把数据存储于普通的column列也能用于数据查询,那使用index有什么好处?
index的用途总结:
-
更方便的数据查询
-
使用index可以获得性能上的提升
-
自动的数据对其功能
-
更多更强大的数据结构支持
import pandas as pd df = pd.read_csv('../../datas/files/ratings.csv') print('*' * 25, '1. 读取csv文件,打印前几行数据', '*' * 25) print(df.head()) print('*' * 25, '计算条数', '*' * 25) print(df.count()) # -------------------- 1. 使用index查询数据 ------------------------ # # drop==False,让索引列还保持在column df.set_index('userId', inplace=True, drop=False) print('*' * 25, '打印前几行数据', '*' * 25) print(df.head()) print('*' * 25, '打印索引', '*' * 25) print(df.index) # 使用index的查询方法 print('*' * 25, '使用index的查询方法', '*' * 25) print(df.loc[500].head(5)) # 使用column的condition查询方法 print('*' * 25, '使用column的condition查询方法', '*' * 25) print(df.loc[df['userId'] == 500].head())
-
-
如果index不是唯一的,但是有序,Pandas会使用二分查找算法,查询性能为O(logN)
-
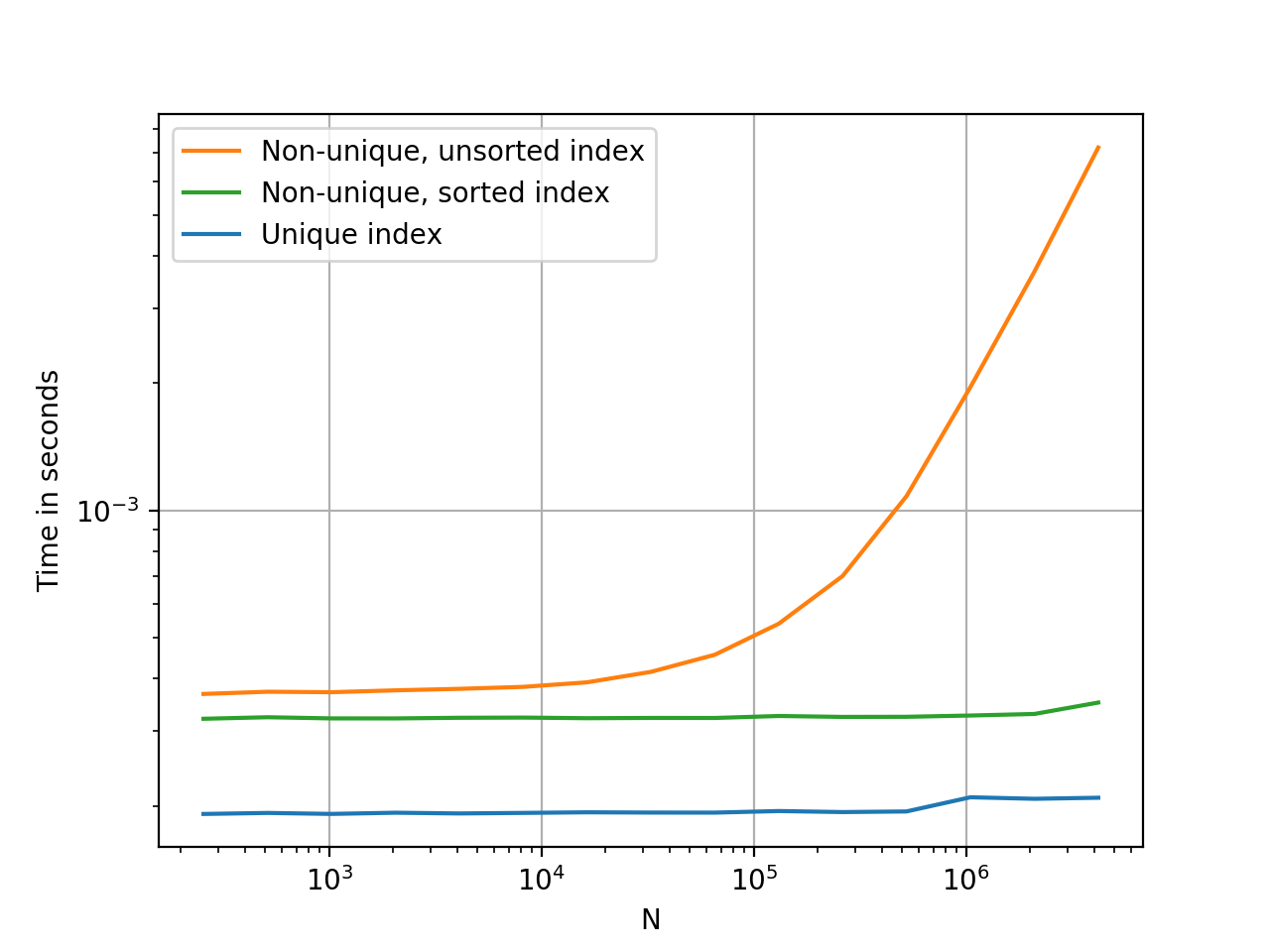
import pandas as pd import timeit from sklearn.utils import shuffle df = pd.read_csv('../../../datas/files/ratings.csv') print('*' * 25, '1. 读取csv文件,打印前几行数据', '*' * 25) print(df.head()) # 将数据随机打散 print('*' * 25, '2. 将数据随机打散,打印前几行数据', '*' * 25) df_shuffle = shuffle(df) print(df_shuffle.head()) # 判断索引是否是递增的 print('*' * 25, '3. 判断索引是否是递增的', '*' * 25) print(df_shuffle.index.is_monotonic_increasing) # 判断索引是否唯一 print('*' * 25, '4. 判断索引是否唯一', '*' * 25) print(df_shuffle.index.is_unique) # 计时查询id==500的数据查询性能 print('*' * 25, '4. 计时查询id==500的数据查询性能', '*' * 25) def test(): return df_shuffle.loc[500] print(timeit.timeit(stmt=test, number=10))
import pandas as pd import timeit from sklearn.utils import shuffle df = pd.read_csv('../../../datas/files/ratings.csv') print('*' * 25, '1. 读取csv文件,打印前几行数据', '*' * 25) print(df.head()) # 将数据随机打散 print('*' * 25, '2. 将数据随机打散,打印前几行数据', '*' * 25) df_shuffle = shuffle(df) print(df_shuffle.head()) # 将数据按照index排序 print('*' * 25, '3. 将数据按照index排序,打印前几行数据', '*' * 25) df_sorted = df_shuffle.sort_index() print(df_sorted.head()) # 判断索引是否是递增的 print('*' * 25, '4. 判断索引是否是递增的', '*' * 25) print(df_sorted.index.is_monotonic_increasing) # 判断索引是否唯一 print('*' * 25, '5. 判断索引是否唯一', '*' * 25) print(df_sorted.index.is_unique) # 计时查询id==500的数据查询性能 print('*' * 25, '5. 计时查询id==500的数据查询性能', '*' * 25) def test(): return df_sorted.loc[500] print(timeit.timeit(stmt=test, number=10))
import pandas as pd s1 = pd.Series([1, 2, 3], index=list('abc')) print(s1) s2 = pd.Series([2, 3, 4], index=list('bcd')) print(s2) print(s1 + s2)
-
CategoricalIndex, 基于分类数据的index,提升性能;
-
MultiIndex, 多维索引,用于groupby多维聚合后结果等;
-
DatetimeIndex, 时间类型索引,强大的日期和时间的方法支持;