1.开启慢查询
查看开启状态:show variables like '%slow_query_log%';
临时配置:set global slow_query_log=1;
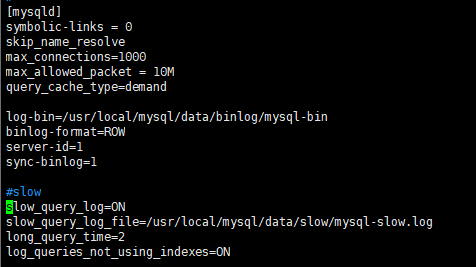
永久配置: [mysqld]下面增加
slow_query_log=on
slow_query_log_file=/usr/local/mysql/data/slow/mysql-slow.log
long_query_time=2
2.开启全表扫描的语句记录
查看开启状态:show VARIABLES like '%log_queries_not_using_indexes%' ;
临时配置开启:set global log_queries_not_using_indexes=1;
永久配置: [mysqld]下面增加 log_queries_not_using_indexes=on
3.慢查询日志的输出
查看配置状态:show variables like 'log_output';
4.慢查询文件的分析工具

| time | 查询时间 |
| user@Host | 用户账号和ip 线程id |
| query_time |
执行话费时长 时间是秒 |
| lock_time | 执行获取锁的时间 |
| rows_sent | 活得结果的行数 |
| rows_examined | 扫描的行数 |
| SET timestamp | 执行的具体时间 |
| SQL语句 |
4.1mysqldumpslow
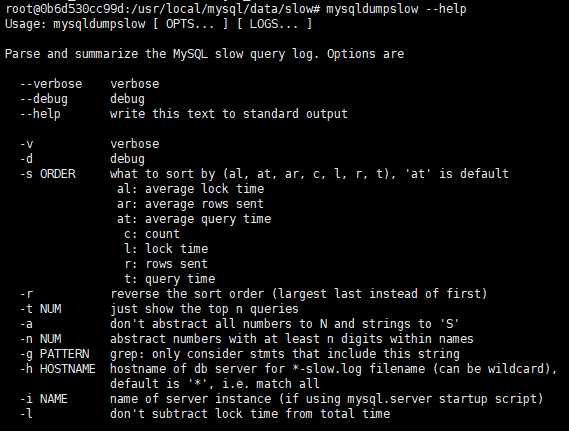
| -s | 排序 |
| al | 执行时获取锁时长平均值 |
| ar | 返回行数的平均值 |
| at | 查询时长的平均值 |
| c | 查询次数 |
| l | 获取锁时长 |
| r | 获得返回行数 |
| t | 执行总时长 |
| -t num | 返回几行 |
| -g pattern | 后面跟正则 筛选 |
按照查询时间排序 取时间最长的前十个语句:mysqldumpslow -s t -t 10 -g select mysql-slow.log
4.2pt-query-digest
5.慢查询本质
查询的数据太多,要确认是否请求了无用的行、列,如limit请求了无用的行,select * 一般而言请求了无用的列,请求的列越多,使用覆盖索引的几率越小 回表的概率越大,速度就会变慢。
但是当在业务层缓存的时候可以用select * 缓存必须用在反复查询的场景里面
复杂查询的where条件 是在引擎层查询后进行筛选的,所以where条件作用在引擎层会更能提高效率
5.1.衡量查询开销的三个指标:响应时间、返回行数、扫描行数
响应时间:服务时间和排队时间的总和
服务时间:数据库处理这个查询真正花费的时间
排队时间:服务器因等待某些资源没有真正的执行查询的时间,可能是等IO操作,也可能是等行锁释放的时间;
所以通过成本计算可以算出这个响应时间是否合理
5.2 返回行数和扫描行数
理想的情况下返回行数和扫描行数应该相等。但是一些情况下 如limit会扫描超出需要行数很多的数据,该查询查找数据的效率不高
5.3扫描行数和访问类型
尽量适应高阶的访问类型 type,如果无法达到则尝试通过创建索引的方式;
5.4where
mysql使用where的三种方式,从效率和扫描行数来看从好到坏依次为
1.在索引中使用where条件过滤不匹配的数据,这是在存储引擎层完成的;
2.使用覆盖索引(extra 出现 using index) 来返回记录,直接从索引中过滤不需要的记录并返回结果,这是在mysql 服务层完成的但无需要回表查询;
3.从数据表中返回数据,然后在过滤不满足条件的记录(在extra 中出现using where) 这是在server层完成过滤的;
5.4优化策略:1) 采用覆盖索引
2)更改表结构,采用反范式设计表结果, 减少联合查询
3)重构sql 复杂查询 分成简单查询,在业务层更好扩展,sql语句是脚本语言 维护起来比较困难;切分查询,每次查询的数据量要控制在 5000~10000之间
4)查看整个sql执行的过程 是否存在吞吐量过大,tcp半双工引起的请求拥挤问题
5.5sql查询执行的全流程
如果把查询sql看成一个任务,那么它有一系列的子任务组成,每个子任务都会消耗掉一本部分的时间,实际上要优化其子任务要么消除掉其中一些子任务,要么减少子任务的执行次数,要么让子任务执行更快。
执行流程:
1.客户端发送一条查询给服务器;
2.服务器先查询缓存中是否有结果,如果有直接返回,没有缓存则进入下一阶段(sql8.0后该模块没有了)
3.sever层进行解析 预处理 再由优化器生成执行计划;
4.mysql根据优化器生成的执行计划调用存储引擎层的api执行查询
5.结果返回给客户端
5.6 mysql 客户端和服务器通讯
他们之间的通讯协议是半双工的,这就意味着在任何一个时刻,要么服务器向客户端发送数据 要么客户端向服务器发数据,这两个过程不能同时存在。
当客户端用一个单独的数据包将查询传送给服务器的时候 sql查询语句很长,需要设置max_allowed_packet。
当服务器向客户端发送数据的时候,客户端必须完整的接受整个结果,保证服务器尽快传送完数据,释放资源。jdbc的库函数会逐条接受数据库传送过来的数据进行缓存,等完全传送完,业务层就可以调用了,有时候传送的数据太多可能引起OOM;
所以MySQL的JDBC里提供了setFetchSize()之类的功能,来解决这个问题:
1、当statement设置以下属性时,采用的是流数据接收方式,每次只从服务器接收部份数据,直到所有数据处理完毕,不会发生JVMOOM。
setResultSetType(ResultSet.TYPE_FORWARD_ONLY);
setFetchSize(Integer.MIN_VALUE);
2、调用statement的enableStreamingResults方法,实际上enableStreamingResults方法内部封装的就是第1种方式。
3、设置连接属性useCursorFetch=true(5.0版驱动开始支持),statement以TYPE_FORWARD_ONLY打开,再设置fetchsize参数,表示采用服务器端游标,每次从服务器取fetch_size条数据。比如:con=DriverManager.getConnection(url);
ps=(PreparedStatement)
con.prepareStatement(sql,ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);
ps.setFetchSize(Integer.MIN_VALUE);
ps.setFetchDirection(ResultSet.FETCH_REVERSE);
rs=ps.executeQuery();
while(rs.next()){……实际的业务处理}
5.7优化器
静态优化器:编译时优化
动态优化器:运行时优化
5.8线程状态
show processlist 可以查看线程状态
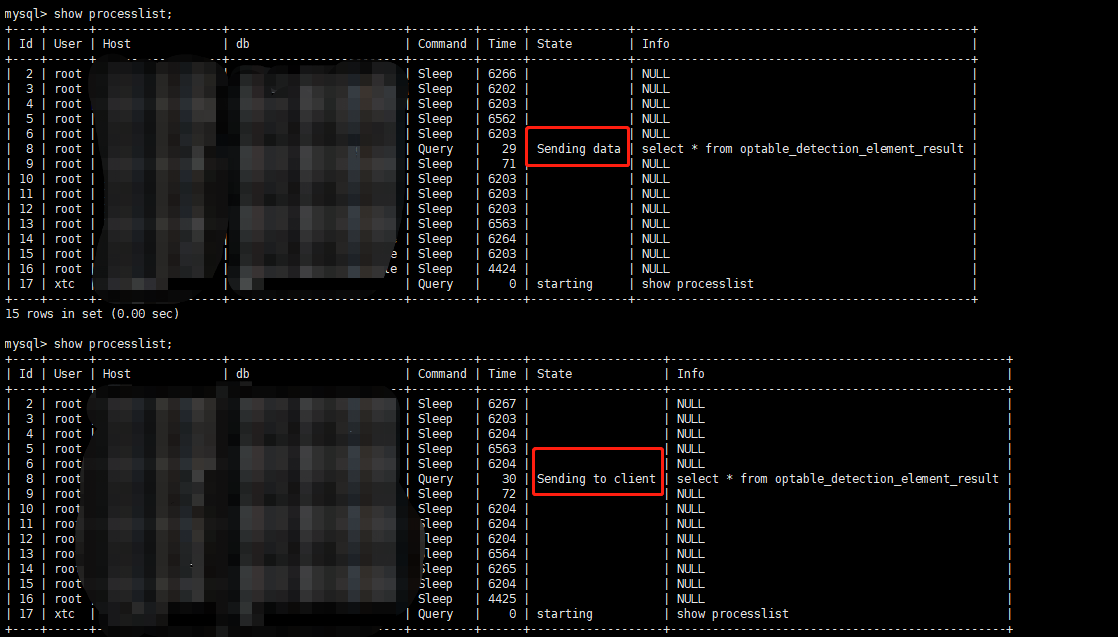
线程状态的官方文档:https://dev.mysql.com/doc/refman/8.0/en/general-thread-states.html
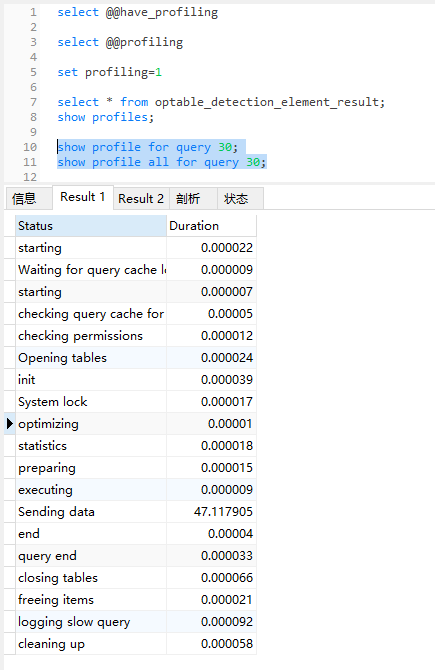
5.9 show profile
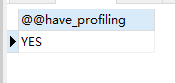
查看是否支持profile :select @@have_profiling;
查看状态:show @@profiling
更改状态:set profiling=1;
查询语句后面紧跟show profiles 查看当前查询语句的queryid

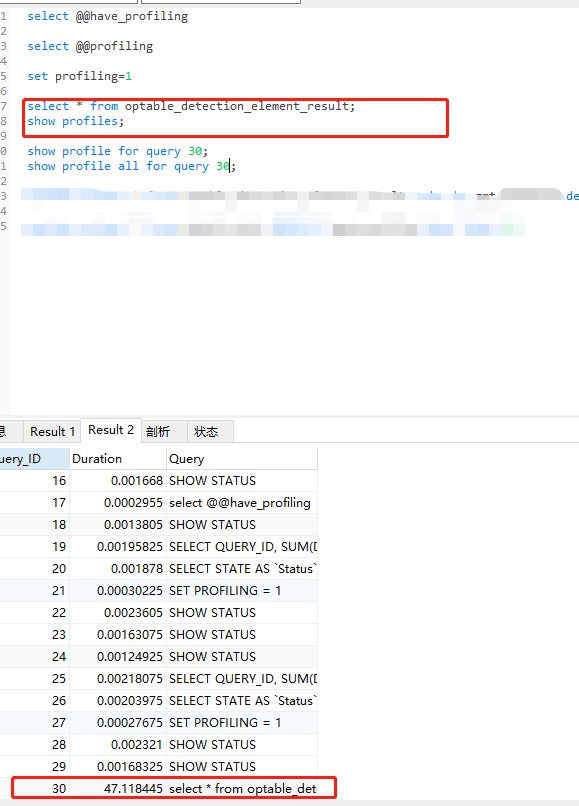
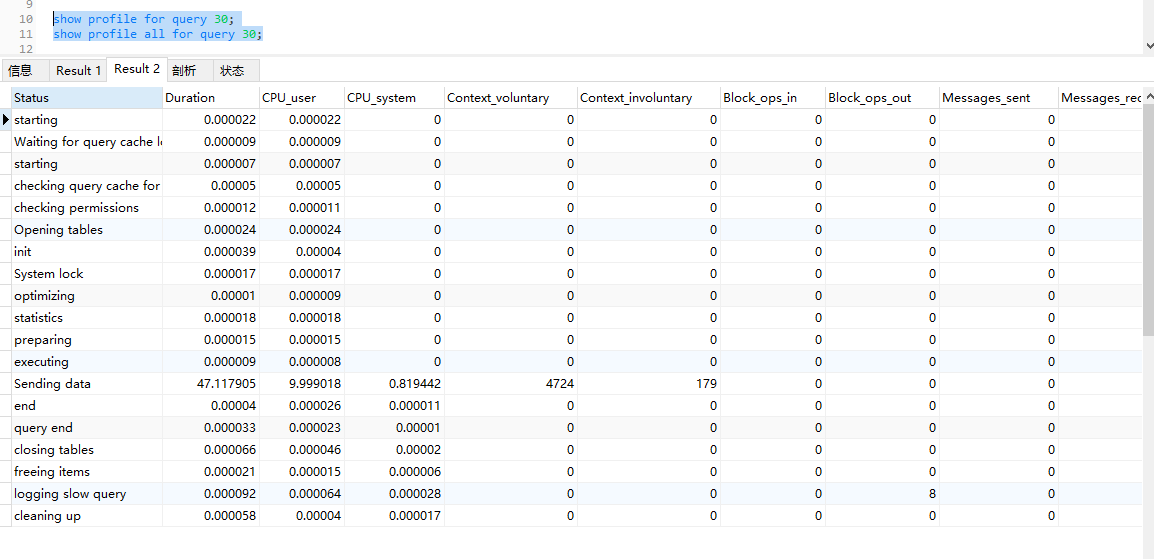
查看这天语句的执行过程用时:
show profile for query 30;
show profile all for query 30;