一、headers的获取
就以博客园的首页为例:http://www.cnblogs.com/
打开网页,按下F12键,如下图所示:
点击下方标签中的Network,如下:
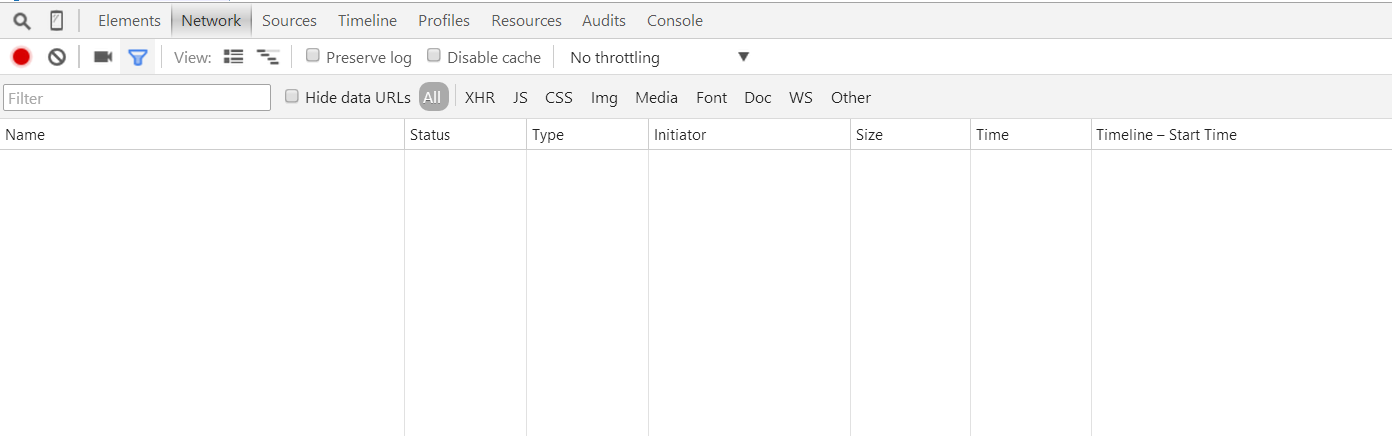
之后再点击下图所示位置:
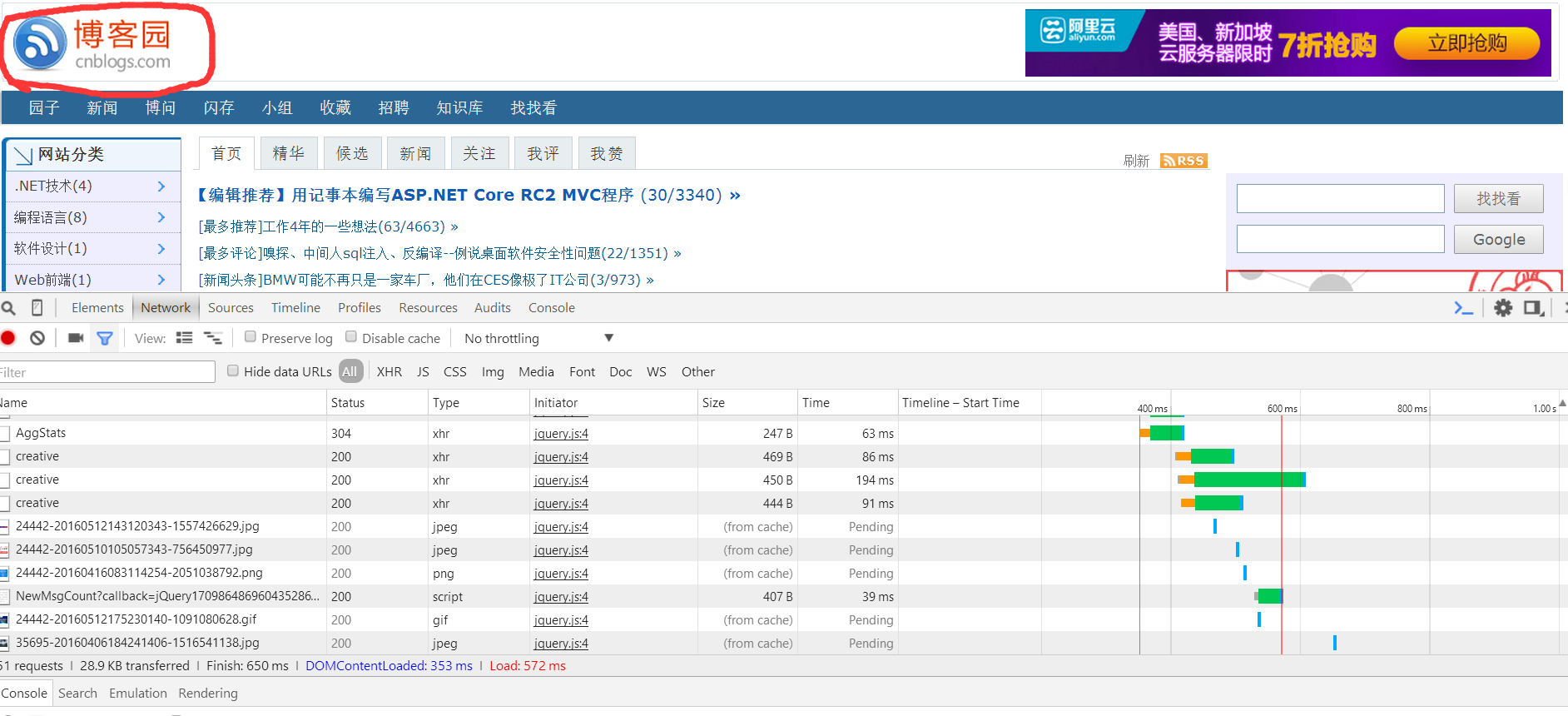
找到红色下划线位置所示的标签并点击,在右边的显示内容中可以查看到所需要的headers信息。
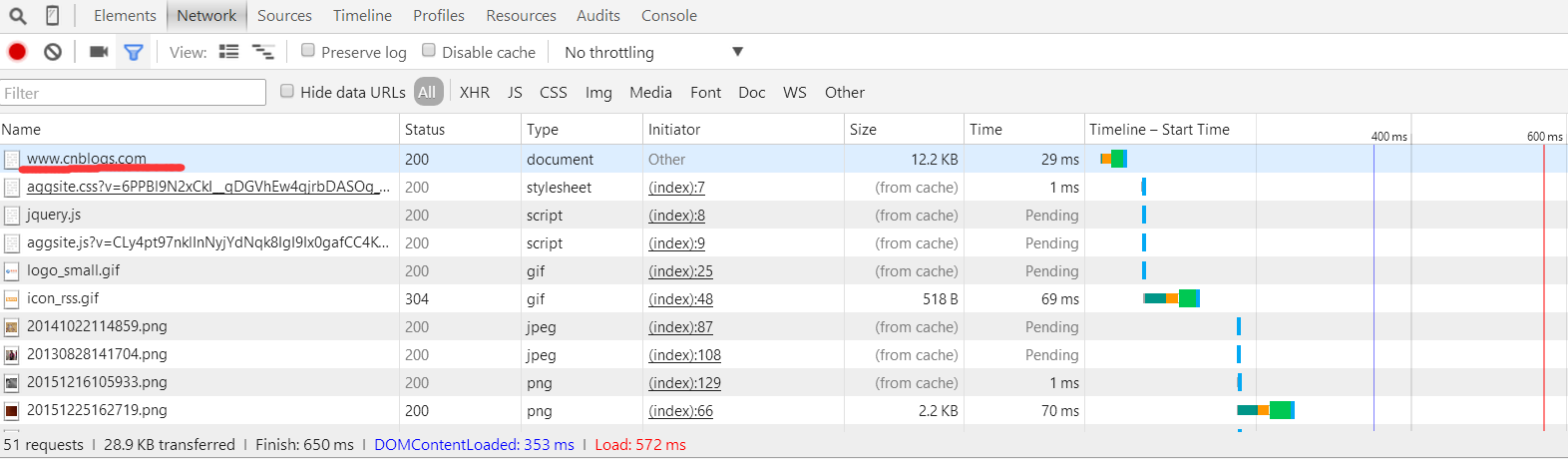
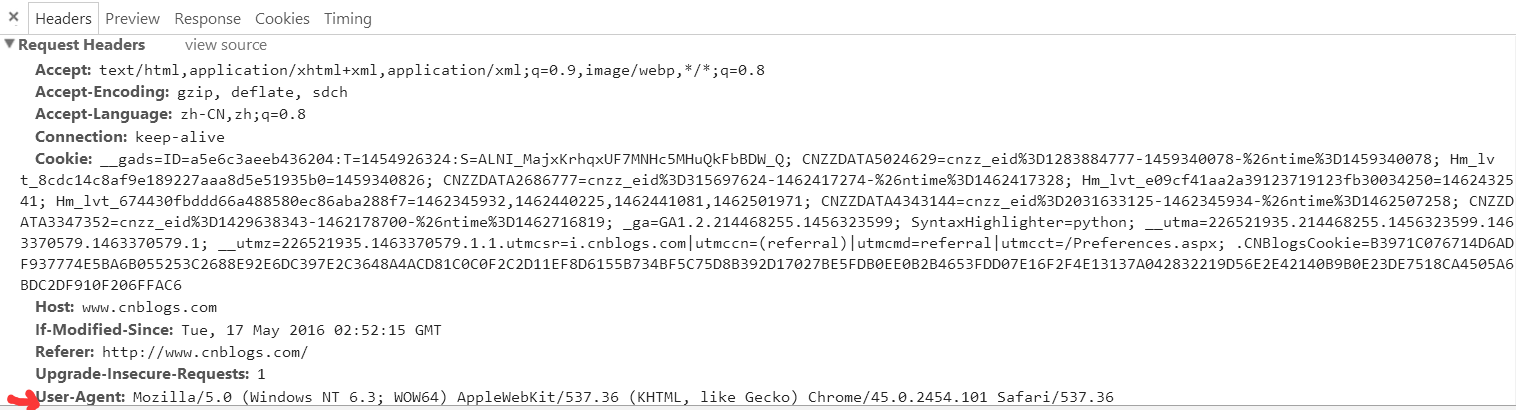
一般只需要添加User-Agent这一信息就足够了,headers同样也是字典类型;
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = { 'User-Agent' : user_agent }
二、data获取
以博客园登录界面为例:http://passport.cnblogs.com/user/signin?ReturnUrl=http%3A%2F%2Fwww.cnblogs.com%2F
按下F12键,如下图所示:
点击Network,然后随意输入用户名和密码,点击登录可以看到如下图所示:

博客园登录的data信息:
data={
input1:"*******",
input2:"*******",
remember:"false"
}
以电驴下载网站为例:http://secure.verycd.com/signin?error_code=emptyInput&continue=http://www.verycd.com/
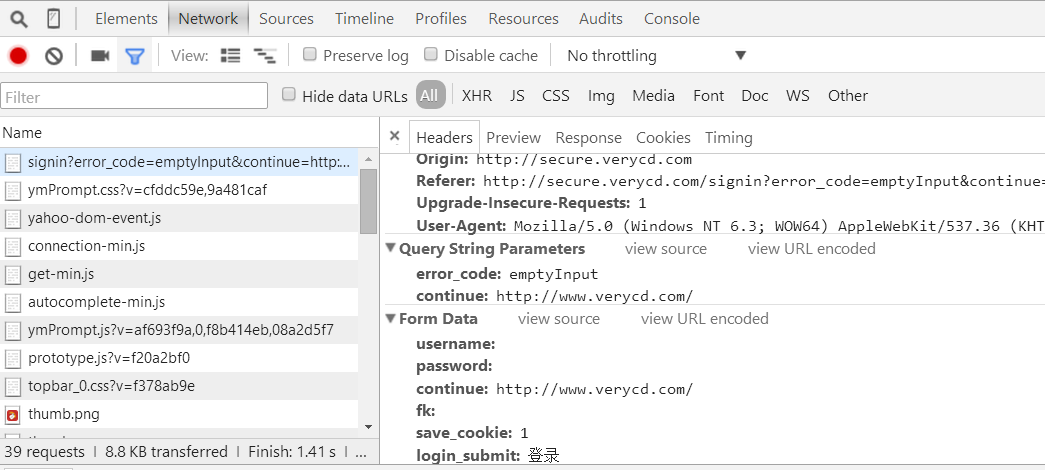
data信息在From Data标签中:

data={
username:"****",
password:"****",
continue:"http://www.verycd.com/"
fk:" ",
save_cookie:1,
login_submit:"登录"
}
每一个登录网站的data信息不一定一样,都需要进入网页确定。
好啦,今天就到这了~明天介绍一个实例:如何爬取糗百的段子。
转载时注明原作者出处:Maple2cat|Python爬虫学习:四、headers和data的获取