终于开始复习DOM的知识了,这一阵忙乎论文,基本都没好好看技术的书。
记得去年实习的时候,才开始真正的接触前端,发现原来JS可以使用的如此灵活。
说起DOM就不得不提起javascript的组成了,javascript是由三部分组成的:
1 ECMAScript
2 BOM
3 DOM
最开始,网页是由HTML这种静态的标签语言组成的,后来为了丰富网页,引入了Script脚本语言。
但由于浏览器厂商太多,每个厂商都使用自己的语言,导致script的语言种类繁多,最终由Netscape和sun对Script进行标准化,推出ECMAScript。
而后的浏览器大战使得DOM成为一种规范。
简单的说:
ECMAScript是一种javascript基本的核心,BOM是针对浏览器的javascript,而DOM则是针对文档对象的javascript。
下面就针对DOM做一下简单的介绍
在DOM中认为html中所有标签都是对象,整个HTML网页就是一颗文档树。
每一个标签都是这个文档中的一个对象,每个标签由元素节点、属性节点和文本节点组成。
元素节点:定义了该标签的类型
属性节点:定义了标签中的属性
文本节点:定义了标签所包含的文本,是标签的主要显示内容
他们的关系如下图所示:

关于DOM,最常用的四个方法:
1 getElementById() 通过标签中的id名称,获取节点对象
2 getElementsByTagName() 通过标签名字,获取节点对象的数组
3 getAttribute() 获取对象的某个属性
4 setAttribute() 设置对象的某个属性
例如下面的样例代码:
<!doctype html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Shopping list</title>
<style type="text/css">
p {
color:yellow;
font-family: "arial",sans-serif;
font-size: 1.2em;
}
body {
color:white;
background-color: black;
}
.special {
font-style: italic;
}
h2.special {
text-transform: uppercase;
}
#purchases {
border:1px solid white;
background-color: #333;
color: #ccc;
padding:1em;
}
#purchases li {
font-weight: bold;
}
</style>
</head>
<body>
<h1>What to buy!</h1>
<p title="a gentle reminder">Don't forget to buy this stuff.</p>
<ul id="purchases">
<li>A tin of beans</li>
<li>Cheese</li>
<li>Milk</li>
</ul>
<ul id="test">
<li>A tin of beans</li>
<li>Cheese</li>
<li>Milk</li>
</ul>
<p class="special">This paragraph has the special class</p>
<h2 class="special">So does this headline</h2>
<script type="text/javascript">
var purchases = document.getElementById("purchases");
console.log(purchases);
var liItems1 = document.getElementsByTagName("li");
console.log(liItems1);
var liItems2 = purchases.getElementsByTagName("*");
console.log(liItems2);
var pItems = document.getElementsByTagName("p");
for(var i=0;i<pItems.length;i++){
console.log(pItems[i].getAttribute("title"));
}
var pSpecial = pItems[pItems.length-1];
pSpecial.setAttribute("title","my special title");
for(var i=0;i<pItems.length;i++){
console.log(pItems[i].getAttribute("title"));
}
</script>
</body>
</html>
通过上面的代码,可以更明显的了解这四个方法的作用,页面效果如下:
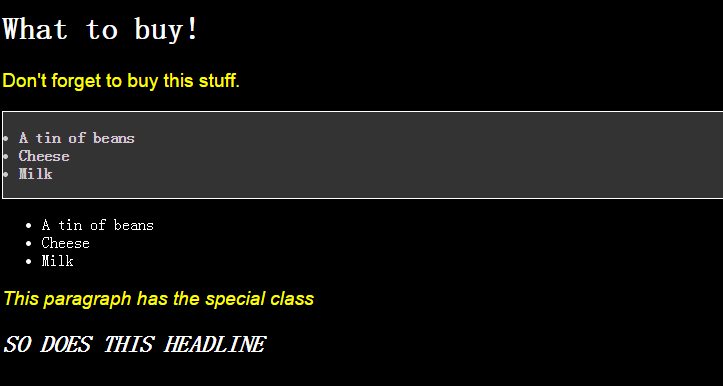
getElementsById()
通过getElementById()可以返回该id所在的节点对象,在html中id是唯一的,不能重复,因此通过这个方法肯定只能得到一个对象。
因此下面的代码:
var purchases = document.getElementById("purchases"); console.log(purchases);
将会得到如下的结果:
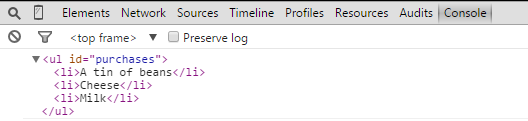
getElementsByTagName()
再看getElementsByTagName(),这个是返回标签对应的所有对象集合,因此方法名字是Elements!
var liItems1 = document.getElementsByTagName("li"); console.log(liItems1); var liItems2 = purchases.getElementsByTagName("*"); console.log(liItems2);
上面的代码中,第一个方法获得是整个文档的li对象集合,而第二个方法是purchases对象中包含的li集合。
因此,第一个方法获得了6个li对象,而第二个方法中只有三个。

另外可以看到,这个方法返回的集合中有一个属性,length,可以获得集合的长度。
getAttribute()
这个方法只能由对象来调用,但是不能是document对象。因此通常是使用getElementById获得指定id的对象,在调用该方法。
两个方法搭配,可以获得该对象的特定属性。
var pItems = document.getElementsByTagName("p"); for(var i=0;i<pItems.length;i++){ console.log(pItems[i].getAttribute("title")); }
上面代码中,获取了p标签的对象集合,上文示例代码中有两个p标签,因此这个集合包含两个对象。而只有第一个对象包含title属性。
因此会得到如下的结果:

setAttribute()
类似上面的getAttribute方法,只能由对象来调用。
var pSpecial = pItems[pItems.length-1]; pSpecial.setAttribute("title","my special title"); for(var i=0;i<pItems.length;i++){ console.log(pItems[i].getAttribute("title")); }
上面的代码,仅仅作为参考:由于第二个对象没有title属性,因此为他设置titel属性后,得到如下的内容:

需要注意的是,由于DOM是在页面加载完静态代码文件后动态刷新生成的,因此DOM所做的操作,并不会改变源代码的内容。
参考
参考书籍:《JavaScript DOM编程艺术》