算法原理
如果某个项集是频繁集,那么这个频繁集中任意子集都是频繁集。所谓频繁集即指该组合出现的概率达到了指定水平;
Aprior算法用来实现查找K个最大频繁项,什么是最大频繁项,就是一组频繁项,任T个子项组合都是T项组合中最频繁的;
频繁项的评估标准有三个,分别是:
支持度(Support),代表含义是X,Y出现的概率
Support(X, Y) = P(X, Y) = Num(X, Y)/Num(All)
置信度Confidence,代表Y出现作为条件,X出现的概率:
Confidence(X←Y) = P(X|Y) = P(XY)/P(Y)
Confidence(X←YZ) = P(X|YZ) = P(XYZ)/P(YZ)
最后一个是提升度(Lift),我们先看公式,描述起来比较复杂:
Lift(X←Y) = P(X|Y) / P(X) = Confidence(X←Y) / P(X)
如果Lift=1,即P(X|Y)=P(X),那么说明X和Y是独立的;如果Lift>1,则说明X和Y是强关联,有Y的地方出现X的概率,比纯X出现概率还要高,所以X和Y是强关联,如果是Lift<1,则说明X和Y是非强关联(无效强关联),因为无法证明是强关联,有Y的地方出现X的概率小于X自身的概率,所以这个结果什么也说明了,只能说明X即使和Y有关联也没那么强的关联。
使用实例
虽然提到了置信度以及提升度,但是作为频繁项的基础算法Aprior(后面很多算法都是基于Aprior的,比如FP-Growth)只是使用到了支持度。
下面我们通过一个Demo的实例来看看Aprior的过程:
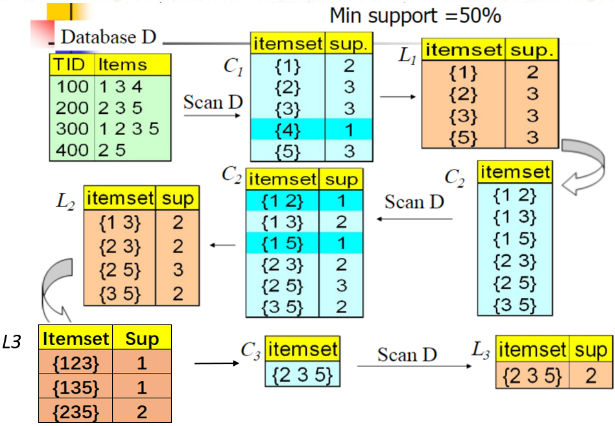
这里有两个地方解释一下:
1. min support是指出现的最低概率,是用:项组合出现的次数/样本总数;项目组合出现的次数是指最终的itemset的个数,这里是{2,3,5},项数为2,;样本总数是4,即TID 100~400,四个原始项集,这样min- support=2/4 = 0.5,即只要小于50%,即出现次数小于2的都是需要过滤的;
2. 关于L3的组合,是由L2的项进行两两组合,组合也是有规则的,组合两项必须是有一项重叠的;类似的如果后面继续组合下去,对于四元素,那么就是L3中元素两两组合,其中重叠项达到两项的才会进行组合;
3. 这种迭代如何终止?我觉得是到达合并后只余下一项为止。
R中实现
R中的apriori的实现封装都是在arules表中。
加载数据:
1 > library(arules) #加载 arules 包 2 > data(Groceries) 3 > Groceries
探索数据
1 > inspect(Groceries[1:5]) 2 > summary(Groceries)
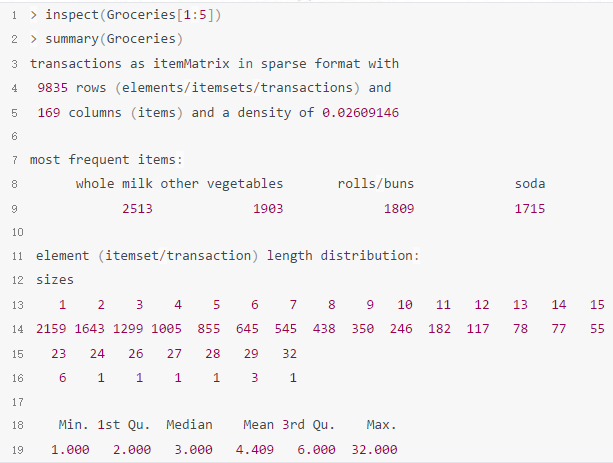
其中summary返回了密度为0.026,其含义为9835条交易记录(代表9835天记录),169代表产品数量,记录数共计9835*169,其中有数据的单元格的数量为9835*169*0.026;most frequent items:则列出了最经常购买的商品;element (itemset/transaction) length distribution:则是将每次购买了物品个数的分布。
> itemFrequency(Groceries[,1:3]) #itemFrequency()函数可以查看商品的交易比例<br>frankfurter sausage liver loaf <br>0.058973055 0.093950178 0.005083884
但是itemFrequency是做什么的?也没有按照概率大小进行排序啊.
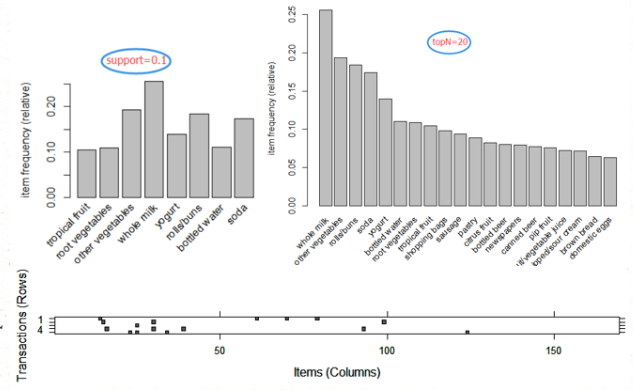
可视化,可以根据支持度,可以根据支持度排序,取top N;最后一个是交易数据列表,即前四笔交易的情况,横坐标是产品(169,)纵坐标是交易,比如第一笔交易(第一行),共计四个产品(四个黑点)
1 > itemFrequencyPlot(Groceries,support = 0.1) # support = 0.1 表示支持度至少为0.1 2 > itemFrequencyPlot(Groceries,topN = 20) # topN = 20 表示支持度排在前20的商品 3 > image(Groceries[1:5])
训练模型
1 > grocery_rules <- apriori(data=Groceries,parameter=list(support =0.1)) 2 > apriori(Groceries)
set of 0 rules
因为support = 0.1,则意味着该商品必须至少出现在 0.1 * 9835 = 983.5次交易中,在前面的分析中,我们发现只有8种商品的 support >= 0.1,因此使用默认的设置没有产生任何规则也不足为奇。修改一下support等参数值:
1 > grocery_rules <- apriori(data=Groceries,parameter=list(support =0.1,confidence =0.8,minlen =3)) 2 > summary(grocery_rules)
通过inspect来进行探测:
1 > inspect(grocery_rules[1:5])
返回内容:

对于上述返回数据我们解读一下,拿第一行的规则为例:{pot plants} => {whole milk} ,support:0.7%代表符合这个规则的交易记录占全部记录的0.7%,confidence=40%则代表购买了pot plants之后,购买whole mile的概率为40%,lift=1.56则是代表同时购买了pot plants和whole mile比上没有购买pot plants却购买了whole mile值为1.56,即增量为0.56;所以只要lift的值>1就说明这两类购买比只买一类被购买概率更大;
我们可以根据训练的结果进行排序,可以通过sort函数进行排序,通过by来指定排序的列,默认是倒叙排列,可以通过decreasing=FALSE来指定进行逆序排列:
1 > inspect(sort(grocery_rules,by="lift")[1:10])
还可以通过subset来提取感兴趣的规则集:
1 > fruit_rules <- subset(grocery_rules,items %in% "pip fruit") 2 > inspect(fruit_rules[1:5])

这里items %in%代表前后匹配指定字符串(这里是pip fruit)。
参考
https://www.cnblogs.com/pinard/p/6293298.html 文章中主要内容参考此文
https://www.cnblogs.com/90zeng/p/apriori.html Aprior原理部分,参考此文
https://www.cnblogs.com/dm-cc/p/5737147.html R代码部分参考此文
附件资源
https://www.rdocumentation.org/packages/arules/versions/1.6-6
https://cran.r-project.org/web/packages/arules/vignettes/arules.pdf
https://michael.hahsler.net/research/association_rules/measures.html