Redis-shake is a tool for synchronizing data between two redis databases. Redis-shake是一个用于在两个redis之间同步数据的工具,满足用户非常灵活的同步、迁移需求
GitHub地址:https://github.com/alibaba/RedisShake
1. 下载,解压
wget -c https://github.com/alibaba/RedisShake/releases/download/release-v1.6.24-20191220/redis-shake-1.6.24.tar.gz
tar -zxvf redis-shake-1.6.24.tar.gz
cd redis-shake-1.6.24.tar.gz
2. 配置文件
# this is the configuration of redis-shake. # id id = redis-shake # log file,日志文件,不配置将打印到stdout log_file = # pprof port system_profile = 9310 # restful port,查看metric端口 http_profile = 9320 # runtime.GOMAXPROCS, 0 means use cpu core number: runtime.NumCPU() ncpu = 0 # parallel routines number used in RDB file syncing. parallel = 4 # input RDB file. read from stdin, default is stdin ('/dev/stdin'). # used in `decode` and `restore`. # 如果是decode或者restore,这个参数表示读取的rdb文件 input_rdb = local_dump # output RDB file. default is stdout ('/dev/stdout'). # used in `decode` and `dump`. # 如果是decode或者dump,这个参数表示输出的rdb output_rdb = local_dump # source redis configuration. # used in `dump` and `sync`. # ip:port # 源redis地址 source.address = 127.0.0.1:20441 # password. source.password_raw = kLNIl691OZctWST # auth type, don't modify it source.auth_type = auth # version number, default is 6 (6 for Redis Version <= 3.0.7, 7 for >=3.2.0) source.version = 6 # target redis configuration. used in `restore` and `sync`. # used in `restore` and `sync`. # ip:port # 目的redis地址 target.address = 10.101.72.137:20551 # password. target.password_raw = kLNIl691OZctWST # auth type, don't modify it target.auth_type = auth # version number, default is 6 (6 for Redis Version <= 3.0.7, 7 for >=3.2.0) target.version = 6 # all the data will come into this db. < 0 means disable. # used in `restore` and `sync`. target.db = -1 # use for expire key, set the time gap when source and target timestamp are not the same. # 用于处理过期的键值,当迁移两端不一致的时候,目的端需要加上这个值 fake_time = # force rewrite when destination restore has the key # used in `restore` and `sync`. # 当源目的有重复key,是否进行覆写 rewrite = true # filter db or key or slot # choose these db, e.g., 5, only choose db5. defalut is all. # used in `restore` and `sync`. # 支持过滤db,只让指定的db通过 filter.db = # filter key with prefix string. multiple keys are separated by ';'. # e.g., a;b;c # default is all. # used in `restore` and `sync`. # 支持过滤key,只让指定的key通过,分号分隔 filter.key = # filter given slot, multiple slots are separated by ';'. # e.g., 1;2;3 # used in `sync`. # 指定过滤slot,只让指定的slot通过 filter.slot = # big key threshold, the default is 500 * 1024 * 1024. The field of the big key will be split in processing. # 我们对大key有特殊的处理,此处需要指定大key的阈值 big_key_threshold = 524288000 # use psync command. # used in `sync`. # 默认使用sync命令,启用将会使用psync命令 psync = false # enable metric # used in `sync`. # 是否启用metric metric = true # print in log # 是否将metric打印到log中 metric.print_log = true # heartbeat # send heartbeat to this url # used in `sync`. # 心跳的url地址,redis-shake将会发送到这个地址 heartbeat.url = http://127.0.0.1:8000 # interval by seconds # 心跳保活周期 heartbeat.interval = 3 # external info which will be included in heartbeat data. # 在心跳报文中添加额外的信息 heartbeat.external = test external # local network card to get ip address, e.g., "lo", "eth0", "en0" # 获取ip的网卡 heartbeat.network_interface = # sender information. # sender flush buffer size of byte. # used in `sync`. # 发送缓存的字节长度,超过这个阈值将会强行刷缓存发送 sender.size = 104857600 # sender flush buffer size of oplog number. # used in `sync`. # 发送缓存的报文个数,超过这个阈值将会强行刷缓存发送 sender.count = 5000 # delay channel size. once one oplog is sent to target redis, the oplog id and timestamp will also stored in this delay queue. this timestamp will be used to calculate the time delay when receiving ack from target redis. # used in `sync`. # 用于metric统计时延的队列 sender.delay_channel_size = 65535 # ----------------splitter---------------- # below variables are useless for current opensource version so don't set. # replace hash tag. # used in `sync`. replace_hash_tag = false # used in `restore` and `dump`. extra = false
摘取部分内容:
这部分应该是用户最困惑的地方,为了满足用户的灵活配置,目前开放了较多的配置项,但用户一开始使用并不需要管这么多的项。默认sync模式只需要配置以下几个内容: source.type: 源redis的类型,支持一下4种类型: standalone: 单db节点/主从版模式。如果源端是从多个db节点拉取就选择这个模式,即便是codis等开源的proxy-db架构。 sentinel: sentinel模式。 cluster: 集群模式。开源的cluster。对于阿里云来说,用户目前无法拉取db的地址,所以此处只能是proxy。 proxy: proxy模式。如果是阿里云redis的集群版,从proxy拉取/写入请选择proxy,从db拉取请选择cluster。正常cluster到cluster同步源端请选择cluster模式,proxy模式目前只用于rump。。 source.address: 源redis的地址,从1.6版本开始我们支持集群版,不同的类型对应不同的地址: standalone模式下,需要填写单个db节点的地址,主从版需要输入master或者slave的地址。 sentinel模式下,需要填写sentinel_master_name:master_or_slave@sentinel_cluster_address。sentinel_master_name表示sentinel配置下master的名字,master_or_slave表示从sentinel中选择的db是master还是slave,sentinel_cluster_address表示sentinel的单节点或者集群地址,其中集群地址以分号(;)分割。例如:mymaster:master@127.0.0.1:26379;127.0.0.1:26380。注意,如果是sentinel模式,目前只能拉取一个master或者slave信息,如果需要拉取多个节点,需要启动多个shake。 cluster模式下,需要填写集群地址,以分号(;)分割。例如:10.1.1.1:20331;10.1.1.2:20441。同样也支持上面sentinel介绍的自动发现机制,包含@即可,参考3.2。 proxy模式下,需要填写单个proxy的地址,此模式目前仅用于rump。 source.password_raw:源redis的密码。 target.type: 目的redis的类型,与source.type一致。注意,目的端如果是阿里云的集群版,类型请填写proxy,填写cluster只会同步db0。 target.address:目的redis的地址。从1.6版本开始我们支持集群版,不同的类型对应不同的地址。 standalone模式,参见source.address。 sentinel模式,需要填写sentinel_master_name@sentinel_cluster_address。sentinel_master_name表示sentinel配置下master的名字,sentinel_cluster_address表示sentinel的单节点或者集群地址,其中集群地址以分号(;)分割。例如:mymaster@127.0.0.1:26379;127.0.0.1:26380 cluster模式,参见source.address。 proxy模式下,填写proxy的地址,如果是多个proxy,则round-robin循环负载均衡连接,保证一个源端db连接只会对应一个proxy。如果是阿里云的集群版请选择这种模式。 target.password_raw:目的redis的密码。 用户配置完配置文件,然后以不同的模式启动即可:./redis-shake -conf=redis-shake.conf -type=sync。 3.1 单个节点到单个节点配置举例。 source.type: standalone source.address: 10.1.1.1:20441 source.password_raw: 12345 target.type: standalone target.address: 10.1.1.1:20551 target.password_raw: 12345 3.2 集群版cluster到集群版cluster配置举例 source.type: cluster source.address: 10.1.1.1:20441;10.1.1.1:20443;10.1.1.1:20445 source.password_raw: 12345 target.type: cluster target.address: 10.1.1.1:20551;10.1.1.1:20553;10.1.1.1:20555 target.password_raw: 12345 对于source.address或者target.address,需要配置源端的所有集群中db节点列表以及目的端集群所有db节点列表,用户也可以启用自动发现机制,地址以'@'开头,redis-shake将会根据cluster nodes命令自动去探测有几个节点。对于source.address,用户可以在'@'前面配置master(默认)或者slave表示分表从master或者slave进行拉取;对于target.address,只能是master或者不配置: source.type: cluster source.address: master@10.1.1.1:20441 # 将会自动探测到10.1.1.1:20441集群下的所有节点,并从所有master进行拉取。同理如果是slave@10.1.1.1:20441将会扫描集群下的所有slave节点。 source.password_raw: 12345 target.type: cluster target.address: @10.1.1.1:20551 # 将会自动探测到10.1.1.1:20551集群下的所有节点,并写入所有master。 target.password_raw: 12345 以上的说明是开源cluster,当然,源端也可以是别的集群架构模式,比如带proxy的集群(比如codis,或者别的云集群架构,但这种情况下有些不支持自动发现,需要手动配置所有master或者slave的地址),那么需要选择db节点进行拉取,source.type同样选择cluster,source.address后面跟所有db的地址(只要主或者从的其中一个即可)。 3.3 集群版cluster到proxy配置举例 source.type: cluster source.address: 10.1.1.1:20441;10.1.1.1:20443;10.1.1.1:20445;10.1.1.1:20447 source.password_raw: 12345 target.type: proxy target.address: 10.1.1.1:30331;10.1.1.1:30441;10.1.1.1:30551 target.password_raw: 12345 source.address同样支持自动发现机制,参考3.2。此外,target.address为proxy的地址,proxy支持roundrobin写入,也就是说,对于这个配置来说,10.1.1.1:20441和10.1.1.1:20447将会写入10.1.1.1:30331;10.1.1.1:20443写入10.1.1.1:30441;10.1.1.1:20445写入10.1.1.1:30551。 如3.2中所述,源端也可以是别的集群架构模式。 3.4 主从版/单节点到cluster配置举例 source.type: standalone source.address: 10.1.1.1:20441 source.password_raw: 12345 target.type: cluster target.address: 10.1.1.1:30331;10.1.1.1:30441;10.1.1.1:30551 target.password_raw: 12345
更详细的查看: https://github.com/alibaba/RedisShake/wiki/%E7%AC%AC%E4%B8%80%E6%AC%A1%E4%BD%BF%E7%94%A8%EF%BC%8C%E5%A6%82%E4%BD%95%E8%BF%9B%E8%A1%8C%E9%85%8D%E7%BD%AE%EF%BC%9F
3. 启动
启动二进制:./redis-shake.linux -conf=redis-shake.conf -type=xxx # xxx为sync, restore, dump, decode, rump其中之一,全量+增量同步请选择sync。 mac下请使用redis-shake.darwin,windows请用redis-shake.windows.
4. 校验同步(redis-full-check github:https://github.com/alibaba/RedisFullCheck)
在Redis迁移完成后进行数据校验可以检查数据的一致性。
1) 下载,解压
wget -c https://github.com/alibaba/RedisFullCheck/releases/download/release-v1.4.7-20191203/redis-full-check-1.4.7.tar.gz tar -zxvf redis-full-check-1.4.7.tar.gz && cd redis-full-check-1.4.7.tar.gz
2) 执行数据校验命令
./redis-full-check -s "<Redis集群地址1连接地址:Redis集群地址1端口号;Redis集群地址2连接地址:Redis集群地址2端口号;Redis集群地址3连接地址:Redis集群地址3端口号>" -p <Redis集群密码> -t <Redis连接地址:Redis端口号> -a <Redis密码> --comparemode=1 --comparetimes=1 --qps=10 --batchcount=100 --sourcedbtype=1 --targetdbfilterlist=0
注意: 如果目标是集群的话,需要指定--targetdbtype 类型为1
| 选项 | 说明 | 示例值 |
|---|---|---|
| -s | 源端Redis的连接地址和端口。
说明
|
|
| -p | 源端Redis的密码。 | SourcePwd233 |
| -t | 目的端Redis的连接地址和端口。
说明
|
|
| -a | 目的端Redis的密码。 | TargetPwd233 |
| --sourcedbtype | 源库的类别:
|
--sourcedbtype=1 |
| --sourcedbfilterlist | 源端Redis指定需要校验的DB。
说明
|
--sourcedbfilterlist=0;1;2 |
| --targetdbtype | 目的库的类别:
|
--targetdbtype=0 |
| --targetdbfilterlist | 目的端Redis指定需要校验的DB。
说明
|
--targetdbfilterlist=0;1;2 |
| -d | 异常数据列表保存的文件名称,默认为result.db。 | xxx.db |
| --comparetimes | 校验次数。
|
--comparetimes=1 |
| -m | 校验模式。
|
1 |
| --qps | 限速阈值。
说明
|
--qps=10 |
| --filterlist | 需要比较的key列表,以竖线(|)分割。
说明
|
--filterlist=abc*|efg|m* |
3)校验结果验证
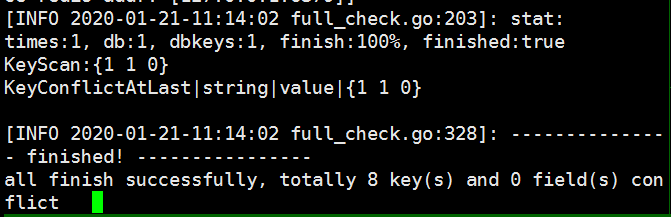
i) 执行查看命令
sqlite3 result.db.3
ii)查看异常表数据
select * from key;
5. 数据的导入与导出
数据导出: ./redis-shake.linux -conf=redis-shake.conf -type=dump 数据导入: ./redis-shake.linux -conf=redis-shake.conf -type=restore 注意: 数据导入的时候需要配置要导入的类型与数据源 source.rdb.input = local_dump.0
官方一些说明:
[redis-full-check]
redis-full-check是阿里云Redis&MongoDB团队开源的用于校验2个redis数据是否一致的工具,通常用于redis数据迁移(redis-shake)后正确性的校验。
支持:单节点、主从版、集群版、带proxy的云上集群版(阿里云)之间的同构或者异构对比,版本支持2.x-5.x。
基本原理
下图给出了最基本的比较逻辑。
redis-full-check通过全量对比源端和目的端的redis中的数据的方式来进行数据校验,其比较方式通过多轮次比较:每次都会抓取源和目的端的数据进行差异化比较,记录不一致的数据进入下轮对比(记录在sqlite3 db中)。然后通过多伦比较不断收敛,减少因数据增量同步导致的源库和目的库的数据不一致。最后sqlite中存在的数据就是最终的差异结果。
redis-full-check对比的方向是单向:抓取源库A的数据,然后检测是否位于B中,反向不会检测,也就是说,它检测的是源库是否是目的库的子集。如果希望对比双向,则需要对比2次,第一次以A为源库,B为目的库,第二次以B为源库,A为目的库。
下图是基本的数据流图,redis-full-check内部分为多轮比较,也就是黄色框所指示的部分。每次比较,会先抓取比较的key,第一轮是从源库中进行抓取,后面轮次是从sqlite3 db中进行抓取;抓取key之后是分别抓取key对应的field和value进行对比,然后将存在差异的部分存入sqlite3 db中,用于下次比较。
不一致类型
redis-full-check判断不一致的方式主要分为2类:key不一致和value不一致。
key不一致
key不一致主要分为以下几种情况:
lack_target: key存在于源库,但不存在于目的库。type: key存在于源库和目的库,但是类型不一致。value: key存在于源库和目的库,且类型一致,但是value不一致。
value不一致
不同数据类型有不同的对比标准:
- string: value不同。
-
hash: 存在field,满足下面3个条件之一:
- field存在于源端,但不存在与目的端。
- field存在于目的端,但不存在与源端。
- field同时存在于源和目的端,但是value不同。
- set/zset:与hash类似。
- list: 与hash类似。
field冲突类型有以下几种情况(只存在于hash,set,zset,list类型key中):
lack_source: field存在于源端key,field不存在与目的端key。lack_target: field不存在与源端key,field存在于目的端key。value: field存在于源端key和目的端key,但是field对应的value不同。
比较原理
对比模式(comparemode)有三种可选:
- KeyOutline:只对比key值是否相等。
- ValueOutline:只对比value值的长度是否相等。
- FullValue:对比key值、value长度、value值是否相等。
对比会进行comparetimes轮(默认comparetimes=3)比较:
- 第一轮,首先找出在源库上所有的key,然后分别从源库和目的库抓取进行比较。
-
第二轮开始迭代比较,只比较上一轮结束后仍然不一致的key和field。
- 对于key不一致的情况,包括
lack_source,lack_target和type,从源库和目的库重新取key、value进行比较。 value不一致的string,重新比较key:从源和目的取key、value比较。value不一致的hash、set和zset,只重新比较不一致的field,之前已经比较且相同的filed不再比较。这是为了防止对于大key情况下,如果更新频繁,将会导致校验永远不通过的情况。value不一致的list,重新比较key:从源和目的取key、value比较。
- 对于key不一致的情况,包括
- 每轮之间会停止一定的时间(
Interval)。
对于hash,set,zset,list大key处理采用以下方式:
- len <= 5192,直接取全量field、value进行比较,使用如下命令:
hgetall,smembers,zrange 0 -1 withscores,lrange 0 -1。 - len > 5192,使用hscan,sscan,zscan,lrange分批取field和value。
[redis-shake]
redis-shake是我们基于redis-port基础上进行改进的一款产品。它支持解析、恢复、备份、同步四个功能。以下主要介绍同步sync。
- 恢复restore:将RDB文件恢复到目的redis数据库。
- 备份dump:将源redis的全量数据通过RDB文件备份起来。
- 解析decode:对RDB文件进行读取,并以json格式解析存储。
- 同步sync:支持源redis和目的redis的数据同步,支持全量和增量数据的迁移,支持从云下到阿里云云上的同步,也支持云下到云下不同环境的同步,支持单节点、主从版、集群版之间的互相同步。需要注意的是,如果源端是集群版,可以启动一个RedisShake,从不同的db结点进行拉取,同时源端不能开启move slot功能;对于目的端,如果是集群版,写入可以是1个或者多个db结点。
- 同步rump:支持源redis和目的redis的数据同步,仅支持全量的迁移。采用scan和restore命令进行迁移,支持不同云厂商不同redis版本的迁移。
基本原理
redis-shake的基本原理就是模拟一个从节点加入源redis集群,首先进行全量拉取并回放,然后进行增量的拉取(通过psync命令)。如下图所示:
如果源端是集群模式,只需要启动一个redis-shake进行拉取,同时不能开启源端的move slot操作。如果目的端是集群模式,可以写入到一个结点,然后再进行slot的迁移,当然也可以多对多写入。
目前,redis-shake到目的端采用单链路实现,对于正常情况下,这不会成为瓶颈,但对于极端情况,qps比较大的时候,此部分性能可能成为瓶颈,后续我们可能会计划对此进行优化。另外,redis-shake到目的端的数据同步采用异步的方式,读写分离在2个线程操作,降低因为网络时延带来的同步性能下降。
高效性
全量同步阶段并发执行,增量同步阶段异步执行,能够达到毫秒级别延迟(取决于网络延迟)。同时,我们还对大key同步进行分批拉取,优化同步性能。
监控
用户可以通过我们提供的restful拉取metric来对redis-shake进行实时监控:curl 127.0.0.1:9320/metric。
校验
如何校验同步的正确性?可以采用我们开源的redis-full-check,具体原理可以参考这篇博客。
支持
- 支持2.8-5.0版本的同步。
- 支持codis。
- 支持云下到云上,云上到云上,云上到云下(阿里云目前支持主从版),其他云到阿里云等链路,帮助用户灵活构建混合云场景。
开发中的功能
- 断点续传。支持断开后按offset恢复,降低因主备切换、网络抖动造成链路断开重新同步拉取全量的性能影响。
- 多活支持。支持双向实时同步,搭建异地灾备多活。