进程:
进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。。
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
进程是一个内核级的实体,进程结构的所有成分都在内核空间中,一个用户程序不能直接访问这些数据。
进程状态:
创建、就绪、运行、阻塞、结束
进程的概念主要有两点:
第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本区域(text region)、数据区域(data region)和堆栈(stack region)。文本区域存储处理器执行的代码;数据区域存储变量和进程执行期间使用的动态分配的内存;堆栈区域存储着活动过程调用的指令和本地变量。
第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时,它才能成为一个活动的实体,我们称其为进程。
进程是操作系统中最基本、重要的概念。是多任务系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各程序的活动规律引进的一个概念,所有多任务设计操作系统都建立在进程的基础上。
进程是操作系统中分配资源的最小单位
线程是操作系统调度的最小单位
线程属于进程,一般一个进程会 有一个主线程
程序+数据+运行是进程
简单理解就是一个程序
Ps –ef
进程的特征
Ø动态性:进程的实质是程序在多任务系统中的一次执行过程,进程是动态产生,动态消亡的。
Ø并发性:任何进程都可以同其他进程一起并发执行
Ø独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;
Ø异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度执行
Ø结构特征:进程由程序、数据和进程控制块三部分组成。
Ø多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
进程的状态
创建
就绪:可被执行的状态,需要等CPU执行
运行:
组赛:等待数据或资源时,I/O,
结束:
CPU:寄存器(存储),控制器(控制),
Cpu缓存
https://baike.baidu.com/item/CPU缓存/3728308?fr=aladdin
程序本身,数据,堆栈
单核CPU,运行时用时间片轮寻
单cpu时用多线程好还是单线程好?
如果是纯计算密集型的,开一个线程要快,因为CPU在同一时刻只能运行一个线程,如果程序没有I/O操作,那一个线程块,保证CPU告诉的执行这个线程,此时开多个线程,cpu要做切换,切换本身产生延迟
如果是大量i/o时,需要等待时,cpu不会等,如果只跑一个线程,cpu会等,如果多线程,一个需要等时,cpu会执行其他的线程,这样cpu利用率要高,
如果有大量I/O,多线程好,会提高cpu利用率
进程特点
动态性
并发性
独立性:QQ和word进程是独立的,没有关系
异步性:各自在执行当中,相互并行执行
同步(顺序运行)和异步(并行执行)
同步时:业务有1,2,3,4严格的顺序,一步一步的执行,就是同步
异步:业务没有严格的执行的顺序,注册搜狐邮箱后,系统会把账号同步给其他模块账户的过程就是异步
一般互联网中业务都是异步的
同步需要耗时
结构:程序、数据、进程控制块PCB(存进程相关的信息,id,副id,状态等等)
不同的进程可以执行相同的程序,不同账号登陆
CPU组成:运算器、控制器、寄存器
主频3.5G,发展较慢
摩尔定律:没18个月cpu速度翻一倍,现在失效了
智能时代:吴军
刻意练习:
进程切换:
CPU时间片轮寻,进
上下文:一个程序运行时的中间状态和数据
比如跑到第5行,下次跑的时候,还是从第5行跑,这个状态和数据就是上下文
进程运行状态:
就绪状态,运行状态,阻塞状态
阻塞:I/O或进程同步,或网络服务器发请求等待数据等,被阻塞
原语(原子操作):一段程序不能分割,操作系统的最小的一个指令集
loadnunner的事物是用来算时间差的,用来计时的,统计耗时
数据库的事务要么都失败,要么都成功
ram:random
room,read only
内存:随机访问存储器RAM
内存更快,不能永久保存,磁盘慢,永久 保存数据
互联网口诀:分库、分表、分布式计算、分布式缓存、异步技术
互联网系统架构:
服务器端和客户端
数据库有没有集群,怎么搭的?
写的多还是读的多,主是写,从是读,主的少,从的多
mysql:主从结构,主的是写,从的是读
挂起(等待、组赛):等待I/O、其他进程的结果(进程间同步)
同步、异步、阻塞、非阻塞
同步:死等
异步:不等
阻塞:等待一个条件的发生
非阻塞:不需要等待条件
进程的五态模型:
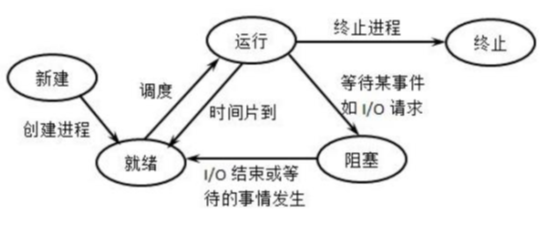
进程状态转换
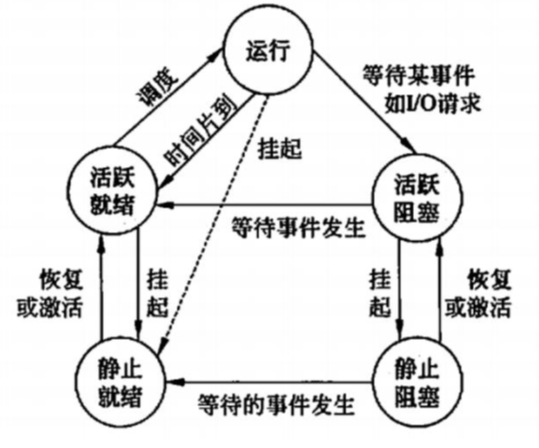
活跃就绪:是指进程在主存并且可被调度的状态。
静止就绪(挂起就绪):是指进程被对换到辅存时的就绪状态,是不能被直接调度的状态,只有当主存中没有活跃就绪态进程,或者是挂起就绪态进程具有更高的优先级,系统将把挂起就绪态进程调回主存并转换为活跃就绪。
活跃阻塞:是指进程已在主存,一旦等待的事件产生便进入活跃就绪状态。
静止阻塞:是指进程对换到辅存时的阻塞状态,一旦等待的事件产生便进入静止就绪状态。
linux:swap,内存不够用时写入swap(硬盘)
pcb存贮进程的信息
程序计数器,program counter,记录运行到哪一行
进程的创建过程:
一旦操作系统发现了要求创建新进程的事件后,便调用进程创建原语Creat()按下述步骤创建一个新进程。
1)申请空白PCB(进程控制块)。为新进程申请获得唯一的数字标识符,并从PCB集合中索取一个空白PCB。
2)为新进程分配资源。为新进程的程序和数据以及用户栈分配必要的内存空间。显然,此时操作系统必须知道新进程所需要的内存大小。
3)初始化进程控制块。PCB的初始化包括:
①初始化标识信息,将系统分配的标识符和父进程标识符,填入新的PCB中。
②初始化处理机状态信息,使程序计数器指向程序的入口地址,使栈指针指向栈顶。
③初始化处理机控制信息,将进程的状态设置为就绪状态或静止就绪状态,对于优先级,通常是将它设置为最低优先级,除非用户以显式的方式提出高优先级要求。
4)将新进程插入就绪队列,如果进程就绪队列能够接纳新进程,便将新进程插入到就绪队列中
进程终止:
引起进程终止的事件
1)正常结束
在任何计算机系统中,都应该有一个表示进程已经运行完成的指示。例如,在批处理系统中,通常在程序的最后安排一条Hold指令或终止的系统调用。当程序运行到Hold指令时,将产生一个中断,去通知OS本进程已经完成。
2)异常结束
在进程运行期间,由于出现某些错误和故障而迫使进程终止。这类异常事件很多,常见的有:越界错误,保护错,非法指令,特权指令错,运行超时,等待超时,算术运算错,I/O故障。
3)外界干预
外界干预并非指在本进程运行中出现了异常事件,而是指进程应外界的请求而终止运行。这些干预有:操作员或操作系统干预,父进程请求,父进程终止。
如果系统发生了上述要求终止进程的某事件后,OS便调用进程终止原语,按下述过程去终止指定的进程。
1)根据被终止进程的标识符,从PCB集合中检索出该进程的PCB,从中读出该进程状态。
2)若被终止进程正处于执行状态,应立即终止该进程的执行,并置调度标志为真。用于指示该进程被终止后应重新进行调度。
3)若该进程还有子孙进程,还应将其所有子孙进程予以终止,以防他们成为不可控的进程。
4)将被终止的进程所拥有的全部资源,或者归还给其父进程,或者归还给系统。
5)将被终止进程(它的PCB)从所在队列(或链表)中移出,等待其它程序来搜集
阻塞
1、请求系统服务
2、启动某种操作
3、新数据尚未到达
4、没事儿干
唤醒:
各种事儿已经准备完成
调度算法:
先到显出
时间片轮转
优先级
Python 进程
multiprocessing较多
进程间通信
ü 文件
ü 管道( Pipes Pipes )
ü Socket
ü 信号
ü 信号量
ü 共享内存
#!/user/bin/python
#encoding=utf-8
import os
print os.getpid()
pid = os.fork() # 创建一个子进程
print "******",pid #子进程id和0
if pid == 0:
print 'I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid())
else:
print 'I (%s) just created a child process (%s).' % (os.getpid(), pid)
[gstudent@iZ2zejbxp2btn9jh8knipuZ xxx]$ python test.py
610
****** 611
I (610) just created a child process (611).
****** 0
I am child process (611) and my parent is 610.
在linux中,执行fork函数之后
父进程拿到的返回的fork函数返回值是子进程的pid
子进程拿到的返回的fork函数返回值是0
父进程和子进程会分别执行后续未执行的代码
,子进程执行的时if,父进程执行的是else
fork() fork() 函数,它也属于一个内建并 且只在 Linux 系统下存在。 它非常特殊普通的函数调用,一次返回但是 fork() fork() 调用一次,返回两因为操 作系统自动把当前进程(称为父)复制了一份(称为子进程),然后分别在父进程和子内返回。
子进程永远返回 0,而父进程 返回子的PID 。这样做的理由是,一个父进程可 以fork() fork() 出很多子进程,所以父要 记下每个子进程的 ID ,而子进程只需要调 用getppid () 就可以拿到父进程的 ID ,子 进程只需要调用 os.getpid os.getpid () 函数可以获取 自
创建进程
Multiprocessing
Multiprocessing模块创建进程使用的是Process类。
Process类的构造方法:
help(multiprocessing.Process)
__init__(self, group=None, target=None, name=None, args=(), kwargs={})
参数说明:
group:进程所属组,基本不用。
target:表示调用对象,一般为函数。
args:表示调用对象的位置参数元组。
name:进程别名。
kwargs:表示调用对象的字典。
创建子进程时,只需要传入一个执行函数和函数的参数,创建一个Process实例,并用其start()方法启动,这样创建进程比fork()还要简单。
join()方法表示等待子进程结束以后再继续往下运行,通常用于进程间的同步。
注意:
在Windows上要想使用进程模块,就必须把有关进程的代码写在当前.py文件的if __name__ == ‘__main__’ :语句的下面,才能正常使用Windows下的进程模块 。Unix/Linux下则不需要。
创建5个进程例子
#coding=utf-8
import multiprocessing
def do(n) :
#获取当前线程的名字
name = multiprocessing.current_process().name
print name,'starting'
print "worker ", n
return
if __name__ == '__main__' :
numList = []
for i in xrange(5) :
p = multiprocessing.Process(target=do, args=(i,))
numList.append(p)
p.start()
p.join()#进程执行完毕后才继续执行
print "Process end."
print numList
c:Python27Scripts>python task_test.py
Process-1 starting
worker 0
Process end.
Process-2 starting
worker 1
Process end.
Process-3 starting
worker 2
Process end.
Process-4 starting
worker 3
Process end.
Process-5 starting
worker 4
Process end.
[<Process(Process-1, stopped)>, <Process(Process-2, stopped)>, <Process(Process-3, stopped)>, <Process(Process-4, stopped)>, <Process(Process-5, stopped)>]
把p.join()注释掉
p.start()
#p.join()
print "Process end."
print numList
c:Python27Scripts>python task_test.py
Process end.
Process end.
Process end.
Process end.
Process end.
[<Process(Process-1, started)>PP, rocess-1rocess-3< Process(Process-2, started)>s , tartings<
tartingProcess(Process-3, started)>P
wProcess-4 sworker rocess-2tarting
worker , orker 3
< 0sProcess(Process-4, started)>2
tarting,
<wProcess(Process-5, started)>orker ]
1
Process-5 starting
worker 4
练习:三个进程,每个进程写一个文件,每个文件中有进程的名称和日期
#coding=utf-8
import multiprocessing
import time
def do(n) :
fp=open(r"d:\%s.txt"%n,'w')
name=multiprocessing.current_process().name
fp.write("%s %s"%(name,time.strftime("%Y-%m-%d %H:%M:%S")))
fp.close()
return
if __name__ == '__main__' :
numList = []
for i in xrange(3) :
p = multiprocessing.Process(target=do, args=(i,))
numList.append(p)
p.start()
p.join()
print "Process end."
print numList
Process-2 2018-03-31 14:55:34
Os.fork()和multiprocessing结合使用
#!/usr/bin/python
# -*- coding: utf-8 -*-
from multiprocessing import Process
import os
import time
def sleeper(name, seconds):
print "Process ID# %s" % (os.getpid())
print "Parent Process ID# %s" %
(os.getppid())
#仅支持在linux上,一个进程会有父进程和自己的ID,windows上就没有父进程id
print
"%s will sleep for %s seconds" % (name, seconds)
time.sleep(seconds)
# if __name__ == "__main__":
child_proc = Process(target = sleeper, args = ('bob', 5))
child_proc.start()
print "in parent process after child process start"
print "parent process about to join child process"
child_proc.join()
print "in parent process after child process join"
print "the parent's parent process: %s" % (os.getppid())
没运行成功
多进程模板程序
#coding=utf-8
import multiprocessing
import urllib2
import time
def func1(url) :
response = urllib2.urlopen(url)
html = response.read()
print html[0:20]
time.sleep(20)
def func2(url) :
response = urllib2.urlopen(url)
html = response.read()
print html[0:20]
time.sleep(20)
if __name__ == '__main__' :
p1 =
multiprocessing.Process(target=func1,args=("http://www.sogou.com",),name="gloryroad1")
p2 =
multiprocessing.Process(target=func2,args=("http://www.baidu.com",),name="gloryroad2")
p1.start()
p2.start()
p1.join()
p2.join()
time.sleep(10)
print "done!"
c:Python27Scripts>python task_test.py
<!DOCTYPE html>
<!--
<!DOCTYPE html>
<ht
done!
测试单进程和多进程程序执行的效率
#coding: utf-8
import multiprocessing
import time
def m1(x):
time.sleep(0.01)
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool(multiprocessing.cpu_count())
i_list = range(1000)
time1=time.time()
pool.map(m1, i_list)
time2=time.time()
print 'time elapse:',time2-time1
time1=time.time()
map(m1, i_list)
time2=time.time()
print 'time elapse:',time2-time1
c:Python27Scripts>python task_test.py
time elapse: 2.62400007248
time elapse: 10.2070000172
多线程只能用单核CPU
多进程好于多线程,因为多线程有同步锁
进程池
在使用Python进行系统管理时,特别是同时操作多个文件目录或者远程控制多台主机,并行操作可以节约大量的时间。如果操作的对象数目不大时,还可以直接使用Process类动态的生成多个进程,十几个还好,但是如果上百个甚至更多,那手动去限制进程数量就显得特别的繁琐,此时进程池就派上用场了。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
pool类中方法
apply():
函数原型:apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不再使用)。
map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到返回结果。
注意,虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
close()
关闭进程池(Pool),使其不再接受新的任务。
Close()要在join()之后使用
pool.close()#关闭进程池,不再接受新的任务
pool.join()#主进程阻塞等待子进程的退出
terminate()
立刻结束工作进程,不再处理未处理的任务。
join(),map(),close(),terminate(),apply()
join()
使主进程阻塞等待子进程的退出,join方法必须在close或terminate之后使用。
获取CPU的核数
multiprocessing.cpu_count() #获取cpu
创建进程池
#coding: utf-8
import multiprocessing
import os
import time
import random
def m1(x):
time.sleep(random.random()*4)
print "pid:",os.getpid(),x*x
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool(multiprocessing.cpu_count())
i_list = range(8)
print pool.map(m1, i_list)
c:Python27Scripts>python task_test.py
pid: 5584 0
pid: 8764 4
pid: 11708 9
pid: 6380 1
pid: 6380 49
pid: 5584 16
pid: 8764 25
pid: 11708 36
[0, 1, 4, 9, 16, 25, 36, 49]
pool.apply_async(f, [10]), result.get(timeout = 1)
async只创建一个进程,每次只能传入一个参数,传一个列表,会返回列表第一个元素返回得结果
创建简单的进程池
#encoding=utf-8
from multiprocessing import Pool
def f(x):
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
#下边这行是异步,不等待,一执行就一直往下走
result = pool.apply_async(f, [10]) # evaluate "f(10)" asynchronously
print result.get(timeout = 1)
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
100
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
#encoding=utf-8
from multiprocessing import Pool
import time
def f(x):
time.sleep(2)
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result = pool.apply_async(f, [10]) # evaluate "f(10)" asynchronously
print result.get(timeout = 1)
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
Traceback (most recent call last):
File "task_test.py", line 12, in< module>
print result.get(timeout = 1)
File "C:Python27libmultiprocessingpool.py", line 568, in get
raise TimeoutError
multiprocessing.TimeoutError
help(pool.apply_async)
>>> help(pool.apply_async)
Help on method apply_async in module multiprocessing.pool:
apply_async(self, func, args=(), kwds={}, callback=None) method of multiprocessing.pool.Pool instance
Asynchronous equivalent of `apply()` builtin
#encoding=utf-8
from multiprocessing import Pool
import time
def f(x):
time.sleep(2)
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result = pool.apply_async(f, [10]) # evaluate "f(10)" asynchronously
print result.get()#这里没有设置时间,那进程就会死等
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
也可以创建多个很多进程
if __name__ == '__main__':
pool = Pool(processes = 40) # start 4 worker processes
进程切换快,还是线程切换快,
切换线程时,是不需要切换上下文的,进程的上下文不需要动
from multiprocessing import Pool
def f(*x):
for i in x:
return i * i
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result = pool.apply_async(f,tuple(range(10))) # evaluate "f(10)" asynchronously
print result.get(timeout = 1)
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
0
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
多进程
#encoding=utf-8
from multiprocessing import Pool
def f(x):
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result1 = pool.apply_async(f, [10])
result2 = pool.apply_async(f, [100])
result3 = pool.apply_async(f, [1000]) # evaluate "f(10)" asynchronously
print result1.get(timeout = 1)
print result2.get(timeout = 1)
print result3.get(timeout = 1)
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
100
10000
1000000
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
修改:
#encoding=utf-8
from multiprocessing import Pool
import time
def f(x):
print "hello"
time.sleep(2)
print "over"
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result1 = pool.apply_async(f, [10])
result2 = pool.apply_async(f, [100])
result3 = pool.apply_async(f, [1000]) # evaluate "f(10)" asynchronously
print result1.get(timeout = 3)
print result2.get(timeout = 3)
print result3.get(timeout = 3)
print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
helloh
ello
hello
over
over
over
100
10000
1000000
hhhhelloelloelloello
ooverver
hhooelloelloverver
hhelloello
over
hoellover
oohververello
over
over
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
注掉最后一行:
#encoding=utf-8
from multiprocessing import Pool
import time
def f(x):
print "hello"
time.sleep(2)
print "over"
return x * x
if __name__ == '__main__':
pool = Pool(processes = 4) # start 4 worker processes
result1 = pool.apply_async(f, [10])
result2 = pool.apply_async(f, [100])
result3 = pool.apply_async(f, [1000]) # evaluate "f(10)" asynchronously
print result1.get(timeout = 3)
print result2.get(timeout = 3)
print result3.get(timeout = 3)
#print pool.map(f, range(10)) # prints "[0, 1, 4,..., 81]"
c:Python27Scripts>python task_test.py
hello
hello
hello
over
over
over
100
10000
1000000
修改为同步:
#encoding=utf-8
from multiprocessing import Pool
import time
def f(x):
print "hello"
time.sleep(2)
print "over"
return x * x
if __name__ == '__main__':
f(10)
f(109)
f(1000)
c:Python27Scripts>python task_test.py
hello
over
hello
over
hello
over
单进程和多进程时间比较
#encoding=utf-8
import time
from multiprocessing import Pool
def run(fn):
#fn: 函数参数是数据列表的一个元素
time.sleep(1)
return fn * fn
if __name__ == "__main__":
testFL = [1,2,3,4,5,6]
print 'Single process execution sequence:' #顺序执行(也就是串行执行,单进程)
s = time.time()
for fn in testFL:
run(fn)
e1 = time.time()
print u"顺序执行时间:", int(e1 - s)
print 'concurrent:' #创建多个进程,并行执行
pool = Pool(5) #创建拥有5个进程数量的进程池
#testFL:要处理的数据列表,run:处理testFL列表中数据的函数
rl =pool.map(run, testFL)
pool.close()#关闭进程池,不再接受新的任务
pool.join()#主进程阻塞等待子进程的退出
e2 = time.time()
print u"并行执行时间:", int(e2 - e1)
print rl
c:Python27Scripts>python task_test.py
Single process execution sequence:
顺序执行时间: 6
concurrent:
并行执行时间: 2
[1, 4, 9, 16, 25, 36]
上例是一个创建多个进程并发处理与顺序执行处理同一数据,所用时间的差别。从结果可以看出,并发执行的时间明显比顺序执行要快很多,但是进程是要耗资源的,所以进程数也不能开太大。
程序中的r1表示全部进程执行结束后全局的返回结果集,run函数有返回值,所以一个进程对应一个返回结果,这个结果存在一个列表中,也就是一个结果堆中,实际上是用了队列的原理,等待所有进程都执行完毕,就返回这个列表(列表的顺序不定)。
对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),让其不再接受新的Process。
同步进程(消息队列Queue&JoinableQueue)
队列,先进先出
multiprocessing.Queue类似于queue.Queue,一般用来多个进程间交互信息。Queue是进程和线程安全的。它实现了queue.Queue的大部分方法,但task_done()和join()没有实现。
multiprocessing.JoinableQueue是multiprocessing.Queue的子类,增加了task_done()方法和join()方法。
task_done():用来告诉queue一个task完成。一般在调用get()时获得一个task,在task结束后调用task_done()来通知Queue当前task完成。
join():阻塞直到queue中的所有的task都被处理(即task_done方法被调用)。
Join()是主程序等我这个进程执行完毕了,程序才往下走
#encoding=utf-8
from multiprocessing import Process, Queue
def offer(queue):
# 入队列
queue.put("Hello World")
if __name__ == '__main__':
# 创建一个队列实例
q = Queue()
p = Process(target = offer, args = (q,))
p.start()
print q.get() # 出队列
p.join()
c:Python27Scripts>python task_test.py
Hello World
不同的进程之间不能修改对方的变量
但进程里的线程可以,因为线程在同一个进程里,变量共享
>>> import Queue
>>> myqueue = Queue.Queue(maxsize = 10)
>>> myqueue.put(1)
>>> myqueue.put(2)
>>> myqueue.put(3)
>>> myqueue.get()
1
>>> myqueue.get()
2
>>> myqueue.get()
3
>>>import Queue
>>>q=Queue.Queue(5)
>>>q
<Queue.Queue instance at 0x04EA1968>
>>>q.put(1)
>>>q.put(2)
>>>q.put(3)
>>>q.put(4)
>>>q.put(5)
>>>q.full()
True
>>>q.qsize()
5
>>>q.empty()
False
>>>q.get(2)
1
>>>
>>>q.empty()
True
q.get(False,2),q.get(True,2)
True表示等2秒,如果队列空就报错
False表示不等,如果队列空立即报错
>>>q.get(False,2)
Traceback (most recent call last):
File "<stdin>", line 1, in< module>
File "C:Python27libQueue.py", line 165, in get
raise Empty
Queue.Empty
>>>q.get(True,2)
Traceback (most recent call last):
File "<stdin>", line 1, in< module>
File "C:Python27libQueue.py", line 176, in get
raise Empty
Queue.Empty
get(self, block=True, timeout=None)
| Remove and return an item from the queue.
|
| If optional args 'block' is true and 'timeout' is None (the default),
| block if necessary until an item is available. If 'timeout' is
| a non-negative number, it blocks at most 'timeout' seconds and raises
| the Empty exception if no item was available within that time.
| Otherwise ('block' is false), return an item if one is immediately
| available, else raise the Empty exception ('timeout' is ignored
| in that case).
>>>try:
... q.get(False)
... except Queue.Empty:
... print "empty!"
...
empty!
>>>
练习:两个进程,一个往队列里写10个数,一个进程读取队列的10个数
#encoding=utf-8
from multiprocessing import Process, Queue
def offer(queue):
# 入队列
for i in range(10):
queue.put("%s"%i)
def getter(queue):
for i in range(10):
print queue.get(False,1)
if __name__ == '__main__':
# 创建一个队列实例
q = Queue()
p = Process(target = offer, args = (q,))
p2= Process(target = getter, args = (q,))
p.start()
p2.start()
p.join()
p2.join()
c:Python27Scripts>python task_test.py
0
1
2
3
4
5
6
7
8
9
#encoding=utf-8
import time
from multiprocessing import Process, Queue
def set_data(queue):
# 入队列
for i in range(10):
time.sleep(2)
queue.put("Hello World"+str(i))
def get_data(queue):
for i in range(10):
# 入队列
time.sleep(1)
print queue.get("Hello World")
if __name__ == '__main__':
# 创建一个队列实例
q = Queue()
p1 = Process(target = set_data, args = (q,))
p2 = Process(target = get_data, args = (q,))
p1.start()
p2.start()
p1.join()
p2.join()
print u"队列是否为空?",q.empty()
c:Python27Scripts>python task_test.py
Hello World0
Hello World1
Hello World2
Hello World3
Hello World4
Hello World5
Hello World6
Hello World7
Hello World8
Hello World9
队列是否为空? True
这就是两个进程通过队列进行信息同步
下面的程序需要看下结果
#encoding=utf-8
from multiprocessing import Process, Queue
import time
def offer(queue):
# 入队列
for i in range(10):
time.sleep(2)
queue.put("%s"%i)
def getter(queue):
for i in range(10):
time.sleep(1)
print queue.get(False,1)
print "queue.qsize():",queue.qsize()
if __name__ == '__main__':
# 创建一个队列实例
q = Queue()
p = Process(target = offer, args = (q,))
p2= Process(target = getter, args = (q,))
p.start()
p2.start()
p.join()
p2.join()
会报错,因为2秒写一次,1就读,会读空,所以报错
c:Python27Scripts>python task_test.py
Process Process-2:
Traceback (most recent call last):
File "C:Python27libmultiprocessingprocess.py", line 267, in _bootstrap
self.run()
File "C:Python27libmultiprocessingprocess.py", line 114, in run
self._target(*self._args, **self._kwargs)
File "c:Python27Scripts ask_test.py", line 12, in getter
print queue.get(False,timeout=1)
File "C:Python27libmultiprocessingqueues.py", line 134, in get
raise Empty
Empty
进程同步(使用queue)
#encoding=utf-8
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
for value in ['A', 'B', 'C']:
print 'Put %s to queue...' % value
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码
def read(q):
time.sleep(1)
while not q.empty():
# if not q.empty():
print 'Get %s from queue.' % q.get(True)
time.sleep(1) # 目的是等待写队列完成
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程
q = Queue()
pw = Process(target = write, args = (q,))
pr = Process(target = read, args = (q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
pr.join()
print "Done!"
c:Python27Scripts>python task_test.py
Put A to queue...
Put B to queue...
Get A from queue.
Put C to queue...
Get B from queue.
Get C from queue.
Done!
由于操作系统对进程的调度时间不一样,所以该程序每次执行的结果均不一样。
程序读队列函数中为什么要加一句time.sleep(1),目的是等待些进程将数据写到队列中,防止有时写进程还没将数据写进队列,读进程就开始读了,导致读不到数据。但是这种并不能有效的预防此种情况的出现。
下面是一片关于多进程的帖子,可以帮助理解一下