上一节我们讲到了Eureka 注册中心服务端的配置,接下来我们进行Eureka客户端的配置
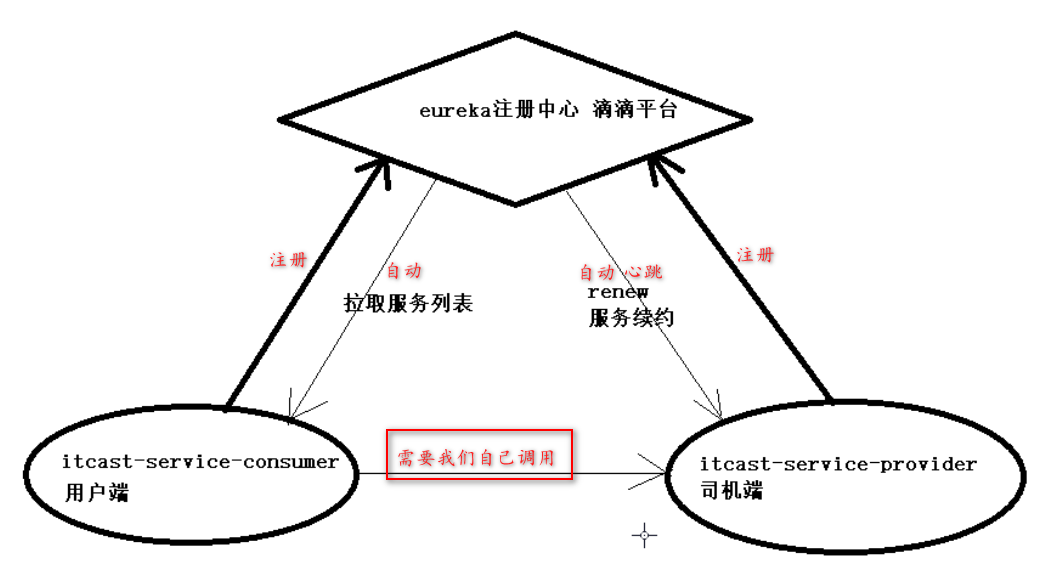
服务提供者和服务消费者两个工程都属于客户端(这就好比滴滴出行的司机端和用户端,都是客户端)需要把他们分别注册到Eureka中
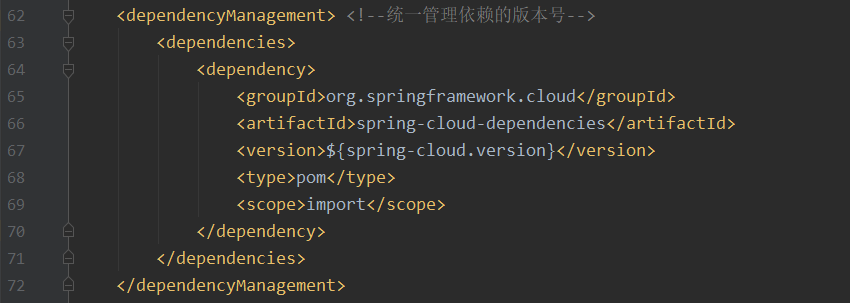
这里也是参考服务端的pom那样,把版本统一管理两个pom.xml本次加的内容一样,故这里只截图其中一个
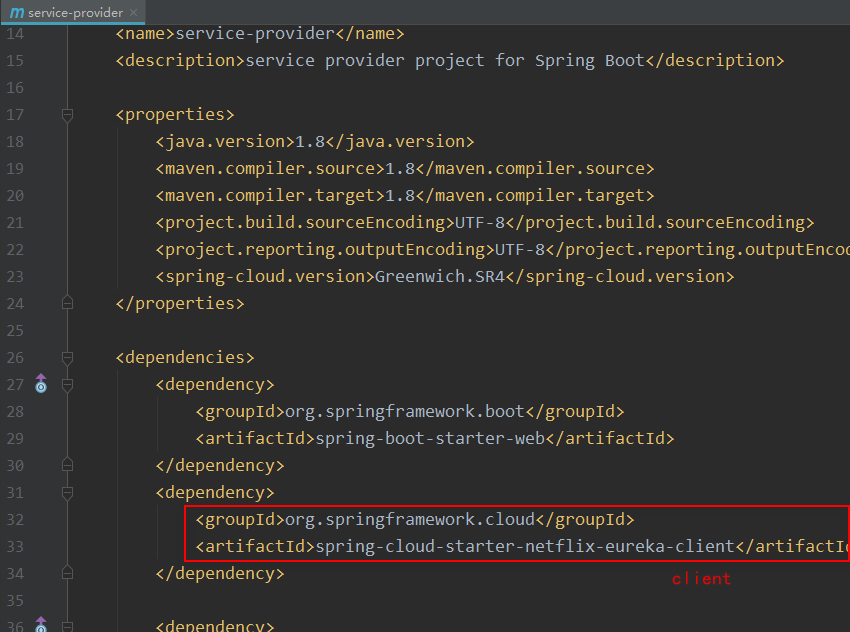
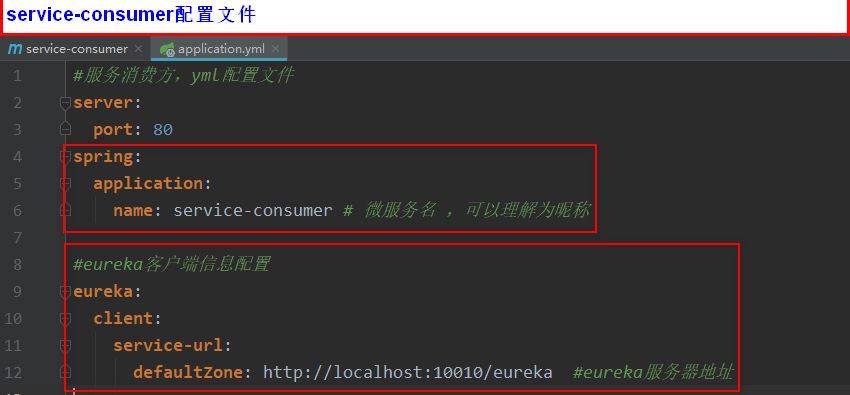
provider的配置文件

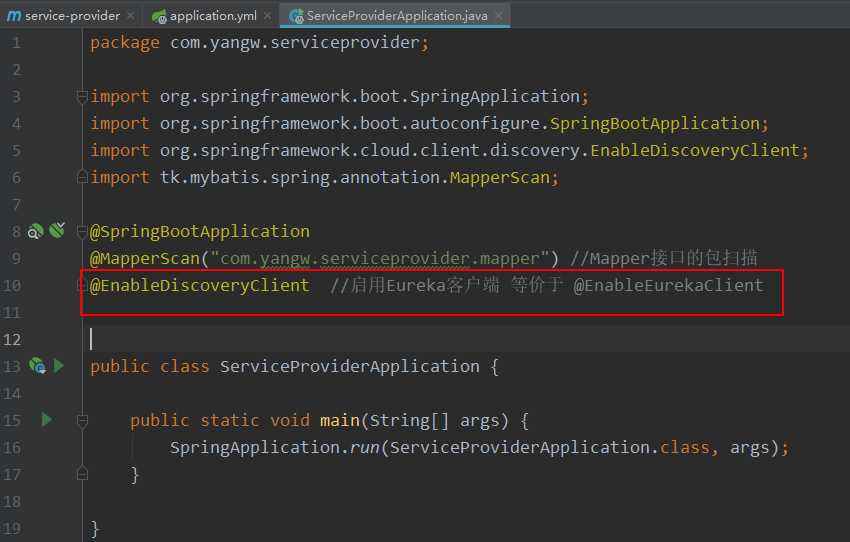
provider引导类:
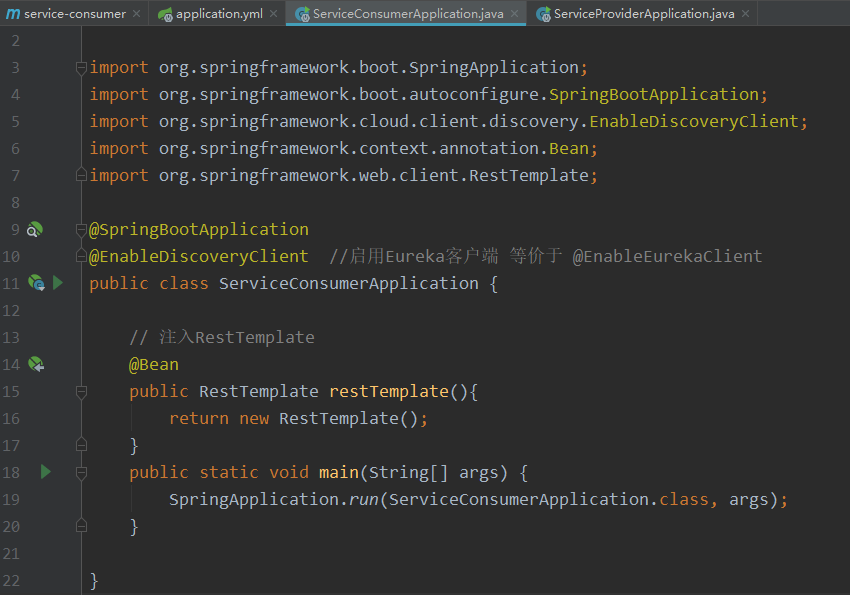
测试
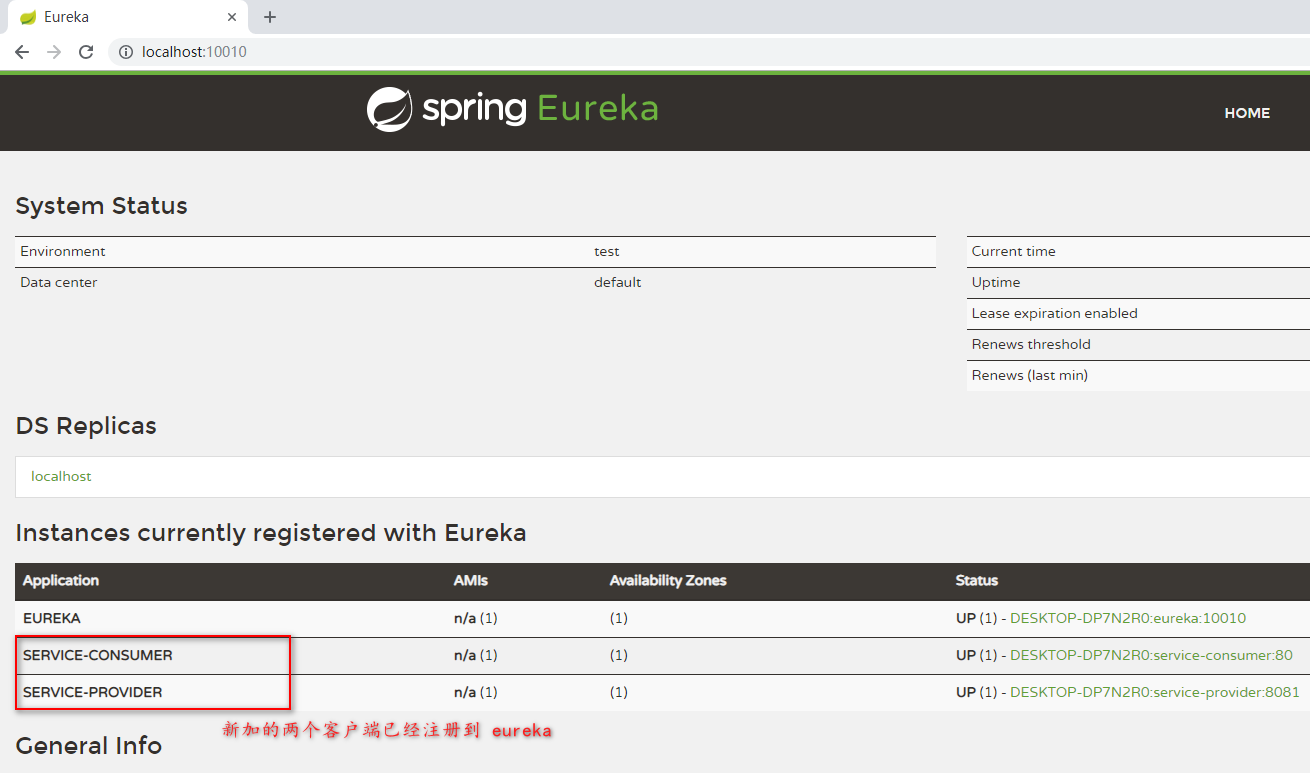
在开发环境如何实现高可用测试呢?了解内容
因为一个运行实例就是一个tomcat,所以我们只需要拷贝一下运行实例即可,
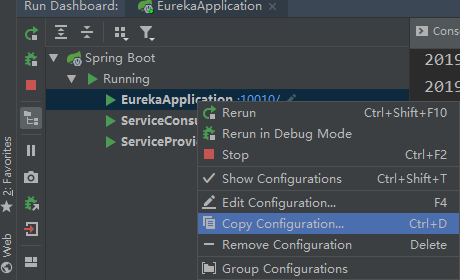
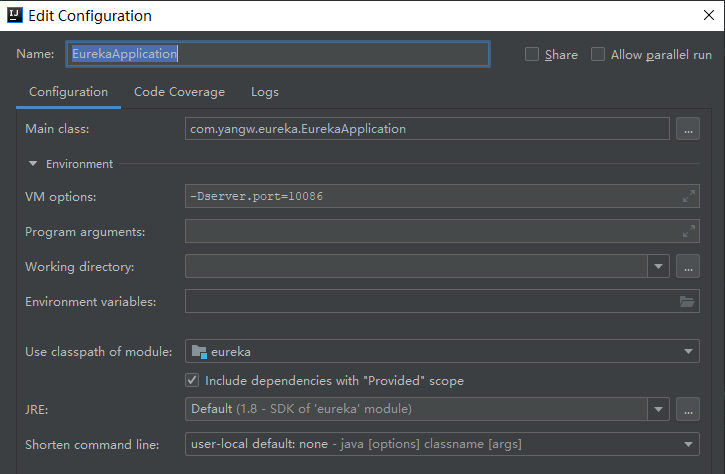
把配置文件中的 server.port去掉,将它配置到vm参数中,如上图,然后注册地址改成对方地址
改的是同一个项目的配置文件哦,改了之后启动,然后紧接着再改,改了再启动另一个实例
也可以这样改这段【-Dspring.profiles.active=peer2 -Dserver.port=8762】配置指定了Eureka Server实例启动时使用的配置文件、端口号,peer2就是配置文件的名称,下一步会创建这个配置文件。
https://blog.csdn.net/lihailin9073/article/details/100712996 (具体看这篇文章)

-
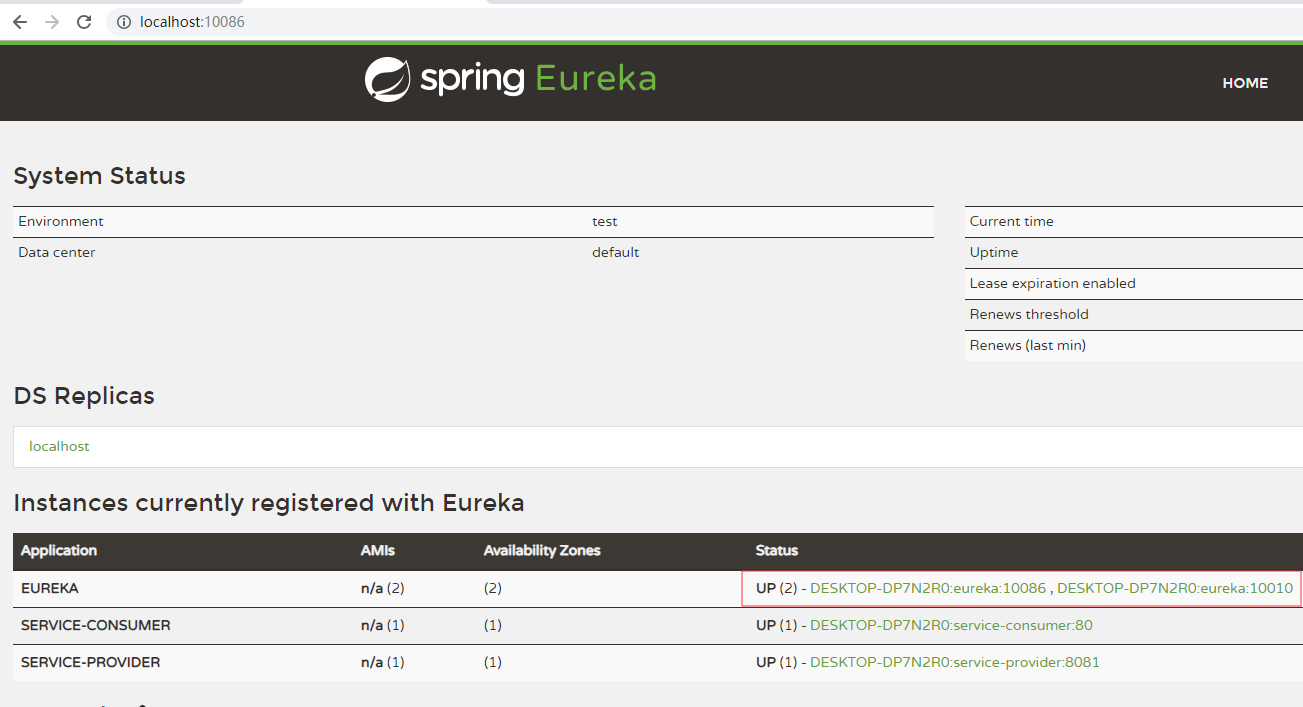
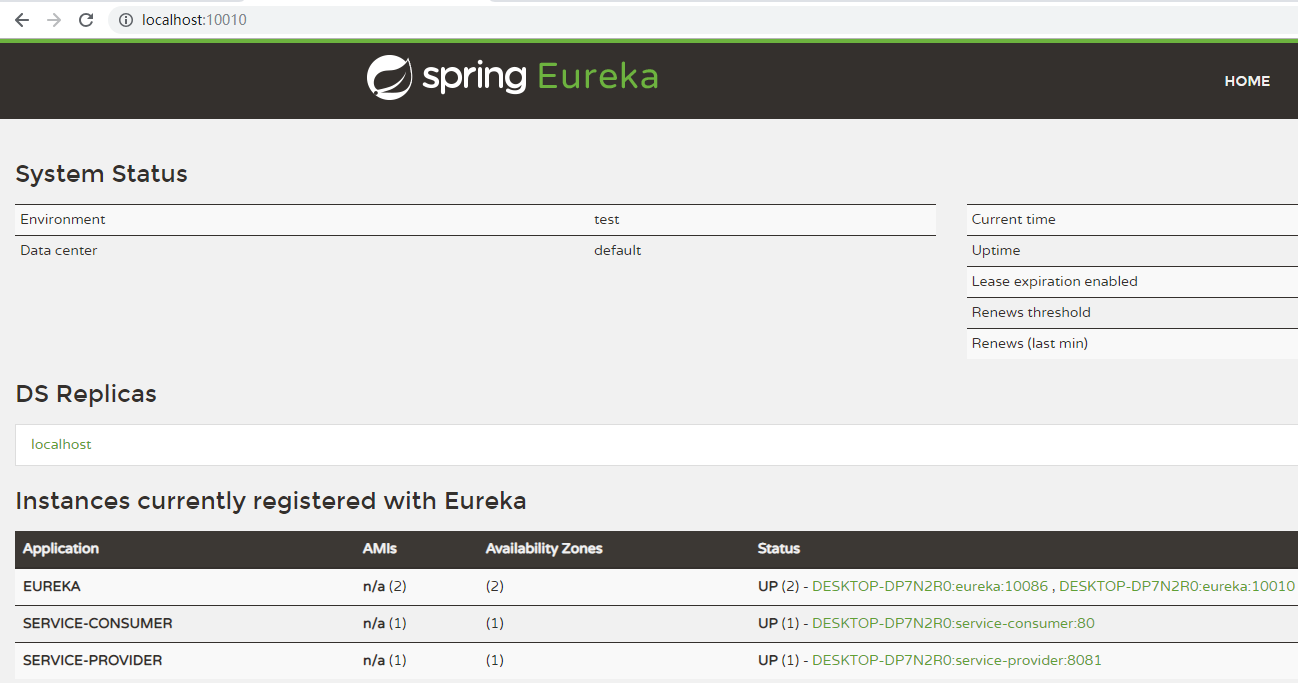
第一层Map的Key就是服务id,一般是配置中的
spring.application.name属性 -
第二层Map的key是服务的实例id。一般host+ serviceId + port,例如:
locahost:service-provider:8081 -
值则是服务的实例对象,也就是说一个服务,可以同时启动多个不同实例,形成集群。
在注册服务完成以后,服务提供者会维持一个心跳(定时向EurekaServer发起Rest请求),告诉EurekaServer:“我还活着”。这个我们称为服务的续约(renew);
有两个重要参数可以修改服务续约的行为:
eureka
-
lease-renewal-interval-in-seconds:服务续约(renew)的间隔,默认为30秒
-
lease-expiration-duration-in-seconds:服务失效时间,默认值90秒
也就是说,默认情况下每个30秒服务会向注册中心发送一次心跳,证明自己还活着。如果超过90秒没有发送心跳,EurekaServer就会认为该服务宕机,会从服务列表中移除,这两个值在生产环境不要修改,默认即可。
但是在开发时,这个值有点太长了,经常我们关掉一个服务,会发现Eureka依然认为服务在活着。所以我们在开发阶段可以适当调小。
eureka
eureka
生产环境中,我们不需要修改这个值。
负载均衡 Ribbon
Eureka中已经帮我们集成了负载均衡组件 Ribbon,
Ribbon是Netfiix发布的负载均衡器,它有助于控制HTTP和TCP客户端的行为,为Ribbon配置服务提供者地址列表后,Ribbon就可基于某种负载均衡算法,自动帮助服务消费者去请求。它默认提供了多种算法,如轮询/随机,当然也可以自定义算法。
如何使用Ribbon呢?
1,首先我们用上面同样的方法,将服务提供者拷贝一份,在8082端口上启动,这样服务端才有了两个;
2,然后我们再在消费者端使用负载均衡器,默认情况下 Eureka已经集成了Ribbon,可以在Eureka的包中看到
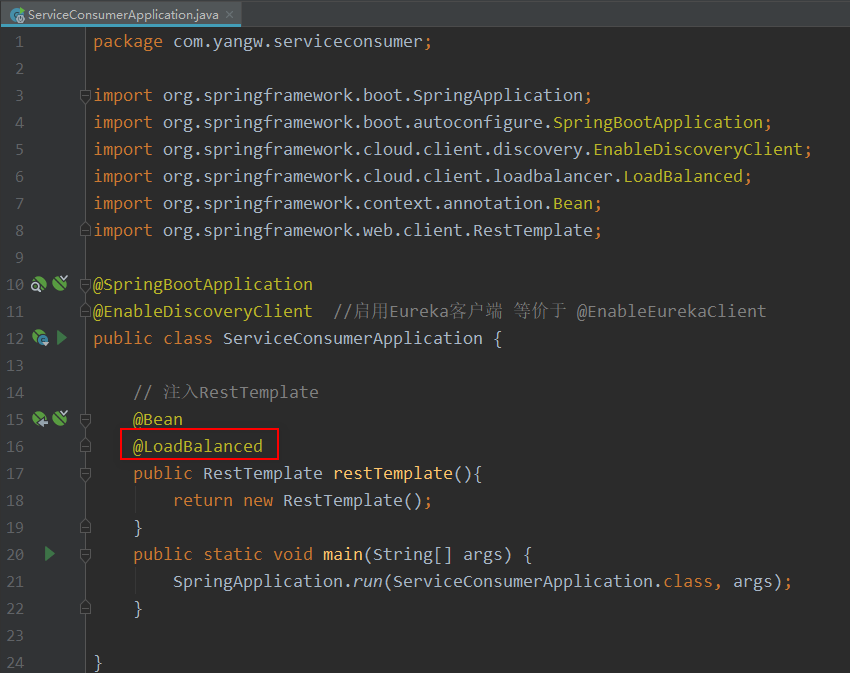
3,无需覆盖消费者的默认配置,加注解(这里比较特殊,不是加在引导类上,而是在RestTemplate方法上 @LoadBalanced)
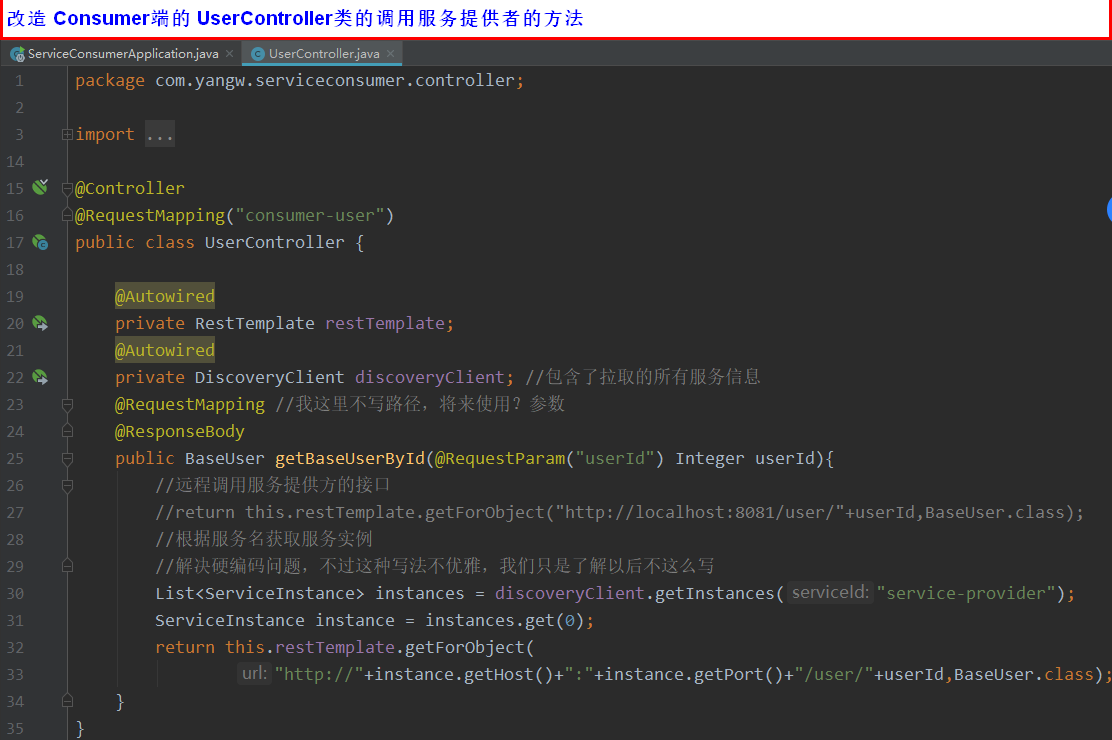
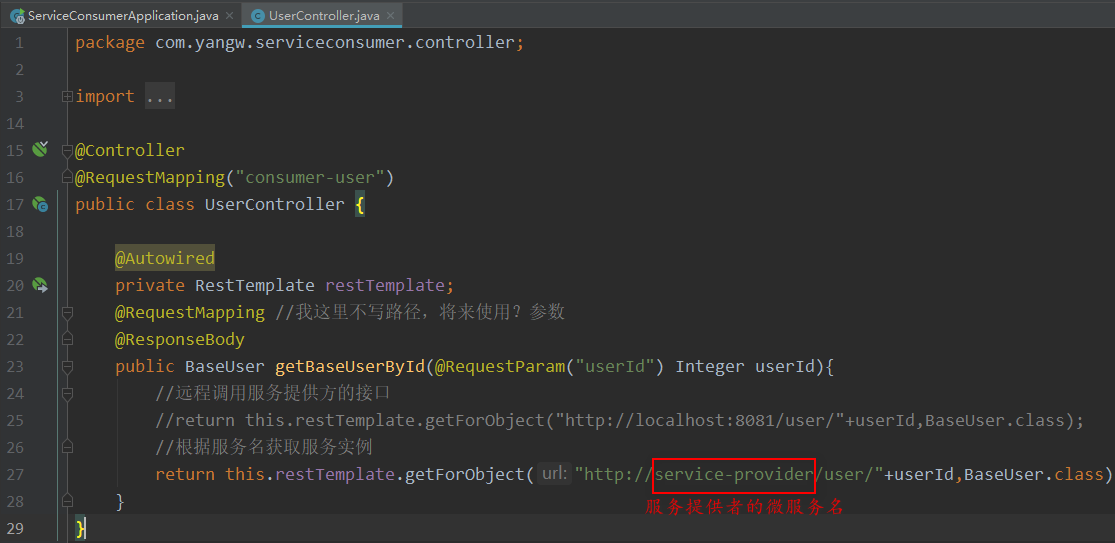
4,修改Controller的调用方式,这里直接使用服务名调用,注释掉上次那个Host+Port的拼接。
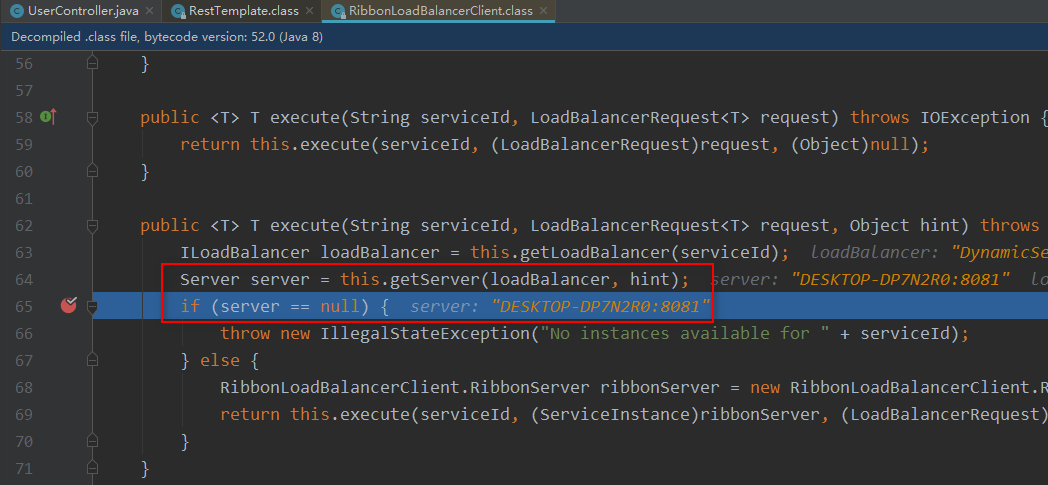
通过断点跟踪发现,执行的是如下代码
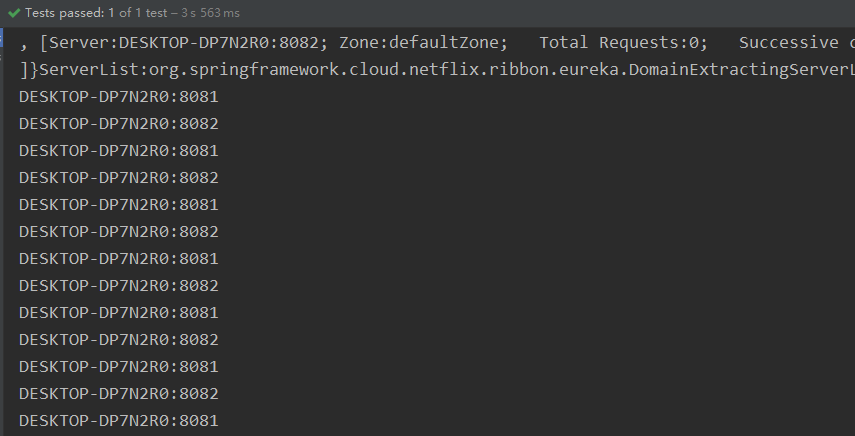
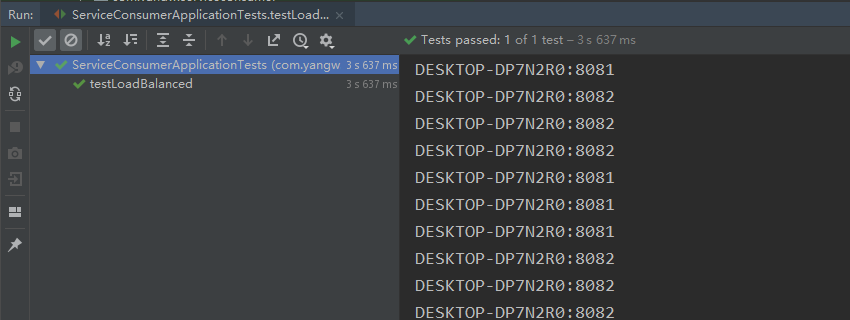
下来我们可以写个测试来,来观察系统提供的负载均衡策略。(默认是轮询, 系统还提供了随机)

i%count,来决定用哪一个
如果你要想实现负载均衡器,实现接口IRule.
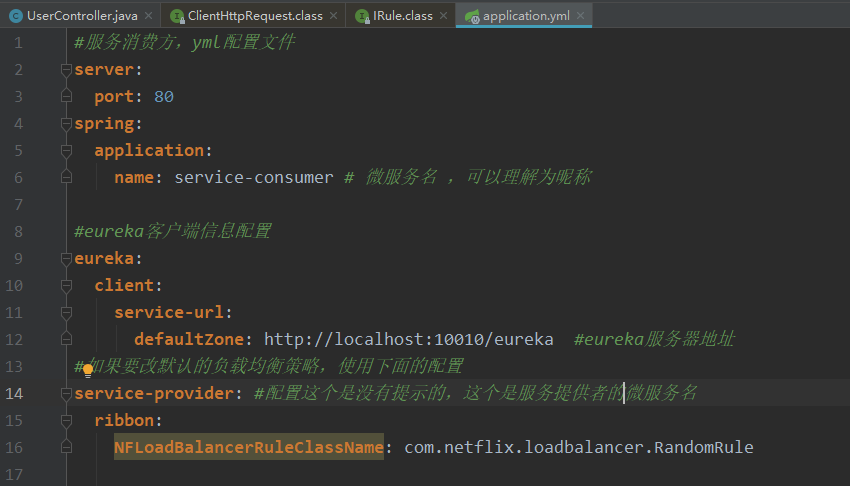
更改Consumer的配置文件负载均衡策略,并运行测试类看结果
Hystix也是Netflix公司的组件
Hystix是Netflix开源的一个延迟和容错库,用于隔离访问远程服务、第三方库、防止出现级联失败。
雪崩问题: 看这篇文章的图解 https://cloud.tencent.com/developer/article/1445716
Hystix解决雪崩问题的手段两种 线程隔离,服务熔断
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,或者请求超时,则会进行降级处理,什么是服务降级?
服务降级:优先保证核心服务,而非核心服务不可用或弱可用。
用户的请求故障时,不会被阻塞,更不会无休止的等待或者看到系统崩溃,至少可以看到一个执行结果(例如返回友好的提示信息) 。
服务降级虽然会导致请求失败,但是不会导致阻塞,而且最多会影响这个依赖服务对应的线程池中的资源,对其它服务没有响应。
触发Hystix服务降级的情况:
-
线程池已满
-
请求超时
在服务调用方(消费者方)配置 Hystix

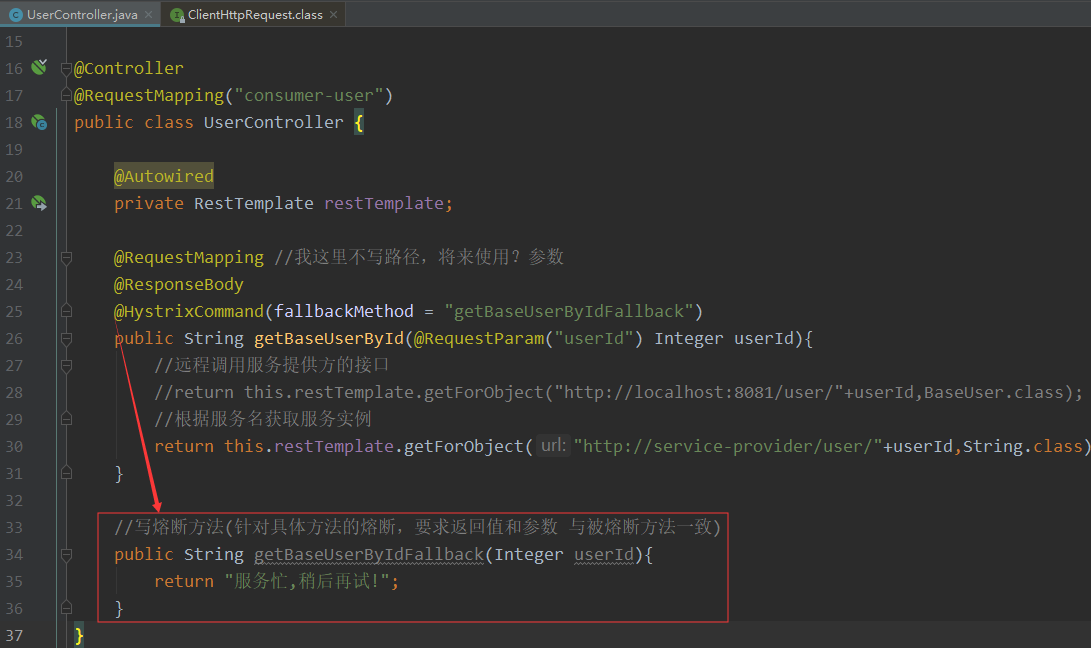
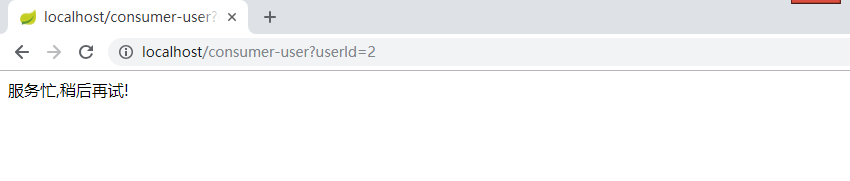
我们测试超时情况的熔断,关掉服务提供者服务,重启消费者端,然后浏览器访问
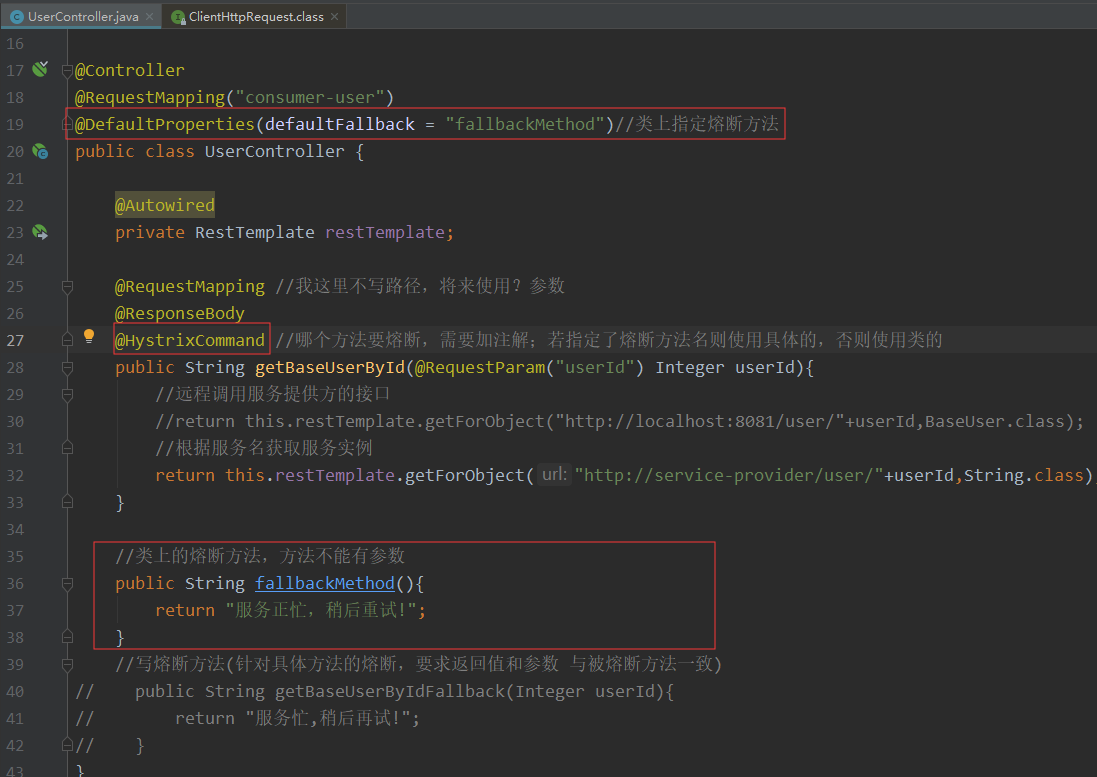
上面是在方法上的熔断,如果每个方法都写熔断不太现实,此时我们可以在类上加熔断
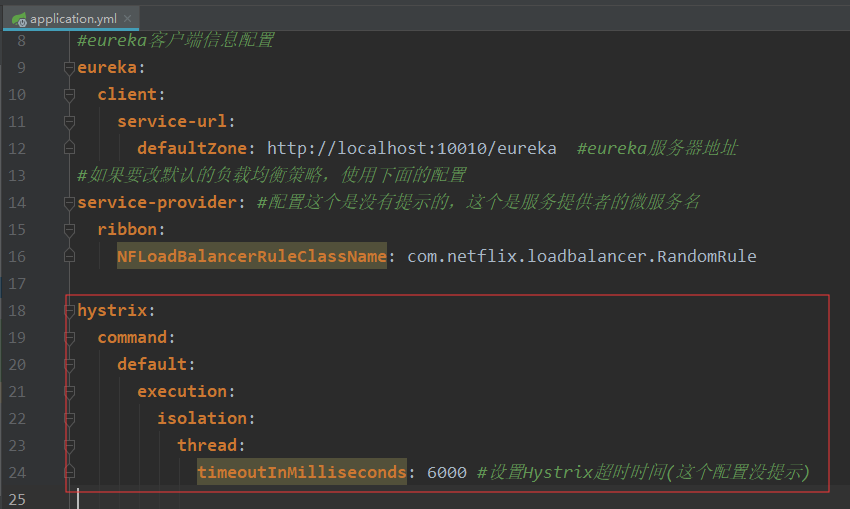
我们可以通过hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds来设置Hystrix超时时间。毫秒值。
如果要测试这个效果,就把服务提供者开启来,然后在它的方法里面睡眠一段时间,睡眠时间值大于设置的超时时间.
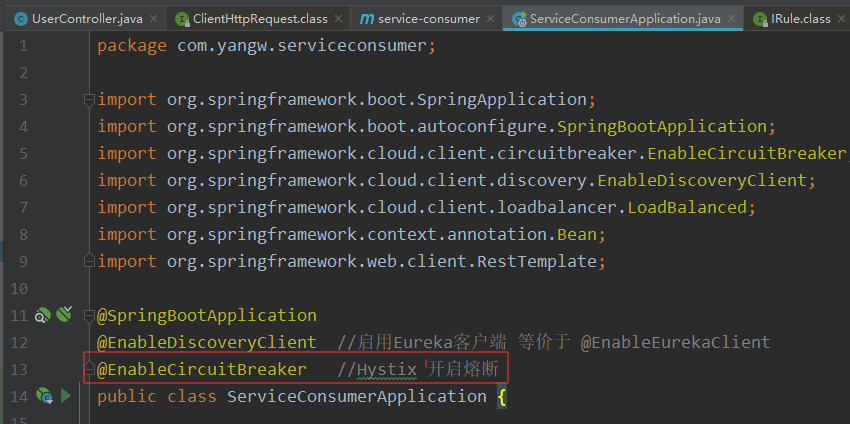
@SpringCloudApplication组合注解,它相当于 @SpringBootApplication @EnableDiscoveryClient @EnableCircuitBreaker
熔断器,也叫断路器,其英文单词为:Circuit Breaker
‘生活中典型的例子 就是 电路保险丝
-
Closed:关闭状态,所有请求都正常访问。
-
Open:打开状态,所有请求都会被降级。Hystix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器会完全打开。默认失败比例的阈值是50%,请求次数最少不低于20次。
-
Half Open:半开状态,open状态不是永久的,打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放部分请求通过,若这些请求都是健康的,则会完全关闭断路器,否则继续保持打开,再次进行休眠计时
不过,默认的熔断触发要求较高,休眠时间窗较短,为了测试方便,我们可以通过配置修改熔断策略
circuitBreaker.requestVolumeThreshold=10 触发熔断的最小请求次数,默认20
circuitBreaker.sleepWindowInMilliseconds=10000 触发熔断的失败请求最小占比,默认50%
circuitBreaker.errorThresholdPercentage=50 休眠时长,默认是5000毫秒
为了能够精确控制请求的成功或失败,我们在consumer的调用业务中加入一段逻辑
@GetMapping("{id}")
@HystrixCommand
public String queryUserById(@PathVariable("id") Long id){
if(id == 1){
throw new RuntimeException("太忙了");
}
String user = this.restTemplate.getForObject("http://service-provider/user/" + id, String.class);
return user;
}
我们准备两个请求窗口:
-
一个请求:http://localhost/consumer/user/1,注定失败
-
一个请求:http://localhost/consumer/user/2,肯定成功
当我们疯狂访问id为1的请求时(超过20次),就会触发熔断。断路器会断开,一切请求都会被降级处理。
此时你访问id为2的请求,会发现返回的也是失败,而且失败时间很短,只有几毫秒左右