二次评分
查询出来结果后,进行二次评分;

但是其实每个文档查询出来的结果是两次查询的分数之和,这个其实并不是很能讲的清楚;
多匹配控制
多匹配是指multi-match,控制则是指一下的几种控制方式:
best_field:多个字段,相同的查询内容,例如:

上面的查询将会被解析为多个match子句:
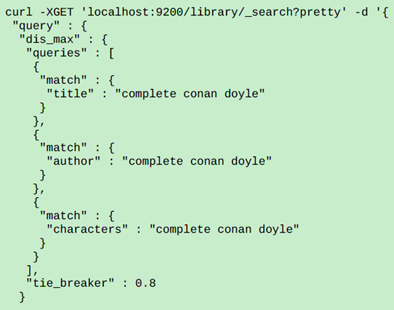
cross_field:至少一个字段包含指定的词项;
most_field:至少一个字段满足所有的词项;
phase_field:将请求翻译为match_phrase;
上述的描述其实并不准确和全面,但是多匹配控制本质就是指定多个字段,来匹配同一个词项/短语;那么多个字段是以怎样的方式来匹配词项/ 短语,上述四种各不相同;具体如果需要了解详细,可以查看官方文档;
重要词项聚合(significant terms aggregation)
这个算法更加复杂,是比较词项在文档出现的频率(后台)和该词项在检索结果中出现的频率,如果两者差别比较大,则做返回,否则过滤掉。下面有一篇博客介绍这个算法的用法,没有深入研究。
https://www.elastic.co/blog/significant-terms-aggregation
文档分组
查询的结果按照某个维度进行分组,比如按照年份,这样查询的数据将会被放到对应的bucket之中去,然后可以指定每个bucket都返回top N,这样就实现了某个分组的数据排序,过滤,控制返回数据量。
文档关系
文档关系主要两种:对象和嵌套,但是要注意,ES是全文检索,对于结构化的支持并不是很好,如果你的查询中真的强结构化的,最好选用支持全文检索的结构化查询数据库。
脚本
- 用于自定义打分规则;
- 用于Query阶段;
- ES支持的是Groovy脚本;
- 还支持Lucene语法;
本文介绍的都是一些比较偏冷的用法,可能并不是真正的偏冷,而是相比于真正的全文检索,他的实现对于具体场景约束比较多,比如二次评分,重要词项聚合,都是一些特殊的场景对于非精确内容的查询;通过这些技术我们也看到了ES本质并不仅仅是查询的插件,还是一个为了模式匹配的工具,本文介绍的其实都是一些查询的模式,或者说查询的规则,查询的本质其实就是过滤规则来遍历存储单元(在ES里面,这几个存储单元就是文档);所以,我们在处理一个查询请求的时候,我们要分析一下这个请求的"查询模式是什么",搞清楚之后,再来考虑那种ES提供的查询工具可以满足需要。
模型的分析,才是使用ES以及其他查询的关键。