HBase的Scan和Get不同,前者获取数据是串行,后者则是并行;是不是有种大跌眼镜的感觉?
Scan有四种模式:scan,(Table)snapScan,(Table)scanMR,snapshotscanMR;前面两个是串行玩;后面两个是放置到MapReduce中玩;其中性能最好的就是SnapshotScanMR;
首先解释一下什么是snapshort,snapshot是HBase数据表元数据的一个快照,是的,不包括数据;有一点概念要建立清楚,HBase的数据的存储并不是HBase管理,而是HDFS;其实关系型数据库的存储也是OSFS管理的。HBase的设计就是一旦数据写入了,就不改变了,改变操作(update,delete)并不是修改HFile,而是填充墓碑文件而已;所以快照尤其价值,比如可以快速拷贝一个HBase表(只是拷贝表结构,重用原始表的HDFS数据)。
刚才讲的snapshot在scan里面也有应用场景,就是snapshotscan以及snapshortscanMR;注意MR的scan模式就不再是最上面提到的串行查询,而是并行查询;底层机制是Map-reduce;所以就下来而言,MR是要高的;毕竟是多个region查询。
接着,就是ScanAPI的设计:
1. 业务调用HBase Client,HBaseClient首先是查找缓存是否还有数据,如果有则返回数据;
2. 如果没有数据,则通过向RegionServer继续请求下面的100条记录;
3. 作为服务器端接收到next请求之后,将会通过查询BlockCache→HFile→Memstore流程来一行一行的返回数据。
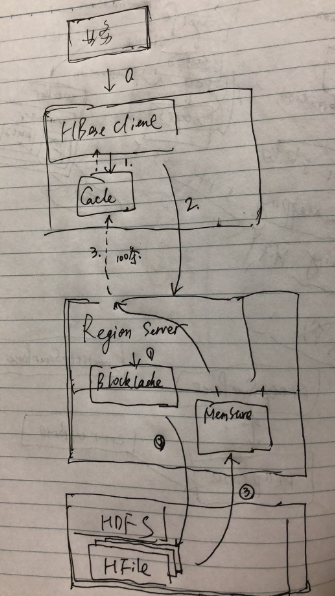
这种API的调用模式(每次返回100条)目的是避免网络资源以及HBase Client端内存资源发生压力;所以可以看到,scanAPI其实只是适合于少量数据的处理;
那么对于海量数据的查询怎么处理呢?就是上面提到的MR;MR整体分为两种:TableScanMR(对应的处理类:TableMapReduceUtil.initTableMapperJob)以及SnapshotScanMR(对应处理类:TableMapReduceUtil.initSnapshotMapperJob),下面两张图表示了在架构上面的差异:

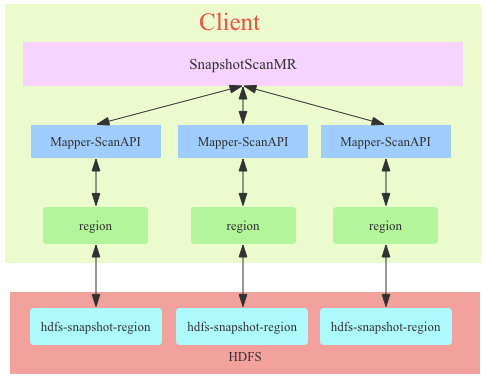
可以看到,模式很类似,都是在client中通过多线程模式进行并行处理;但是snapshotscanMR不再和region server交互,而是直接在客户端和HDFS交互;这样设计的好处即使减轻了Region Server的压力;但是需要事先和Region Server交互,获取snapshot的信息,即HBase的元数据信息(表结构以及hdfs存储信息),这样,就可以跳过region server直接和hdfs地址交互;但是snapshot有一个缺点:实时性不够;可能最近的一些数据的修改没有在snapshot中体现出来。可能会读到一些脏数据(删除更新数据仍然存在,只不过在墓碑记录而已,当然如果merge过后就没了),可能读不到一些最新数据。
参考:
http://hbasefly.com/2017/10/29/hbase-scan-3/
http://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/