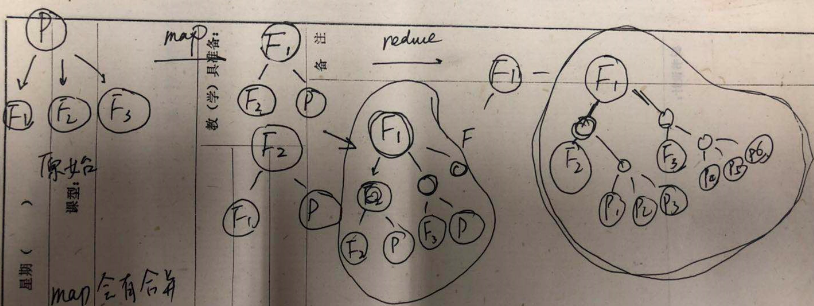
理解MapReduce关键两个步骤;
首先是构想出结构的数据结构,这种数据结构可以支撑你的业务分析使用;是要理解这种模式的处理元素。
第二步,分析原始数据的结构是怎样的;
第三步,基于原始数据结构以及目标数据结构,在分析map的实现逻辑,返回值什么,sort-shuffle之后的值什么,这个值也是reduce的入口参数,然后是reduce的逻辑是什么,以符合目标结构;
map和reduce在处理数据上面的很大差别在于map之后会有一个汇总过程,按照key进行汇聚(发生在sort-shuffle阶段);reduce产生的数据不会再有这个过程,产生的是什么数据,加入到集合中之后,这个数据集合再无其他操作;如果再次把这个数据集合作为下一个阶段的Map-Reduce。
对于"购买过该商品的用户还购买了哪些商品",这个需求,分析过程如下:
0. 目标数据结构是:key:商品(主体);value:关联商品+权值(数量)列表;
1. 实现要明白map的入口参数是什么样子,用户对应一个商品;
2. 分析一下map之后数据,是一个商品对应多个商品;
3. shuffle没有什么特别处理;
3. reduce没有什么特别处理;
下面是第二轮mapreduce:
1. 入口参数是一个用户对多个商品;
2. map返回值某个用户的某个商品对应多个相关联的商品;
3. map之后shuffle合并是个集合,集合中的元素是:key是某个商品,value是相关联的商品List,此时这个list里面可能会有很多重复项;
4. reduce的入口参数是上步中介绍的内容;reduce处理之后,变成了key:某个商品;value:关联商品以及该商品的累加个数;
下面的是应用:基于reduce处理的数据,我们可以获得某个商品关联度最高的前N个商品(累加个数最高的N的)
处理的全流程如下图所示:
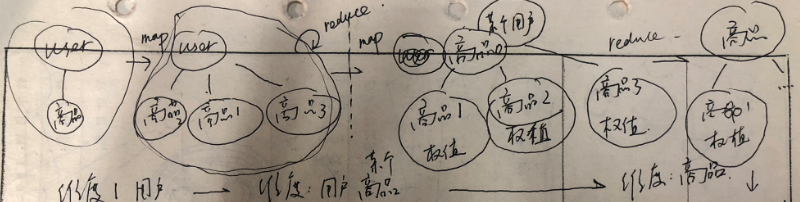
注意其实处理的维度的变化,阶段1map的处理维度还是在user;到了阶段儿的map处理维度是用户+商品,到了阶段2的reduce就抛弃了用户了,而是完全在商品的维度了;reduce的一个功能就是"降维",这个是我的一个说法,其实"降维"是指原本的key不管了,而是从value中在建立一套key-value数据结构;因为reduce功能是group,group意味着可以抛弃一个数据维度,或者说忽略某些个数据维度。
继续,对于"经常一起购买的商品":
0. 构想目标数据结构:key:商品;value:关联商品+权值列表;
1. 你要原始的数据集合中,一条记录的结构是交易-产品列表;
2. 在map阶段,直接"降维",抛弃key(交易ID),对于产品列表做两两配对;shuffle之后的数据集合的元素结构是[<p1,p2>, 1];
3. 到了reduce阶段,就是按照<p1, p2>进行汇聚,输出的是数据集合的元素结构是[<p1, p2>, n];
应用:
找到p1=XX,n最高的3个产品作为推荐。
第三波,难度比较大了,推荐好友,A和B是好友,B是C的好友,那么AC要双向推荐一下。
我最初的想法是做差集;A-B的人向B做推荐,B-A的人想A做推荐;但是这样算法无法获取共同好友,我们登录QQ看到推荐的时候,一般都会看到你和以下人是好友;
0. 构想目标数据结构,key:主体人,value:[推 荐者,List<共同好友>]
1. 原始数据结构:key:主体人,value:List<Friends>
2. map输出的是key:被推荐人;value:[推荐好友, 共同好友(入参的主体人)];shuffle之后是key是推荐人;value推荐好友列表;
3. reduce逻辑则是将被推荐人的推荐好友叠加到List中,同时叠加该推荐好友的共同朋友;