分布式事务是分布式服务中十分重要的概念;提到分布式事务,当然首先要明白ACID,原子性,一致性,隔离性和持久性;隔离性和持久性,分布式数据已经天然满足(数据分布存储满足隔离性,每个节点的数据引擎已经实现了持久性);分布式服务主要是想的是原子性和一致性。
那么下面就是关于原子性和一致性都是由分布式服务的协调者来实现的;在分布式事务的解决方案中有两个角色,分别是协调者和参与者,协调者扮演master的角色,实现全局调度,参与者则是事务的落地执行者(数据节点)。
常见的分布式事务有三种模式两阶段提交以及三阶段提交。
两阶段提交:
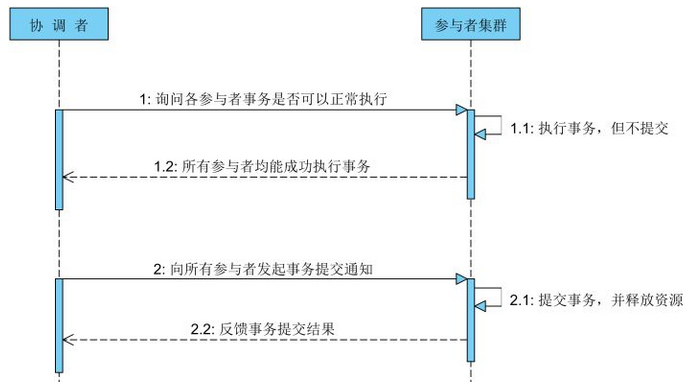
如果在prepare阶段发现有一个节点返回失败,那么在第二个阶段就调用回滚,反之提交。
在开始的时候我一直有一个疑问,就是如果在commit阶段发生异常怎么办?这个是因为并没有真正搞懂数据库层面对于事务层面的处理。在执行事务的时候,其实是两步操作,首先是在提交节点本地创建redo日志和undo日志,前者用于提交失败后的重新提交;后者用于rollback;第二步将对于数据的操作放在数据库Server的节点执行,操作数据得最终结果,在未提交前也是在数据库Server的内存中;到这里,问题解决了,对于第二阶段的一致性,或者说commit异常,其实是由各个提交节点自行基于redo日志文件进行重新提交,从而实现了最终一致性。
但是即使如此,二阶段还是有三个问题:
1)同步阻塞问题,从第一阶段开始到最后一个阶段所有的第三方的资源都是出于锁住的状态(被两阶段的参与者锁住);
2)单点故障,就是一旦协调者挂了,将会导致事务处于一种一直阻塞的状态;
3)数据不一致,这个发生在第二个阶段,就是一旦发生所谓“网络分区”(CAP中P现象)情况,协调者的commit指令下发失败,那么未接收到commit指令的机器将会一直处于足阻塞状态;
总之所有的问题都是两个字“阻塞”,要么协调者挂了,要么网络挂了,都会造成阻塞,进而导致数据不一致的情况。
针对上述问题,提出了三阶段方案:
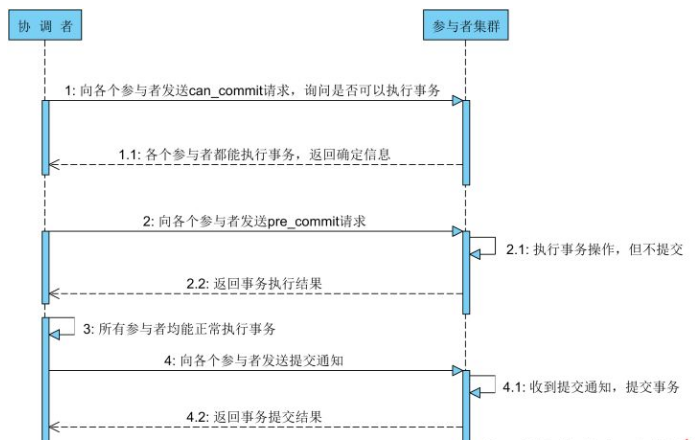
所谓三阶段,和二阶段相比主要的差别有两个,第一个增加了超时机制,这样操作的进程就不会一致阻塞下去;第二个是把prepare阶段华为分两个阶段:第一个阶段就是纯询问(cancommit),比如节点会尝试判断权限是否正常,节点是否正常工作(不正常访问将会超时);第二个阶段(precommit)执行(但是不提交)事务;然后向协调者发送执行状态;为什么要划分,第三个阶段(docommit)就和两阶段内容完全一样了;
为什么要把prepare阶段一分为二呢?回头看一下二阶段,你会发现,协调者询问的时候,其实各个参与者已经在接收询问的时候,便开始执行事务,那么假如有的参与者在执行过程中异常发生异常怎么办?那些已经执行的参与者最终将会通过undo日志进行回滚;为了避免这种情况发生,在三阶段的时候,将会首先确认一下各个参与者是否具备执行事务的能力,路是否都趟平;只有确认没问题的时候,才会想参与者下发precommit指令,开始执行事务。
阻塞问题解决了,那么对于三阶段,为了避免参与者因为某种原因和协调者失联,超时机制出场了,在第二个阶段如果参与者等待docommit指令超时了,就直接执行commit指令;这个其实是一个概率问题,如果因为协调者挂了,那么既然已经走到了第三个阶段,那么大概率是成功(发生分布式异常的情况是少数),于是默认行为是提交。
参考