redis中的map存储大量数据会有什么问题
Map{Key,filed,Value}
在redis集群中,是对Key做的hash,也就是说同一个key下的不同的field会落到集群中的某一个实例上,这时,如果这个key对应的field过多,导致数据不均匀。
针对上述情况,可以对数据进行partition,步骤如下:
1.提前设置好partition的数量N
2.对filed进行hash处理,得到hashcode
3.使用hashcode%N,得到一个partition值
4.将Key和partition合并生成key,KeyWithPartition
5.将数据存入该KeyWithPartition下面
这样可以将数据设置的均匀一些。
缺点:这样会增加key的数量,但是,这个影响应该不大。
Redis 数据类型分为:字符串类型、散列类型、列表类型、集合类型、有序集合类型。

Redis五种数据结构如下:

对redis来说,所有的key(键)都是字符串。
1.String 字符串类型
是redis中最基本的数据类型,一个key对应一个value。
String类型是二进制安全的,意思是 redis 的 string 可以包含任何数据。如数字,字符串,jpg图片或者序列化的对象。
使用:get 、 set 、 del 、 incr、 decr 等

127.0.0.1:6379> set hello world OK 127.0.0.1:6379> get hello "world" 127.0.0.1:6379> del hello (integer) 1 127.0.0.1:6379> get hello (nil) 127.0.0.1:6379> get counter "2" 127.0.0.1:6379> incr counter (integer) 3 127.0.0.1:6379> get counter "3" 127.0.0.1:6379> incrby counter 100 (integer) 103 127.0.0.1:6379> get counter "103" 127.0.0.1:6379> decr counter (integer) 102 127.0.0.1:6379> get counter "102"
实战场景:
1.缓存: 经典使用场景,把常用信息,字符串,图片或者视频等信息放到redis中,redis作为缓存层,mysql做持久化层,降低mysql的读写压力。
2.计数器:redis是单线程模型,一个命令执行完才会执行下一个,同时数据可以一步落地到其他的数据源。
3.session:常见方案spring session + redis实现session共享,
2.Hash (哈希)
是一个Mapmap,指值本身又是一种键值对结构,如 value={{field1,value1},......fieldN,valueN}}
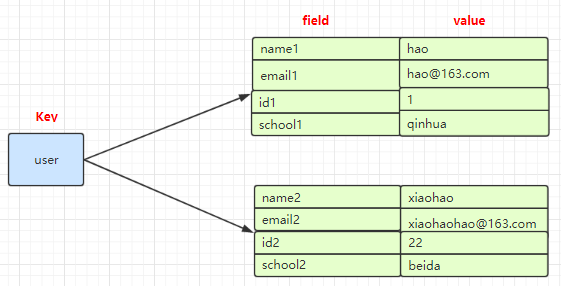
使用:所有hash的命令都是 h 开头的 hget 、hset 、 hdel 等
127.0.0.1:6379> hset user name1 hao (integer) 1 127.0.0.1:6379> hset user email1 hao@163.com (integer) 1 127.0.0.1:6379> hgetall user 1) "name1" 2) "hao" 3) "email1" 4) "hao@163.com" 127.0.0.1:6379> hget user user (nil) 127.0.0.1:6379> hget user name1 "hao" 127.0.0.1:6379> hset user name2 xiaohao (integer) 1 127.0.0.1:6379> hset user email2 xiaohao@163.com (integer) 1 127.0.0.1:6379> hgetall user 1) "name1" 2) "hao" 3) "email1" 4) "hao@163.com" 5) "name2" 6) "xiaohao" 7) "email2" 8) "xiaohao@163.com"
实战场景:
1.缓存: 能直观,相比string更节省空间,的维护缓存信息,如用户信息,视频信息等。
3.链表
List 说白了就是链表(redis 使用双端链表实现的 List),是有序的,value可以重复,可以通过下标取出对应的value值,左右两边都能进行插入和删除数据。
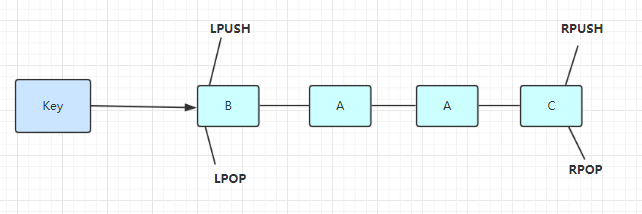
使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
使用:
127.0.0.1:6379> lpush mylist 1 2 ll ls mem (integer) 5 127.0.0.1:6379> lrange mylist 0 -1 1) "mem" 2) "ls" 3) "ll" 4) "2" 5) "1" 127.0.0.1:6379>
实战场景:
1.timeline:例如微博的时间轴,有人发布微博,用lpush加入时间轴,展示新的列表信息。
4.Set 集合
集合类型也是用来保存多个字符串的元素,但和列表不同的是集合中 1. 不允许有重复的元素,2.集合中的元素是无序的,不能通过索引下标获取元素,3.支持集合间的操作,可以取多个集合取交集、并集、差集。
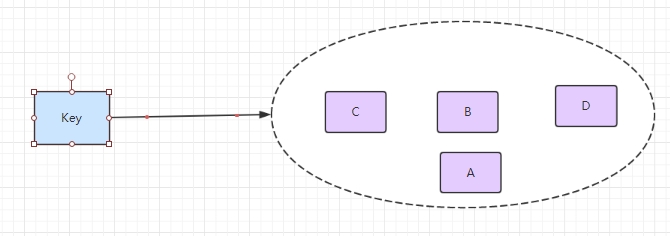
使用:命令都是以s开头的 sset 、srem、scard、smembers、sismember
127.0.0.1:6379> sadd myset hao hao1 xiaohao hao (integer) 3 127.0.0.1:6379> SMEMBERS myset 1) "xiaohao" 2) "hao1" 3) "hao" 127.0.0.1:6379> SISMEMBER myset hao (integer) 1
实战场景;
1.标签(tag),给用户添加标签,或者用户给消息添加标签,这样有同一标签或者类似标签的可以给推荐关注的事或者关注的人。
2.点赞,或点踩,收藏等,可以放到set中实现
5.zset 有序集合
有序集合和集合有着必然的联系,保留了集合不能有重复成员的特性,区别是,有序集合中的元素是可以排序的,它给每个元素设置一个分数,作为排序的依据。
(有序集合中的元素不可以重复,但是score 分数 可以重复,就和一个班里的同学学号不能重复,但考试成绩可以相同)。
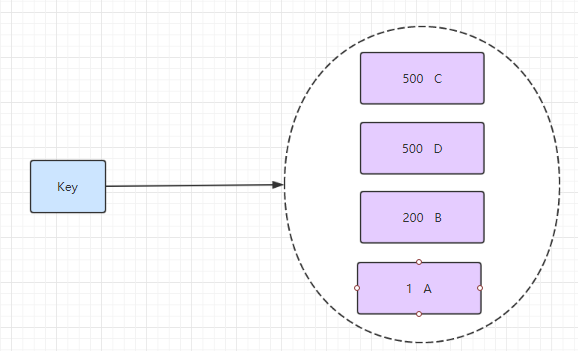
使用: 有序集合的命令都是 以 z 开头 zadd 、 zrange、 zscore
127.0.0.1:6379> zadd myscoreset 100 hao 90 xiaohao (integer) 2 127.0.0.1:6379> ZRANGE myscoreset 0 -1 1) "xiaohao" 2) "hao" 127.0.0.1:6379> ZSCORE myscoreset hao "100"
实战场景:
1.排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。