摘自:https://www.cnblogs.com/ZhuChangwu/p/11793877.html
Elasticsearch 知识点整理 一
极力推荐: 官网地址: https://www.elastic.co/guide/en/elasticsearch/reference/6.0
肺腑之言,学ES先学原生的语法,SpringData封装的是太好用了,但是没玩过原生的语法,可能不知道Spring提供的API在干什么
核心概念:#
Near Realtime (NRT)#
在ES中进行搜索是近实时的,意思是数据从写入ES到可以被searchable仅仅需要1秒钟,因此说基于ES执行的搜索和分析可以达到秒级
Cluster#
集群 , 集群是一个或多个node的集合,他们一起保存你存放进去的数据,用户可以在所有的node之间进行检索,一般的每个集群都会有一个唯一的名称标识,默认的名称标识为 elasticsearch , 这个名字很重要,因为node想加入cluster时,需要这个名称信息
确保别在不同的环境中使用相同的集群名称,进而避免node加错集群的情况,一颗考虑下面的集群命名风格logging-stage和logging-dev和logging-pro
Node#
单台server就是一个node,他和 cluster一样,也存在一个默认的名称,但是它的名称是通过UUID生成的随机串,当然用户也可以定制不同的名称,但是这个名字最好别重复,这个名称对于管理来说很在乎要,因为需要确定,当前网络中的哪台服务器,对应这个集群中的哪个节点
node存在一个默认的设置,默认的,当每一个node在启动时都会自动的去加入一个叫elasticsearch的节点,这就意味着,如果用户在网络中启动了多个node,他们会彼此发现,然后组成集群
在单个的cluster中,你可以拥有任意多的node,假如说你的网络上没有有其他正在运行的节点,然后你启动一个新的节点,这个新的节点自己会组件一个集群
Index#
Index是一类拥有相似属性的document的集合,比如你可以为消费者的数据创建一个index,为产品创建一个index,为订单创建一个index
index名称(必须是小写的字符), 当需要对index中的文档执行索引,搜索,更新,删除,等操作时,都需要用到这个index
一个集群中理论上你可以创建任意数量的index
Type#
Type可以作为index中的逻辑类别,为了更细的划分,比如用户数据type,评论数据type,博客数据type
在设计时,尽最大努力让拥有更多相同field的document会分为同一个type下
Document#
document就是ES中存储的一条数据,就像mysql中的一行记录一样,可以是一条用户的记录,一个商品的记录等等
一个不严谨的小结:#
为什么说这是不严谨的小结呢? 就是说下面三个对应关系只能说的从表面上看起来比较相似,但是ES中的type其实是一个逻辑上的划分,数据在存储是时候依然是混在一起存储的(往下看下文中有写,),然而mysql中的不同表的两个列是绝对没有关系的
| Elasticsearch | 关系型数据库 |
|---|---|
| Document | 行 |
| type | 表 |
| index | 数据库 |
Shards & Replicas#
问题引入:#
如果让一个Index自己存储1TB的数据,响应的速度就会下降为了解决这个问题,ES提供了一种将用户的Index进行subdivide的骚操作,就是将index分片, 每一片都叫一个Shards,实现了将整体庞大的数据分布在不同的服务器上存储
什么是shard?#
shard分成replica shard和primary shard,顾名思义一个是主shard一个是备份shard, 负责容错以及承担部分读请求
shard可以理解成是ES中最小的工作单元,所有shard中的数据之和,才是整个ES中存储的数据, 可以把shard理解成是一个luncene的实现,拥有完成的创建索引,处理请求的能力
下图是两个node,6个shard的组成的集群的划分情况
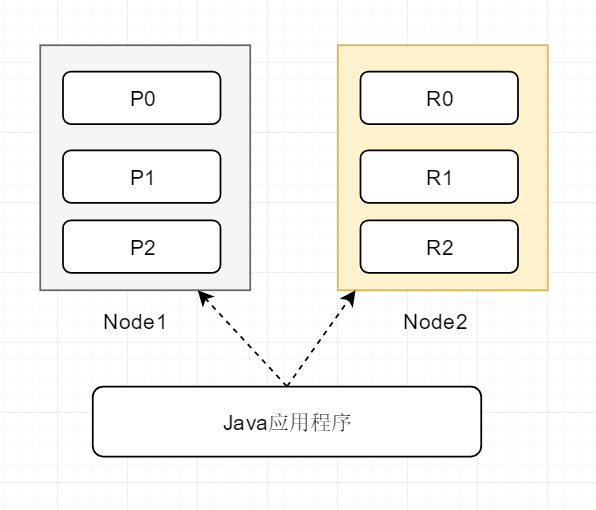
大家可以看到,这时无论java应用程序访问的是node1还是node2,其实都能获取到数据
shard的默认数量#
新创建的节点会存在5个primary shard,后续不然能再改动primary shard的值,如果每一个primary shard都对应一个replica shard,按理说单台es启动就会存在10个分片,但是现实是,同一个节点的replica shard和primary shard不能存在于一个server中,因此单台es默认启动后的分片数量还是5个
如何拓容Cluster#
首先明确一点: 一旦index创建完成了,primary shard的数量就不可能再发生变化
因此横向拓展就得添加replica的数量, 因为replica shard的数量后续是可以改动的, 也就是说,如果后续我们将他的数量改成了2, 就意味着让每个primary shard都拥有了两个replica shard, 计算一下: 5+5*2=15 集群就会拓展成15个节点
如果想让每一个shard都有最多的系统的资源,就增加服务器的数量,让每一个shard独占一个服务器,
举个例子:#
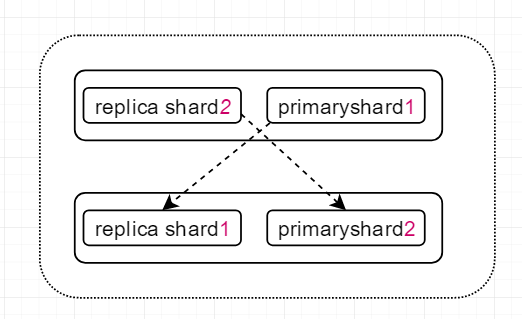
上图中存在上下两个node,每一个node,每个node中都有一个 自己的primary shard和其他节点的replica shard,为什么是强调自己和其他呢? 因为ES中规定,同一个节点的replica shard和primary shard不能存在于一个server中,但是不同节点的primary shard可以存在于同一个server上
当primary shard宕机时,它对应的replicas在其他的server不会受到影响,可以继续响应用户的读请求,通过这种分片的机制,并且分片的地位相当,假设单个shard可以处理2000/s的请求,通过横向拓展可以在此基础上成倍提升系统的吞吐量,天生分布式,高可用
此外:每一个document肯定存在于一个primary shard和这个primary shard 对应的replica shard中, 绝对不会出现同一个document同时存在于多个primary shard中的情况
入门探索:#
集群的健康状况#
GET /_cat/health?v执行结果如下:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1572595632 16:07:12 elasticsearch yellow 1 1 5 5 0 0 5 0 - 50.0%解读上面的信息,默认的集群名是elasticsearch,当前集群的status是yellow,后续列出来的是集群的分片信息,最后一个active_shards_percent表示当前集群中仅有一半shard是可用的
状态#
存在三种状态分别是red green yellow
- green : 表示当前集群所有的节点全部可用
- yellow: 表示所有的数据是可以访问的,但是并不是所有的replica shard都是可以使用的(我现在是默认启动一个node,而ES又不允许同一个node的primary shard和replica shard共存,因此我当前的node中仅仅存在5个primary shard,为status为黄色)
- red: 集群宕机,数据不可访问
集群的索引信息#
GET /_cat/indices?v结果:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open ai_answer_question cl_oJNRPRV-bdBBBLLL05g 5 1 203459 0 172.3mb 172.3mb显示,状态yellow表示存在replica shard不可用, 存在5个primary shard,并且每一个primary shard都有一个replica shard , 一共20多万条文档,未删除过文档,文档占用的空间情况为172.3兆
创建index#
PUT /customer?prettyES 使用的RestfulAPI,新增使用put,这是个很亲民的举动
添加 or 修改#
如果是ES中没有过下面的数据则添加进去,如果存在了id=1的元素就修改(全量替换)
- 格式:
PUT /index/type/id
全量替换时,原来的document是没有被删除的,而是被标记为deleted,被标记成的deleted是不会被检索出来的,当ES中数据越来越多时,才会删除它
PUT /customer/_doc/1?pretty
{
"name": "John Doe"
}响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}强制创建,加添_create或者?op_type=create
PUT /customer/_doc/1?op_type=create
PUT /customer/_doc/1/_create- 局部更新(Partial Update)
不指定id则新增document
POST /customer/_doc?pretty
{
"name": "Jane Doe"
}指定id则进行doc的局部更新操作
POST /customer/_doc/1?pretty
{
"name": "Jane Doe"
}并且POST相对于上面的PUT而言,不论是否存在相同内容的doc,只要不指定id,都会使用一个随机的串当成id,完成doc的插入
Partial Update先获取document,再将传递过来的field更新进document的json中,将老的doc标记为deleted,再将创建document,相对于全量替换中间会省去两次网络请求
检索#
格式: GET /index/type/
GET /customer/_doc/1?pretty响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "John Doe"
}
}删除#
删除一条document
大部分情况下,原来的document不会被立即删除,而是被标记为deleted,被标记成的deleted是不会被检索出来的,当ES中数据越来越多时,才会删除它
DELETE /customer/_doc/1响应:
{
"_index": "customer",
"_type": "_doc",
"_id": "1",
"_version": 2,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}删除index
DELETE /index1
DELETE /index1,index2
DELETE /index*
DELETE /_all
可以在elasticsearch.yml中将下面这个设置置为ture,表示禁止使用 DELETE /_all
action.destructive_required_name:true响应
{
"acknowledged": true
}更新文档#
上面说了POST关键字,可以实现不指定id就完成document的插入, POST + _update关键字可以实现更新的操作
POST /customer/_doc/1/_update?pretty
{
"doc": { "name": "changwu" }
}**POST+_update进行更新的动作依然需要执行id, 但是它相对于PUT来说,当使用POST进行更新时,id不存在的话会报错,而PUT则会认为这是在新增**
此外: 针对这种更新操作,ES会先删除原来的doc,然后插入这个新的doc
#
document api#
multi-index & multi-type#
- 检索所有索引下面的所有数据
/_search- 搜索指定索引下的所有数据
/index/_search- 更多模式
/index1/index2/_search
/*1/*2/_search
/index1/index2/type1/type2/_search
/_all/type1/type2/_search_mget api 批量查询#
- 在docs中指定
_index,_type,_id
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1"
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2"
}
]
}- 在URL中指定index
GET /test/_mget
{
"docs" : [
{
"_type" : "_doc",
"_id" : "1"
},
{
"_type" : "_doc",
"_id" : "2"
}
]
}- 在URL中指定 index和type
GET /test/type/_mget
{
"docs" : [
{
"_id" : "1"
},
{
"_id" : "2"
}- 在URL中指定index和type,并使用ids指定id范围
GET /test/type/_mget
{
"ids" : ["1", "2"]
}- 为不同的doc指定不同的过滤规则
GET /_mget
{
"docs" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_source" : false
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_source" : ["field3", "field4"]
},
{
"_index" : "test",
"_type" : "_doc",
"_id" : "3",
"_source" : {
"include": ["user"],
"exclude": ["user.location"]
}
}
]
}_bulk api 批量增删改#
基本语法#
{"action":{"metadata"}}
{"data"}
存在哪些类型的操作可以执行呢?
-
delete: 删除文档
-
create: _create 强制创建
-
index: 表示普通的put操作,可以是创建文档也可以是全量替换文档
-
update: 局部替换
上面的语法中并不是人们习惯阅读的json格式,但是这种单行形式的json更具备高效的优势
ES如何处理普通的json如下:
- 将json数组转换为JSONArray对象,这就意味着内存中会出现一份一模一样的拷贝,一份是json文本,一份是JSONArray对象
但是如果上面的单行JSON,ES直接进行切割使用,不会在内存中整一个数据拷贝出来
delete#
delete比较好看仅仅需要一行json就ok
{ "delete" : { "_index" : "test", "_type" : "_doc", "_id" : "2" } }
create#
两行json,第一行指明我们要创建的json的index,type以及id
第二行指明我们要创建的doc的数据
{ "create" : { "_index" : "test", "_type" : "_doc", "_id" : "3" } }
{ "field1" : "value3" }
index#
相当于是PUT,可以实现新建或者是全量替换,同样是两行json
第一行表示将要新建或者是全量替换的json的index type 以及 id
第二行是具体的数据
{ "index" : { "_index" : "test", "_type" : "_doc", "_id" : "1" } }
{ "field1" : "value1" }
update#
表示 parcial update,局部替换
他可以指定一个retry_on_conflict的特性,表示可以重试3次
POST _bulk
{ "update" : {"_id" : "1", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"} }
{ "update" : { "_id" : "0", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "script" : { "source": "ctx._source.counter += params.param1", "lang" : "painless", "params" : {"param1" : 1}}, "upsert" : {"counter" : 1}}
{ "update" : {"_id" : "2", "_type" : "_doc", "_index" : "index1", "retry_on_conflict" : 3} }
{ "doc" : {"field" : "value"}, "doc_as_upsert" : true }
{ "update" : {"_id" : "3", "_type" : "_doc", "_index" : "index1", "_source" : true} }
{ "doc" : {"field" : "value"} }
{ "update" : {"_id" : "4", "_type" : "_doc", "_index" : "index1"} }
{ "doc" : {"field" : "value"}, "_source": true}滚动查询技术#
滚动查询技术和分页技术在使用场景方面还是存在出入的,这里的滚动查询技术同样适用于系统在海量数据中进行检索,比如过一次性存在10条数据被命中可以被检索出来,那么性能一定会很差,这时可以选择使用滚动查询技术,一批一批的查询,直到所有的数据被查询完成他可以先搜索一批数据再搜索一批数据
采用基于_doc的排序方式会获得较高的性能
每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索只要在这个时间窗口内完成就ok
示例
GET /index/type/_search?scroll=1m
{
"query":{
"match_all":{}
},
"sort":["_doc"],
"size":3
}响应
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3",
"took": 9,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "2",
"_score": null,
"_source": {
"title": "This is another document",
"body": "This document has a body"
},
"sort": [
0
]
},
{
"_index": "my_index",
"_type": "_doc",
"_id": "1",
"_score": null,
"_source": {
"title": "This is a document"
},
"sort": [
0
]
}
]
}
}再次滚动查询
GET /_search/scroll
{
"scroll":"1m",
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAACNFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAkRZSZlh2S05BYVNKZW85R19NS1Nlc1F3AAAAAAAAAI8WUmZYdktOQWFTSmVvOUdfTUtTZXNRdwAAAAAAAACQFlJmWHZLTkFhU0plbzlHX01LU2VzUXcAAAAAAAAAjhZSZlh2S05BYVNKZW85R19NS1Nlc1F3"
}_search api 搜索api#
query string search#
_searchAPI + 将请求写在URI中
GET /bank/_search?q=*&sort=account_number:asc&pretty同样使用的是RestfulAPI, q=* ,表示匹配index=bank的下的所有doc,sort=account_number:asc表示告诉ES,结果按照account_number字段升序排序,pretty是告诉ES,返回一个漂亮的json格式的数据
上面的q还可以写成下面这样
GET /bank/_search?q=自定义field:期望的值
GET /bank/_search?q=+自定义field:期望的值
GET /bank/_search?q=-自定义field:期望的值响应:
{
"took" : 63, // 耗费的时间
"timed_out" : false, // 是否超时了
"_shards" : { // 分片信息
"total" : 5, // 总共5个分片,它的搜索请求会被打到5个分片上去,并且都成功了
"successful" : 5, //
"skipped" : 0, // 跳过了0个
"failed" : 0 // 失败了0个
},
"hits" : { //命中的情况
"total" : 1000, // 命中率 1000个
"max_score" : null, // 相关性得分,越相关就越匹配
"hits" : [ {
"_index" : "bank", // 索引
"_type" : "_doc", // type
"_id" : "0", // id
"sort": [0],
"_score" : null, // 相关性得分
// _source里面存放的是数据
"_source" : {"account_number":0,"balance":16623,"firstname":"Bradshaw","lastname":"Mckenzie","age":29,"gender":"F","address":"244 Columbus Place","employer":"Euron","email":"bradshawmckenzie@euron.com","city":"Hobucken","state":"CO"}
}, {
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"sort": [1],
"_score" : null,
"_source" : {"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
}, ...
]
}
}指定超时时间: GET /_search?timeout=10ms 在进行优化时,可以考虑使用timeout, 比如: 正常来说我们可以在10s内获取2000条数据,但是指定了timeout,发生超时后我们可以获取10ms中获取到的 100条数据
query dsl (domain specified language)#
下面我仅仅列出来了一点点, 更多的示例,参见官网 点击进入官网
_searchAPI +将请求写在请求体中
GET /bank/_search
{
"query": { "match_all": {} }, # 查询全部
"query": { "match": {"name":"changwu zhu"} }, # 全文检索,户将输入的字符串拆解开,去倒排索引中一一匹配, 哪怕匹配上了一个也会将结果返回
# 实际上,上面的操作会被ES转换成下面的格式
#
# {
# "bool":{
# "should":[
# {"term":{"title":"changwu"}},
# {"term":{"title":"zhu"}}
# ]
# }
# }
#
"query": {
"match": { # 手动控制全文检索的精度,
"name":{
"query":"changwu zhu",
"operator":"and", # and表示,只有同时出现changwu zhu 两个词的doc才会被命中
"minimum_should_match":"75%" # 去长尾,控制至少命中3/4才算是真正命中
}
}
}, # 全文检索,operator 表示
# 添加上operator 操作会被ES转换成下面的格式,将上面的should转换成must
#
# {
# "bool":{
# "must":[
# {"term":{"title":"changwu"}},
# {"term":{"title":"zhu"}}
# ]
# }
# }
#
# 添加上 minimum_should_match 操作会被ES转换成下面的格式
#
# {
# "bool":{
# "should":[
# {"term":{"title":"changwu"}},
# {"term":{"title":"zhu"}}
# ],
# "minimum_should_match":3
# }
# }
#
"query": {
"match": { #控制权重,
"name":{
"query":"changwu zhu",
"boost":3 # 将name字段的权重提升成3,默认情况下,所有字段的权重都是样的,都是1
}
}
},
"query": {
# 这种用法不容忽略
"dis_max": { # 直接取下面多个query中得分最高的query当成最终得分
"queries":[
{"match":{"name":"changwu zhu"}},
{"match":{"content":"changwu"}}
]
}
},
# best field策略
"query": { # 基于 tie_breaker 优化dis_max
# tie_breaker可以使dis_max考虑其他field的得分影响
"multi_match":{
"query":"用于去匹配的字段",
"type":"most_fields",# 指定检索的策略most_fields
"fields":["field1","field2","field3"]
}
},
# most field 策略, 优先返回命中更多关键词的doc, (忽略从哪个,从多少个field中命中的,只要命中就行)
"query": { # 基于 tie_breaker 优化dis_max
# tie_breaker可以使dis_max考虑其他field的得分影响
"dis_max": { # 直接取下面多个query中得分最高的query当成最终得分, 这也是best field策略
"queries":[
{"match":{"name":"changwu zhu"}},
{"match":{"content":"changwu"}}
],
"tie_breaker":0.4
}
},
"query": { "match_none": {} }
"query": { "term": {"test_field":"指定值"} } # 精确匹配
"query": { "exits": {"field":"title"} } # title不为空(但是这时ES2.0中的用法,现在不再提供了)
"query": { # 短语检索
# 顺序的保证是通过 term position来保证的
# 精准度很高,但是召回率低
"match_phrase": { # 只有address字段中包含了完整的 mill lane (相连,顺序也不能变) 时,这个doc才算命中
"address": "mill lane"
}
},
"query": { # 短语检索
"match_phrase": {
"address": "mill lane",
# 指定了slop就不再要求搜索term之间必须相邻,而是可以最多间隔slop距离
# 在指定了slop参数的情况下,离关键词越近,移动的次数越少, relevance score 越高
# match_phrase + slop 和 proximity match 近似匹配作用类似
# 平衡精准度和召回率
"slop":1 # 指定搜索文本中的几个term经过几次移动后可以匹配到一个doc
}
},
# 混合使用match和match_phrase 平衡精准度和召回率
"query": {
"bool": {
"must": {
# 全文检索虽然可以匹配到大量的文档,但是它不能控制词条之间的距离
# 可能java elasticsearch在Adoc中距离很近,但是它却被ES排在结果集的后面
# 它的性能比match_phrase高10倍,比proximity高20倍
"match": {
"address": "java elasticsearch"
}
},
"should": {
# 借助match_phrase+slop可以感知term position的功能,为距离相近的doc贡献分数,让它们靠前排列
"match_phrase":{
"title":{
"query":"java elasticsearch",
"slop":50
}
}
}
},
# 重打分机制
"query": {
"match":{
"title":{
"query":"java elasticsearch",
"minimum_should_match":"50%"
}
},
"rescore":{ # 对全文检索的结果进行重新打分
"window_size":50, # 对全文检索的前50条进行重新打分
"query": {
"rescore_query":{ # 关键字
"match_phrase":{ # match_phrase + slop 感知 term persition,贡献分数
"title":{
"query":"java elasticsearch",
"slop":50
}
}
}
}
}
# 前缀匹配, 相对于全文检索,前缀匹配是不会进行分词的,而且每次匹配都会扫描整个倒排索引,直到扫描完一遍才会停下来
# 不会计算相关性得分,前缀越短拼配到的越多,性能越不好
"query": { # 查询多个, 在下面指定的两个字段中检索含有 `this is a test`的doc
"multi_match" : {
"query": "this is a test",
"fields": [ "subject", "message" ]
}
},
"query": { # 前缀搜索,搜索 user字段以ki开头的 doc
"prefix" : { "user" : "ki" }
},
"query": { # 前缀搜索 + 添加权重
"prefix" : { "user" : { "value" : "ki", "boost" : 2.0 } }
},
# 通配符搜索
"query": {
"wildcard" : { "user" : "ki*y" }
},
"query": {
"wildcard" : { "user" : { "value" : "ki*y", "boost" : 2.0 } }
}
# 正则搜索
"query": {
"regexp":{
"name.first": "s.*y"
}
},
"query": {