最近在做视频搜索的技术调研,已经初步有了一些成果输出,算法准确性还可以接受,基本达到了调研的预期。现将该技术调研过程中涉及到的内容总结一篇文章分享出来,内容比较多,初看起来可能关系不大,但是如果接触面稍微广一些,就会发现其实原理都是差不多的。
先描述一下我要解决的问题:上传任意一个车辆截图,需要从海量的监控视频中(高速监控)找到该车辆目标历史经过点位的历史视频录像。这个问题本质上其实就是图像检索或者叫Object-ReId问题,唯一不同的是,找到车辆目标后需要定位到视频录像,后者其实很简单,只需要事先建立好图片和录像片段之间的索引关系即可,跟我们今天要讨论的内容关系不大。(本文图片点击查看更清楚)
图像检索的本质
首先要清楚的是,机器是无法直接理解图像或者声音这种多媒体数据的,甚至也包括一些复杂的结构化数据(比如数据库中的表数据)。传统机器学习中一个常见的概念是“特征工程”,说的是从原始的、复杂的数据中提取出有一定代表意义的特征数据(简单表示,比如用多维向量),这些特征数据相比原数据要简单得多!然后再用算法去分析、学习这些特征数据,得出规律。基于神经网络的深度学习中已经慢慢弱化了“特征工程”这一概念,因为深度学习主流的方式基本都是端到端的流程,输入直接产生输出,特征提取的过程已经在神经网络中的某个部分帮你做完了。

那么现在图片检索的问题,其实已经被转变成“特征数据检索的问题”了。原来需要进行图像比对,现在只需要进行特征比对,而显然机器更擅长后者。
Object-ReId/Person-ReId/Vehicle-ReId的原理
ReId技术一般用于多摄像机目标重识别的场合,目标经过多个点位被多个摄像机拍摄录像存储,输入该目标的一张截图,可以利用ReId的技术将该目标经过的点位找出来,用于后续的运行轨迹分析,该技术一般用于安防/公安领域,目标一般可以是行人(Person-ReId)和车辆(Vehicle-ReId)。ReId的核心就是前面提到的图像检索技术,从海量图片中(视频由图片组成)检索指定的图片,那么这个检索的准确性就依赖于前面提到的特征比对算法准确性了。
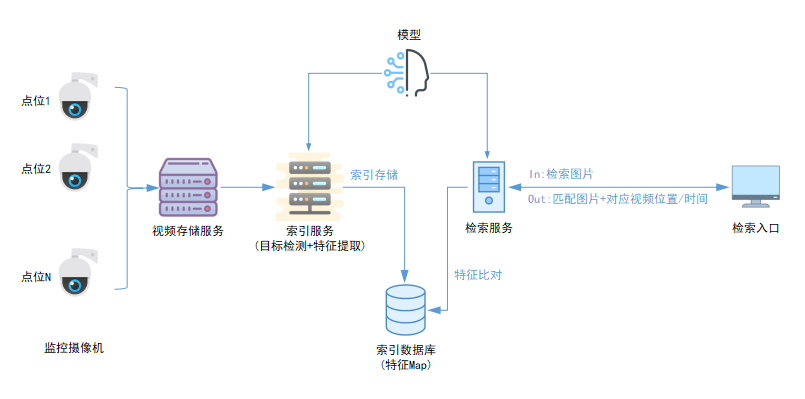
上图描述了Vehicle-ReId的一个完整流程,我们可以看到特征比对只是其中的一个环节,完整的流程还要包括车辆目标提取(目标检测)、特征提取、索引建立。
图像特征提取
前面已经知道了图像检索的本质其实就是特征的比对,那么这个特征应该如何提取得到呢?
传统的机器学习可能需要手工设计算法去提取特征,提取的方式有多种多样,拿图像而言,可以从颜色角度入手,提取图像的颜色特征。比如大部分人可能比较熟悉的颜色直方图,这个算法就可以用来计算图像的“像素组成”(比如各种颜色分别占比多少),像素组成确实可以在一定程度上代表原始图片。在某些数据集中,像素组成相似的原始图片也比较相似。然后拿像素组成数据去做分类/聚类,基本就可以搞定这种机器学习任务。
现在流行的深度学习已经抛弃了人工提取特征的做法,取而代之的是直接上神经网络。还是拿图像而言,直接用卷积网络无脑卷一卷,就可以得到对应的图像特征。这种方式提取到的特征是unreadable的,不像像素组成,它确实可以被人理解。卷积网络最后提取到的特征人工无法直观理解,它可能仅仅是一个高维向量,不做处理的话,你都无法在二维/三维空间中显示出来。所以很多人说深度学习(神经网络)是不可解释的,在某种程度上它确实无法被解释。

由前面的内容我们不难发现,特征提取是非常重要的一步,直接关系到后面基于特征的一切应用的准确性。特征是对原始数据的一种表达,是计算机容易识别的一种理想格式。理想情况下,特征之间的特性和规律可以直接反应原始数据之间的特性和规律。传统机器学习过程中,如何找到合适的特征提取方法是一项非常难的事情,现在主流的深度学习过程中,已经简化了该步骤。
需要注意的是,一些论文、博客、文章中对特征的称呼不尽相同,比如Features(特征)/Representation(表达或表示)/Embedding(嵌入)/Encoding(编码)等等基本都是一个意思(注意中文翻译可能不太准确)。其实从这些英文单词不难看出,不管用什么词,人们想要表达的意思大概都是差不多的,即特征是对原数据的简要表达。
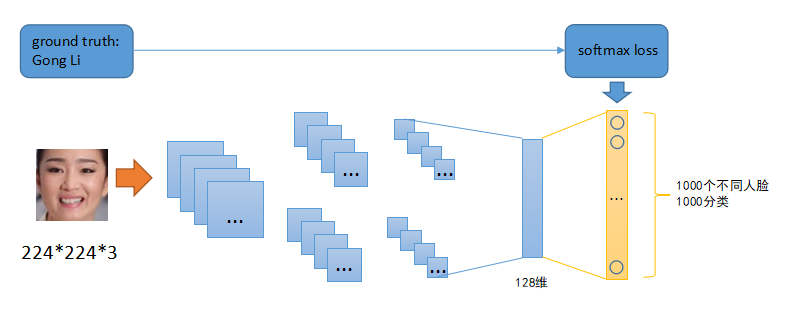
上图是深度学习中利用神经网络来提取特征,原始神经网络是一个多分类网络,我们可以使用分类数据集去拟合该神经网络中的参数,待训练完毕后,去掉最上(最右)用于分类的网络层,倒数第二层即可输出128维的特征数据。基于这个128维的特征数据,我们可以做很多事情:
1、原网络做的分类任务。例子中原网络本身就是一个分类网络,对这些特征数据进行分类,推理出原输入图片的类型。看看是巩俐还是奥巴马;
2、本文的重点。特征数据比对,用于图像检索、人脸识别、Vehicle-ReId等;
3、用于无监督学习。先对一堆没有标签的图片数据集合进行特征提取,基于这些特征数据利用K-Means或DBSCAN等算法自动将这些图片分成若干类,类似Iphone相册自动分类功能(比如相同的人脸归为一类)。
总之,特征数据非常有用,是一切机器学习(深度学习)任务中的重中之重。
图像特征比对
前面已经多次提到特征比对,那么特征比对的方式有哪些呢?二维空间中的2个点,我们可以通过计算之间的直线距离来判断它们是否相似(越小越相似,为零表示完全相同。反之亦然);三维空间中的2个点,我们照样可以通过计算之间的直线距离来判断它们是否相似(越小越相似,为零表示完全相同。反之亦然)。那么对于更高维的点呢?照样可以用这种方式去做比较!
这里需要说的是,直线距离只是手段之一,还有其他距离可以计算。比如不太常见的余弦距离,它代表两个点到坐标原点线段之间的夹角余弦值,角度越小代表2点距离越近。余弦距离跟直线距离不同,一个是用角度大小衡量、一个是用线段长短衡量。
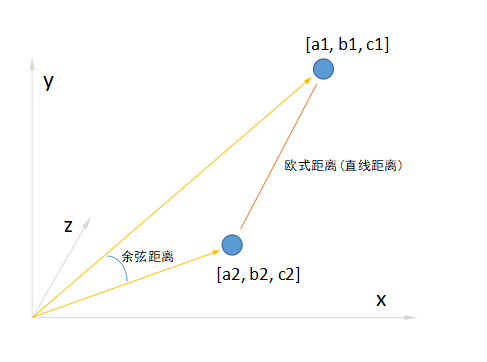
我们可以看到,直线距离(欧氏距离)关注点是2个特征的各个维度具体数值,而余弦距离关注点是2个特征的维度分布。直线距离为零,代表2个特征的各个维度数值完全相同;而余弦距离为零,代表2个特征的维度分布完全相同。(1, 1, 1)和(2, 2, 2)两个特征的直线距离不为零,因为它们各个维度的数值不同,但是它们的余弦距离为零,因为它们的维度分布是完全一样的,都是1:1:1。
举一个实际的例子,张三的语数外三科的成绩为(80, 80, 80),李四的语数外三科的成绩为(90, 90, 90),这两的直线距离不为零,李四的三科成绩明显跟张三不同。但是这两的余弦距离为零,可以理解为李四的三科平衡程度跟张三一致,都不偏科。所以不同的距离代表含义不同,直线距离可以用来衡量他们的成绩是否差不多,而余弦距离则可以用来衡量他们偏科程度是否差不多。两个距离,视角不一样。
高维特征降维和可视化
前面举例子用的是二维或者三维数据,其实特征数据大部分时候都是高维的,比如128维或1024维等等。在不做任何处理的情况下,我们无法直观看到这些高维数据之间的关系,因为它既不是二维的我们可以画到平面坐标系中、也不是三维的我们可以画在立体坐标系中。如果想要直观看到数据之间的关系,我们需要对这些特征再次进行降维处理,将之前的高维数据一一映射到二维或者三维空间。比如现在提取到了1000张图片的特征数据,每个数据都是128维,我们如果想要在二维或三维空间观察这1000个特征数据之间的关系(比如特征数据之间的紧密程度),从而判断原始图片之间的关系、或已经知道原始图片之间的关系我们需要验证提取到的特征数据是否合理。
值得高兴的是,已经有非常成熟的降维技术可以使用,比如常见的PCA和t-SNE算法,直接可以将高维数据降到二维或者三维,而依然保留原始数据的特性。通过这些手段我们可以直观看到高维特征数据在二维/三维空间中的呈现,从而观察原数据之间的关系。下图是我提取高速公路视频画面中车辆目标的特征数据,原始特征是128维,然后利用t-SNE算法进行降维处理,最后得到的二维格式数据并在二维坐标系中将原始图片一一对应绘制出来。

我们可以看到,外观相似的车辆(这些图片是随机抽取的,并没有标签数据)聚集在一起,用前面讲到的距离来说,就是越相似的图片特征距离越近。这个可视化的过程基本可以证明我前面设计的特征提取网络是合理的,这个网络用于提取其他类似车辆图片的特征也是OK的。
看到这里的朋友其实可能已经注意到,机器学习(或深度学习)的主要工作其实说白了就是一个不断对数据进行降维的过程,我们可以将原始非结构化数据诸如文字/图片/音频看成是一个维度很高(超高维)的数据格式,然后设计算法将这些超高维数据降到低维格式,再去应用。前面讲到的特征提取也算是降维的一种。
自编码器
谈到降维技术,这里我想介绍一个超级牛逼的结构,学名叫auto-encoder(翻译过来就是自编码器)。我刚开始接触这个东西的时候就感叹于它的神奇强大,因为它结构相当简单,而且理解起来并不费劲,但是起到的效果惊人。它的结构是对称的,前面半部分主要对输入(一般指图片)进行编码,其实就是特征提取,比如提取得到一个128维的特征数据。后半部分马上对该特征进行解码,还原成原来的图片。前半部分叫编码器,后半部分叫生成器。这个东西可以由两个神经网络组成,大概结构类似如下图:
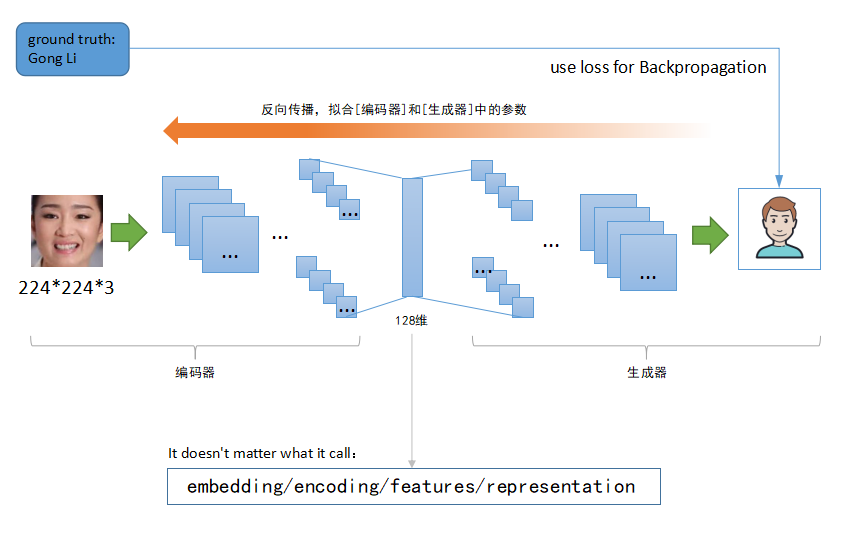
如上图这种结构的神经网络训练也相当容易,你的训练数据集不需要提前标注,因为网络的输出就是网络的输入,换句话说,你可以把它当作无监督学习!有人可能就要问了,一编一解到底想要干什么呢?这样操作的主要目的是得到中间的特征数据(论文术语叫space representation),没错,用这种方式训练出来的前半部分可以当作一种特征提取器(原定义叫编码器),将它作用在其他类似图片数据上,就可以得到对应的特征数据,起到的作用跟前面介绍的其他特征提取方式差不多。
这种自编码器的一大优势是训练它的数据集合不需要标注,训练是一个无监督学习过程。它不像前面提到的那些特征提取方法,大部分都是基于监督学习的。也就是虽然我们的目的是训练一个特征提取的网络(网络输出是高维特征数据),但是往往需要提前准备带有标签的训练数据(如分类数据)。当然,除了这里提到的自编码器之外,还有其他的一些特征提取结构,也属于无监督学习的范畴,比如孪生网络、或者采用triplet loss训练时,这些都是无监督学习的例子。
AI换脸技术
这个话题其实跟今天谈到的特征数据(提取/比对)关系不是特别大,只是前面我已经提到了自编码器,知道了这个结构的前半部分能够应用于特征提取的任务,而刚才没说的是,它的后半部分(生成器)是可以用于AI换脸的,之前火爆全网的AI换脸可以采用类似技术实现。
其实AI换脸原理也非常简单,自编码器的前半部分用于人脸编码(特征数据,下同),它的后半部分基于该编码进行人脸还原(图像生成),这个过程即是我们进行网络训练的过程:一个人脸输入,不断拟合网络让它输出同一个人脸。如果我们在应用该网络结构的时候稍微改变一下:将A人脸输入到它的编码器,得到它的人脸编码后,不要使用对应的生成器去还原人脸,而是改用另外B人脸的生成器去还原人脸!那么会得到什么呢?答案是:得到一张A的脸部轮廓+B的五官细节。下图显示AI换脸的技术原理:
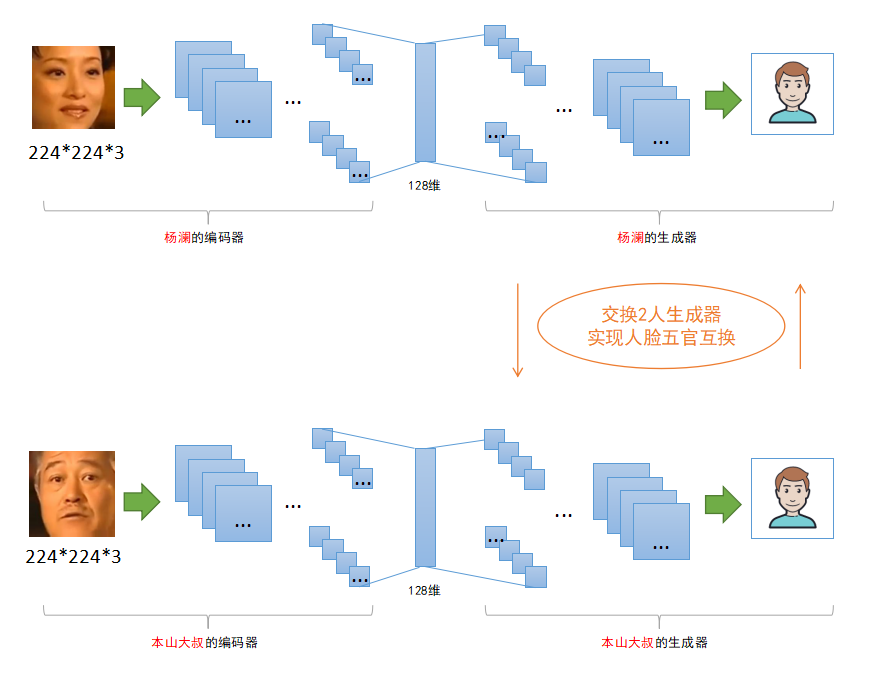
如上图可知,编码器输出的人脸编码在某种意义上可以看作是脸部轮廓的表示,生成器基于该轮廓进行五官细节恢复,最终得到一个合成后的人脸。下面是一个将赵本山五官换到杨澜脸部的例子(完整视频链接):

通过AI换脸的这个例子我们可以得知,特征提取相当重要,整个流程能够正常work(或work得很好)大部分依靠中间生成的特征数据(人脸编码)。神经网络的神奇之处就在于,有些东西你无法解释,但是就是凑效。
其他常见的无监督学习
既然提到了AI换脸,索性就将本篇文章的主题扯远一些。自编码器的训练过程属于无监督学习的范畴,根据相关大神的名言:无监督学习才是真正的人工智能。确实没错,监督学习在某些场合有非常多的局限性。那么除了上面提到的自编码器训练属于无监督学习,机器学习领域还有哪些无监督学习的例子呢?
1、类似K-Means这些聚类算法,算法可以自动从给定的数据(特征数据)寻找规律,无需事先提供参考样例
2、类似t-SNE这种降维算法,算法可以自动从给定的数据(特征数据)寻找规律,无需事先提供参考样例
3、类似上面提到的自编码器,以及其他一些生成型网络,包括GAN相关技术,都属于无监督学习
4、类似采取triplet loss等技术直接操控特征数据的网络训练方式(基于特征数据计算loss),也属于无监督学习
只要在训练过程中无需事先提供参考样例(标注样本)的机器学习过程全部都可以看作是无监督学习,无监督学习跟算法并没什么直接关系,传统机器学习、现在主流基于神经网络的深度学习都可以有无监督学习方式。
好了,本篇文章到这里结束了。由于时间原因,以及查资料验证费时间,前前后后花了半个月功夫。其实主要目的是为了说明特征数据在机器学习(深度学习)领域的重要性,这个领域基本所有的东西全部围绕它展开的,所有的原始非结构化数据/结构化数据都需要先转成特征数据,再被机器学习算法(深度学习神经网络)学习。
