PO模式优化
退出登录
退出登录放到哪个页面呢?
common里面,登录页面,主页?
common是封装逻辑相关的,跟业务无关
退出页面不在登录页面里面
主页,可以考虑,通过观察发现,主页上面的面包屑里面,任务,日程,公告都可以退出登录
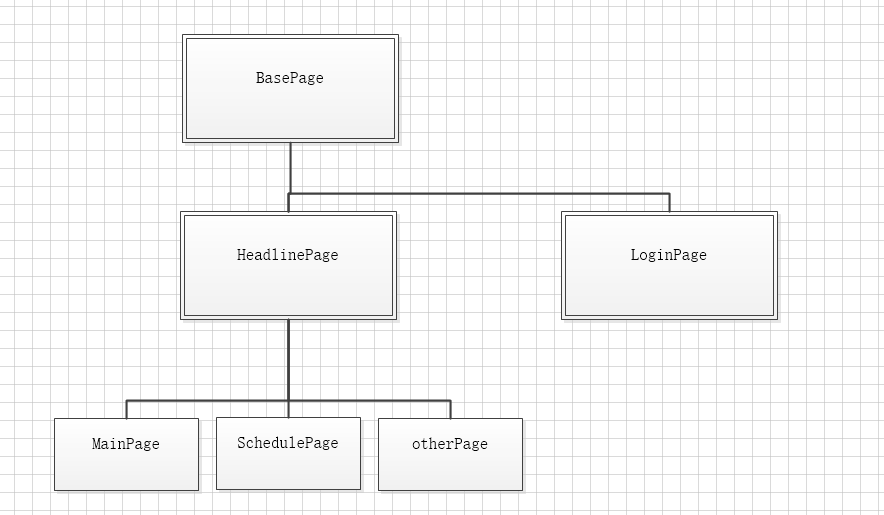
退出登录属于公共部分,在开发中属于页面头部公共部分定义为headline
最终决定把退出登录放到headline页面
封装headline类及方法
观察发现之前在mianpage里面封装的to_schedule方法也是属于headline里面的,所以需要移动到headline里面来
class MainPage(BasePage):
pass
class SchedulePage(BasePage):
def new_schedule(self,sumary,target):
#点击新建按钮
self.click(self.new_btn)
#输入主题
self.input_text(self.sumary_input,sumary)
#点击指派
self.click(self.select_btn)
time.sleep(5)
#清除已选
self.click_multi(self.selected_users)
#选择目标用户
self.select_target_by_text(self.target_users,target)
#点击确认
self.click(self.confirm_btn)
#点击保存
self.click(self.save_btn)
class HeadlinePage(BasePage):
def logout(self):
pass
def to_schedule(self):
#点击日程
self.click(self.schedule_btn)
return SchedulePage()
这样就又有一个问题,登录跳转到Mainpage页面,然后就无法跳转到schedule页面了,MainPage继承HeadlinePage
class MainPage(HeadlinePage):
pass
发现又报新错误
Unresolved reference 'HeadlinePage'
我们把HeadLinePage移到前面即可,同时SchedulePage也可以继承HeadlinePage
实现HeadlinePage
#定义业务操作类
class HeadlinePage(BasePage):
def logout(self):
pass
def to_schedule(self):
#点击日程
self.click(self.schedule_btn)
return SchedulePage()
class LoginPage(BasePage):
def __init__(self):
super().__init__()
self._driver.get(host)
def login(self,email,pwd):
self.input_text(self.email_input,email)
self.input_text(self.pwd_input,pwd)
self.click(self.login_btn)
return MainPage()#进入主页
class MainPage(HeadlinePage):
pass
class SchedulePage(HeadlinePage):
def new_schedule(self,sumary,target):
#点击新建按钮
self.click(self.new_btn)
#输入主题
self.input_text(self.sumary_input,sumary)
#点击指派
self.click(self.select_btn)
#清除已选
self.click_multi(self.selected_users)
#选择目标用户
self.select_target_by_text(self.target_users,target)
#点击确认
self.click(self.confirm_btn)
#点击保存
self.click(self.save_btn)
return self # 没有页面切换,只返回自己就可以
实现logout
#头部公共页面
class HeadlinePage(BasePage):
def logout(self):
#点击头像
self.click(self.avatar)
#点击退出
self.click(self.logout_link)
time.sleep(2)#留时间让系统退出
return LoginPage()
调试用例发现,new_schedule后无法链式调用logout方法
分析发现是new_schedule没有返回对象,创建成功后,没有页面跳转,返回自己就可以,return self
被指派的用户登录进来,直接在主页就可以查看日程
查看日程
查看日程,那就需要获取日程对应的文本,回过头来看,发现还没有封装获取列表的文本方法,需要到common中封装一个
#获取元素的文本
def get_eles_text(self,locator):
eles=self._driver.find_elements(*locator)
return [ele.text for ele in eles]#返回文本列表
class MainPage(HeadlinePage):
def get_schedules(self):
return self.get_eles_text(self.schedules)
至此为止,测试库基本封装完了,下面就是实现测试用例了
实现测试用例
在tc目录下,新增一个目录D-webUI-login,新增一个模块test_schedule.py编写测试用例
def test_tc0000051():
LoginPage().login(g_email, g_pwd).to_schedule().new_schedule('早会', '猪八戒').logout().login(
'zhubajie@test.com', '123456')
发现登录是每个业务都要操作的,那把登录作为一个公共方法
新增一个conftest.py模块,实现登录
@pytest.fixture()
def init_admin():
#登录
page=LoginPage().login(g_email, g_pwd)
return page
业务执行完,需要退出浏览器
把return 改成yield,下面还需要实现退出浏览器的操作
page.close_browser()
close方法还没有实现,需要到common里面封装
def close_browser(self):
self._driver.quit()
前面使用了单例模式来创建浏览器,当我们退出浏览器,其他业务用例再次打开浏览器,会发现打不开,原因在于退出浏览器,只是把driver驱动退出,self._driver对象引用依然存在,程序就认为你已经打开了浏览器了,想再次打开浏览器就无法打开了
解决:退出浏览器的同时清空driver对象即可
def close_browser(self):
self._driver.quit()
self._driver=None
def test_tc0000051(init_admin):
page=init_admin
schedule_list=page.to_schedule().new_schedule('晚会', '猪八戒').logout().login(
'zhubajie@test.com', '123456').get_schedules()
assert '晚会' in schedule_list
在mian.py中执行用例
pytest.main(['tc','-s','--alluredir=tmp/report','--clean-alluredir','-k test_tc0000051'])
执行发现登录页面打开很久没有响应
如果不想一直等下去,就可以设置一个超时时间来控制,超时后就抛出异常
在创建driver的时候设置
#设置浏览器加载页面超时时间
self._driver.set_page_load_timeout(60)
self._driver.set_script_timeout(60)
重新执行,执行发现报错了
def to_schedule(self):
# 点击日程
> self.click(self.schedule_btn)
E AttributeError: 'MainPage' object has no attribute 'schedule_btn'
分析发现MainPage确实没有schedule_btn这个属性,而这个属性是在HeadlinePage中,但这个属性又不是由HeadlinePage对象来调用,而是由HeadlinePage的子类MainPage来调用,那怎么解决这个问题呢
临时解决方案:同时把chedule_btn属性放到MainPage和HeadlinePage中,但是又产生一个新的问题,假如某一天,元素定位改变了,需要同时修改两个地方,假如漏改了,就会出问题
那怎么办呢?
获取继承链的属性
#读取配置文件
current_class=self.__class__.__name__
self.locators=read_yml(path)[current_class]
#动态赋值元素属性
for key in self.locators:
self.__setattr__(key,self.locators[key])# 参数:1属性,2属性值
分析发现动态赋值这个地方,只给当前类赋值,继承父类的属性
要实现赋值当前类,也要继承父类
调试一下
test_demo.py模块中进行调试
class BasePage:
def __init__(self):
print(self.__class__.__name__)#打印当前类类名
class FatherPage(BasePage):
pass
class ChildPage(FatherPage):
pass
class SubPage(ChildPage):
pass
if __name__ == '__main__':
BasePage()
输出:
D:softpython3.8python.exe "D:/py project/Merchants_combat/day6/pylib/webui/test_demo.py"
BasePage
输入:
FatherPage()
输出:
FatherPage
把打印换成如下
print(self.__class__.__base__.__name__)#打印父类名字
输入:
FatherPage()
输出:
BasePage
把打印换成如下:
print(self.__class__.mro())#获取继承链表
输入:
SubPage()
输出:
[<class '__main__.SubPage'>, <class '__main__.ChildPage'>, <class '__main__.FatherPage'>, <class '__main__.BasePage'>, <class 'object'>]
返回是一个列表,需要获取类名,使用列表生成式
把打印换成如下:
print([c.__name__ for c in self.__class__.mro()])
输入:
SubPage()
输出:
['SubPage', 'ChildPage', 'FatherPage', 'BasePage', 'object']
完整调试代码:
class BasePage:
def __init__(self):
# print(self.__class__.__name__)#打印当前类类名
# print(self.__class__.__base__.__name__)#打印父类名字
# print(self.__class__.mro())#获取继承链表
print([c.__name__ for c in self.__class__.mro()])
class FatherPage(BasePage):
pass
class ChildPage(FatherPage):
pass
class SubPage(ChildPage):
pass
if __name__ == '__main__':
SubPage()
现在就可以把获取继承链的方法拿到common中使用了
[c.name for c in self.class.mro()]
#读取配置文件
class_names=[c.__name__ for c in self.__class__.mro()]
for class_name in class_names:
self.locators=read_yml(path)[class_name]
#动态赋值元素属性
for key in self.locators:
self.__setattr__(key,self.locators[key])# 参数:1属性,2属性值
但是发现'BasePage', 'object'是不需要进行元素属性赋值的,需要过滤掉,使用切片就可以解决
class_names=[c.name for c in self.class.mro()][:-2]
再次测试用例,用例通过
数据驱动
case_data/webui_params.yml
Schedule:
name:
- 晚会1
- 晚会2
- 晚会3
- 晚会4
@pytest.mark.parametrize('summary',read_yml('case_data/webui_params.yml')['Schedule']['name'])
def test_tc0000051(init_admin,summary):
page=init_admin
schedule_list=page.to_schedule().new_schedule(summary, '猪八戒').logout().login(
'zhubajie@test.com', '123456').get_schedules()
assert summary in schedule_list
page.logout()
执行第二条用例数据报错了
summary = '晚会2'
@pytest.mark.parametrize('summary',read_yml('case_data/webui_params.yml')['Schedule']['name'])
def test_tc0000051(init_admin,summary):
page=init_admin
> schedule_list=page.to_schedule().new_schedule(summary, '猪八戒').logout().login(
'zhubajie@test.com', '123456').get_schedules()
pylibwebuiusiness.py:22: in to_schedule
self.click(self.schedule_btn)
原因:logout回到登录页面,to_schedule()是需要在登录后的主页进行操作,但是用例在执行第二条数据的时候,没有执行登录的方法,导致没有跳转到主页,然后to_schedule()找不到元素
解决:
需要对初始化环境的逻辑进行优化
优化环境初始化逻辑和用例setup
conftest只生成一个页面,然后在用例的setup方法里面登录和登出
@pytest.fixture(scope='session')
def init_page():
#登录
page=LoginPage()
yield page
page.close_browser()
@pytest.fixture()
def before_test_tc0000051(init_page):
page=init_page
main_page=page.login(g_email,g_pwd)
yield main_page
main_page.logout()
执行发现在指派的地方报错
@pytest.mark.parametrize('summary',read_yml('case_data/webui_params.yml')['Schedule']['name'])
def test_tc0000051(before_test_tc0000051,summary):
page=before_test_tc0000051
> schedule_list=page.to_schedule().new_schedule(summary, '猪八戒').logout().login(
'zhubajie@test.com', '123456').get_schedules()
tcD-webUI-login est_schedule.py:21:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
pylibwebuiusiness.py:54: in new_schedule
self.click_multi(self.selected_users)
pylibwebuicommon.py:33: in click_multi
ele.click()
分析:点击指派会弹出新页面,需要加载时间,所以需要加硬编码来等待,等待页面稳定
# 点击指派
self.click(self.select_btn)
time.sleep(2)
# 清除已选
self.click_multi(self.selected_users)
E selenium.common.exceptions.ElementClickInterceptedException: Message: element click intercepted: Element ... is not clickable at point (139, 156). Other element would receive the click:
同时发现页面元素不可点击,所以需要等待元素可点击再操作
需要改造click方法
等待元素可点击
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
def click(self,locator):
ele=WebDriverWait(self._driver,30).until(
EC.element_to_be_clickable(locator))
ele.click()
def input_text(self,locator,text):
ele=WebDriverWait(self._driver,30).until(
EC.element_to_be_clickable(locator))
ele.send_keys(text)