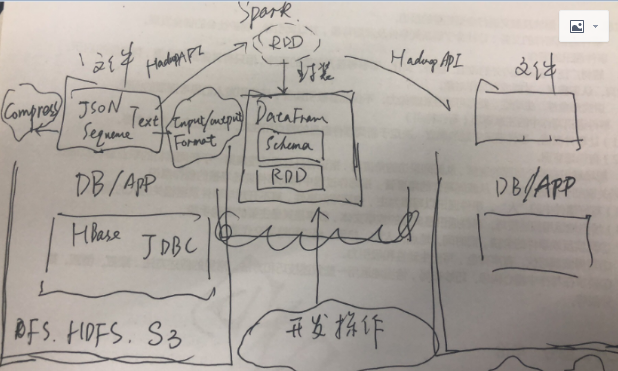
Spark内置了一些常见的文件格式的处理,包括text/json,csv,sequence等;Spark对于文件处理保持了开放性,还提供了可以通过InputFormat,OutputFormat来进行文件处理;这样只要是Hdfs支持文件格式,一定有对应的Format,只要有Input/OutputFormat,就可以在spark中进行读写操作。
Spark对于文件的读写有两类API,其实并不是Spark的两套API,而是Hadoop框架从0.2.0开始就是新老两套API,这两套API主要是设计和扩展性方面的不同,逻辑和效率差别并不大;使用的时候尽量统一。
关于文件的读写,还有就是在为了减少系统在传输上面的压力,Spark内置压缩方式,这样在传输的过程可以减少压力。注意的是压缩的算法需要在各个机器上面都支持才可以;而且在性能上也是有一个权衡,毕竟压缩传输是需要在端对数据进行处理,网络传输时间vs压缩、解压缩处理需要进行平衡和测试。不过对于网络压力比较大的场景,压缩还是应该提倡,毕竟网络资源属于共享资源,发生阻塞损失也会比较大;但是如果解压缩、压缩对于单点机器也是压力,那么也是要考虑;关键还是模拟场景进行测试。但是要注意一点,压缩是存储的事情(是Hdfs决定的);spark只是根据Hdfs的定义来做相应的调整。
spark除了可以针对文件进行处理,支持的其他数据源以及访问数据源方式:jdbc,HBase,Cassandra,ElacsSearch(当然本质也是读取文件);
另外spark支持的文件操作系统包括:常规的操作系统自带文件系统,Hdfs,S3;
Spark SQL结构化数据:DataFrame,在作者成书的年代,还叫做Schema RDD,其实也挺形象,因为DataFrame是由两部分组成:schema+RDD,Schema就是数据的列信息;RDD就是数据的描述。