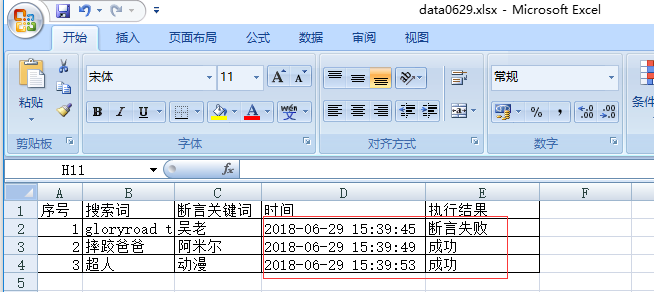
data.xlsx:

脚本:
#encoding=utf-8
from selenium import webdriver
import time
import datetime
from openpyxl import *
wb=load_workbook(r'd:\test\data.xlsx')
ws=wb.active#获取第一个sheet
print u"最大行号:",ws.max_row
#excel行是从1开始的,所以我们从2开始迭代遍历
#且使用切片,必须有结束行的索引号,不能写[1:],这样不行
#列号是从0开始的,列取出来是个元祖
driver=webdriver.Firefox(executable_path='c:\geckodriver')
test_result=[]
#print 'ws:', ws[2:ws.max_row]
#for row in ws[2:ws.max_row]:
# print row
for row in ws[2:ws.max_row]:
print row[1],row[2]
try:
driver.get('http://www.baidu.com')
driver.find_element_by_id('kw').send_keys(row[1].value)
driver.find_element_by_id('su').click()
time.sleep(3)
assert row[2].value in driver.page_source
row[3].value=time.strftime('%Y-%m-%d %H:%M:%S')
row[4].value=u'成功'
except AssertionError,e:
row[3].value=time.strftime('%Y-%m-%d %H:%M:%S')
row[4].value=u"断言失败"
except Exception,e:
row[3].value=time.strftime('%Y-%m-%d %H:M:%S')
row[4].value=u"出现异常失败"
driver.quit()
wb.save(u"d:\test\0627\data0629.xlsx")#注意:将直接覆盖,不是更新。
结果:
d: est�627>python test.py
最大行号: 4
<Cell u'Sheet1'.B2> <Cell u'Sheet1'.C2>
<Cell u'Sheet1'.B3> <Cell u'Sheet1'.C3>
<Cell u'Sheet1'.B4> <Cell u'Sheet1'.C4>
Data0629.xlsx: