关于Lucene里面的查询评分,其实是基于一个公式:TF/ IDF(Term-Frequency/ Inverse Document Frequency),词频率/ 倒排文档频率,这个公式讲了一个故事,就是一个不具备区分度的词,就是它的在各个文档中都有出现(在每个文档中出现次数并不重要),那么这个词就不具备区分度,这个词的权重也就越低,这个就是倒排文档频率的概念。
关于查询改写
我们知道ES是基于Lucene的,对上提供了良好的接口和简易的DSL,但是其实es是做了解析的,其中一种解析是可以通过指定的,这个就是"查询改写";
Scoring_boolean:针对每个文档打分,每个词生成一个should从句,这种改写最耗费CPU,因为需要大量的计算;
Const_score_boolean:这个不再是基于从句的计算,而是基于boost,还记得我们在上一篇文章中有讲到文档的norm的概念,它是基于文档在索引时候的boost值来生成的;那么这个计算过程也是通过计算文档的boost值来获得的。
Top_term_N:和scoring_boolean很类似,每个词项将会被翻译长should查询子句;但是只是保留前N个最佳的词项;那么这个最佳词项的计算是怎么来的?是不是最多只会有N个查询子句?
Top_term_boost_N:和Top_term_N和类似,但是这种并不计算分数(和const_score_boolean类似)。
curl -XGET 'localhost:9200/clients/client/1/_explain?pretty' -d '{
"query" : {
"prefix" : {
"name" : {
"prefix" : "j",
"rewrite" : "constant_score_boolean"
}
}
}
}'
关于查询模板
查询模板,就是可以通过定制一套模板,设定一些占位符,然后通过parameter节点来为这些占位符赋值的方式:
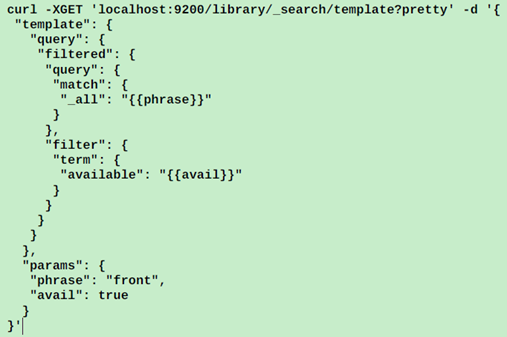
Es的模板式基于musttache模板引擎来制作的;可以基于这些模板来实现条件,循环以及指定默认值等逻辑。
关于过滤器
过滤器不评分,只是过滤,所以检索性能比较好,但是相关性差;
查询(query)有评分环节,所以检索性能比较差,但是相关性好。
过滤器的实现和servlet的过滤器是一样的,都是一个过滤器链,逐条去走。每个过滤器都是基于上一个过滤器检索的条件进行处理;那些"很重"的过滤要考虑放到过滤链的后面;
关于查询分类
1.基本查询,match,match_all等,只有查询索引一个目的;通常是其他复杂查询的一部分。
2.组合查询,bool以及dismax,前者是子查询的分数之和作为文档的分数,后者则是子查询分数最大的那个起到关键作用(从名字上其实可以看出来)。
3.无分析查询,查询不会被ES解析,而是直接传递到lucene做处理,这类查询基本就是把ES当成NoSql来使用;term查询,prefix查询以及wildcard查询等;另外,可以通过对于停用词的二次处理实现高效检索,所谓停用词是指一些类似于"a","the",汉语里面的"啊","也"之类的虚词,介词他们在查询中权重并不高;索性第一轮查询屏蔽到这类停用词,对与权重搞得词做一个查询并打分,然后再针对停用词做一次过滤,只是查询而不计算得分,减少计算量;
4.全文检索,直接使用lucene的查询机制以及查询语法;这类检索比较适合类似于google那种功能,查询结构由用户输入;match,multi_match,simple_query_string以及query_string等;
5.模式匹配查询,prefix,正则,wildcard等;模式匹配计算很昂贵,慎用
6.相似度查询,fuzzy*, more_like*;
7.支持打分操作,可以自定义打分规则,boosting,constant_score,function_score,indices等;
8.位置敏感查询,指定词项之间的距离;match_phrase(可以通过制定splot来指定分词词汇之间的距离),span*;这类查询也是比较耗费cpu的,慎用。
9.结构敏感查询,ES的结构化文档,嵌套文档查询等;但是ES对于结构化的查询并不是专业。