Iris花的分类是经典的逻辑回归的代表;但是其代码中包含了大量的python库的核心处理模式,这篇文章就是剖析python代码的文章。
1 #取用下标为2,3的两个feture,分别是花的宽度和长度; 2 #第一个维度取“:”代表着所有行,第二个维度代表列范围,这个参数模式其实和reshape很像 3 X = iris["data"][:, (2,3)] 4 y = (iris["target"]==2).astype(np.int) #分类做了数字转化,如果是Iris,ture,则强转为整型1,false则强转为0 5 log_reg = LogisticRegression(C=10**10) #设定C值,C代表精度,是控制外形边缘的准确度,值越大,则精度越高 6 log_reg.fit(X, y) #对于数据进行学习,获取模型参数,比如coef,intercepted等 7 # meshgrid是将参数中p1和p2进行坐标转换,下面将会详细介绍 8 # np.linspace则是将2.9到7等分500份,reshape(-1,1)代表行数根据实际情况,列数为1 9 x0, x1=np.meshgrid(np.linspace(2.9, 7, 500).reshape(-1, 1), 10 np.linspace(0.8, 2.7, 200).reshape(-1,1)) 11 # raval和flatter意义很类似,只不过raval返回的引用,对于返回值的修改将会影响到原始数据(x0,x1),后者则返回copy,和原始数据无关 12 # 关于np.c_则是实现了数组的融合,下面有具体的示例 13 X_new = np.c_[(x0.ravel(), x1.ravel())] 14 # 回归的predic只是返回预测值(返回所有分类中最大的那个),predict_proba则是返回所有类别的预测值 15 y_probe = log_reg.predict_proba(X_new) 16 plt.figure(figsize=(10,4)) 17 # 这个X[y==0, 0]表达的意思比较复杂,代表的是y值是0(0代表某个分类)的对应X值,这个说法完美解释了X[y==0],那么X[y==0, 0]的涵义就是X值的第一个特征值, 18 # 类似的X[y==0,1]代表X值的第二个特征值;从题头可以获知X是两个特征元组集合,第一个代表宽度,第二个代表长度; 19 plt.plot(X[y==0, 0], X[y==0,1], "bs") 20 plt.plot(X[y==1, 0], X[y==1, 1], "g^") 21 zz=y_probe[:, 1].reshape(x0.shape) 22 # contour的意思是等高线(下面有详细的介绍) 23 contour=plt.contour(x0, x1,zz, cmap=plt.cm.brg) 24 plt.clabel(contour, inline=1, fontsize=12) 25 26 left_right=np.array([2.9, 7]) 27 # 这个公式确实不知道是怎么来的,boundary的获取为什么是这个公式? 28 boundary = -(log_reg.coef_[0][0] * left_right + log_reg.intercept_[0]) / log_reg.coef_[0][1] 29 plt.plot(left_right, boundary, "k--", linewidth=3) 30 plt.text(3.2, 1.5, "Not iris", fontsize=14, color="b", ha="center") 31 plt.text(6.5, 2.25, "iris", fontsize=14, color="g", ha="center") 32 plt.axis([2.9, 7,0.8, 2.7]) 33 plt.show()
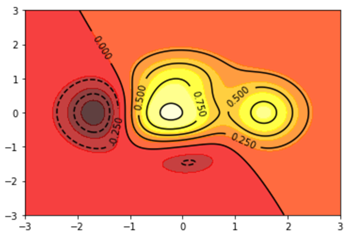
关于数据等高线的示例demo:
1 def height(x, y): 2 return (1-x/2+x**5+y**3)*np.exp(-x**2-y**2) 3 4 x = np.linspace(-3, 3, 300) 5 y = np.linspace(-3, 3, 300) 6 X, Y = np.meshgrid(x, y) 7 plt.contourf(X, Y, height(X,Y), 10, alpha=0.75, cmap=plt.cm.hot) 8 C = plt.contour(X, Y, height(X, Y), colors="black") 9 plt.clabel(C, inline=True, fontsize=10) 10 plt.xticks() 11 plt.yticks() 12 plt.show()
Numpy.c_示例
>>> np.c_[np.array([1,2,3]), np.array([4,5,6])]
array([[1, 4],
[2, 5],
[3, 6]])
>>> np.c_[np.array([[1,2,3]]), 0, 0, np.array([[4,5,6]])]
array([[1, 2, 3, 0, 0, 4, 5, 6]])
参考
数据等高线
https://blog.csdn.net/qq_33506160/article/details/78450
关于meshgrid
https://www.cnblogs.com/sunshinewang/p/6897966.html
https://docs.scipy.org/doc/numpy/reference/generated/numpy.meshgrid.html
关于ravel
https://blog.csdn.net/liuweiyuxiang/article/details/78220080
https://docs.scipy.org/doc/numpy/reference/generated/numpy.ravel.html
关于numpy.c_
https://docs.scipy.org/doc/numpy/reference/generated/numpy.c_.html
关于coef_和intercept_(虽然我并没有看懂)
https://blog.csdn.net/u010099080/article/details/52933430?utm_source=itdadao&utm_medium=referral