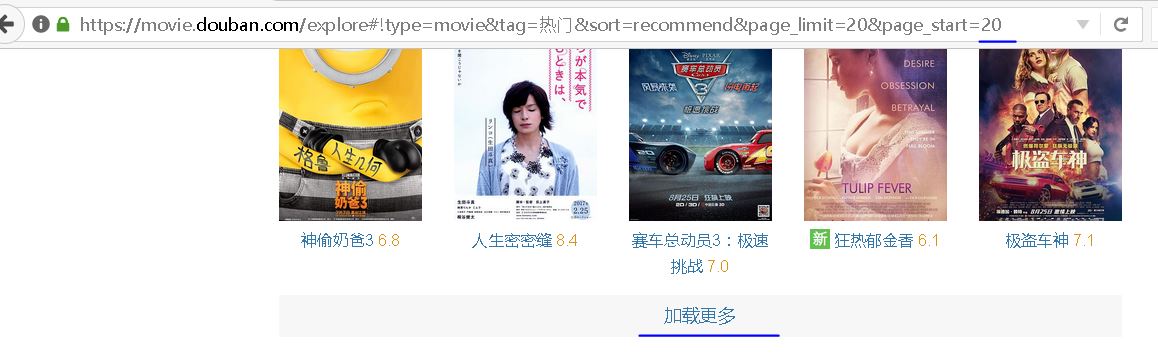
获取到某条电影信息后,我们就保存到mongodb数据库中。
代码展示
import requests
from urllib.parse import urlencode
import json
import pymongo
'''MONGO设置'''
MONGO_URL = 'localhost'
MONGO_DB = 'douban'
MONGO_Table = '热门'
client = pymongo.MongoClient(MONGO_URL)
db = client[MONGO_DB]
def get_movie_page(start_number):
data = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': 20,
'page_start': start_number
}
url = 'https://movie.douban.com/j/search_subjects?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
# print(response.text)
return response.text
except Exception:
print('请求出错!')
return None
def parse_index_movie(html):
movie = json.loads(html)
result = []
if movie and 'subjects' in movie.keys():
for item in movie.get('subjects'):
film = {
'rate': item.get('rate'),
'title': item.get('title'),
'url': item.get('url'),
'cover': item.get('cover')
}
result.append(film)
save_to_db(film)
return result
def save_to_db(film):
try:
if db[MONGO_Table].insert(film):
print('保存成功', film)
except Exception:
print('保存出错', film)
pass
def main():
for i in range(100):
html = get_movie_page(i*20)
parse_index_movie(html)
if __name__ == '__main__':
main()
【插入图片,mongo数据】
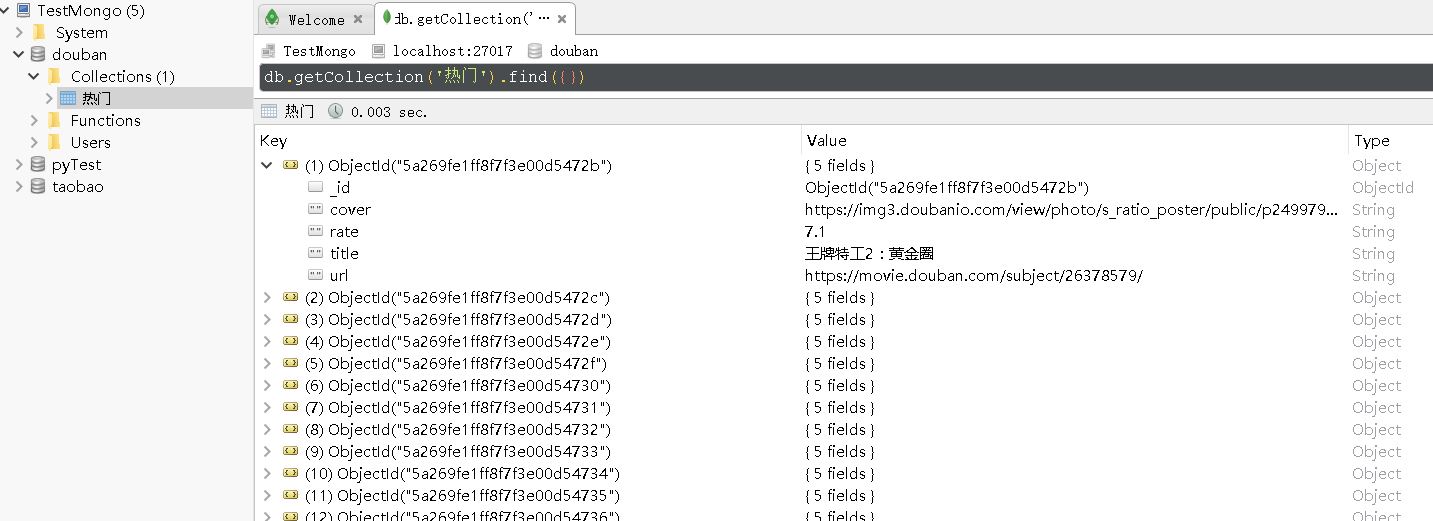
至此,我们得到了200多部热门电影的信息,尤其是每部电影的url,有了这个信息,我们就能打开每部电影的评论页面,获取到该部电影的短评。
这个留给明天再将。