服务器A :192.168.1.190 (Prometheus、alertmanager)
服务器B :192.168.1.206(Prometheus、alertmanager、influxdb、nginx)
基本HA + 远程存储
在基本HA模式的基础上通过添加Remote Storage存储支持,将监控数据保存在第三方存储服务上。
在保证Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues
Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues
Server的可迁移性的场景。

在B 上使用docker安装influxDB库
mkdir -p /data/infuxdb
vi /data/infuxdb/docker-compose-monitor.yml
version: '2' services: influxdb: image: influxdb container_name: influxdb hostname: influxdb restart: always command: -config /etc/influxdb/influxdb.conf ports: - "8086:8086" - "8083:8083" volumes: - /data/influxdb/conf:/etc/influxdb - /data/influxdb/data:/var/lib/influxdb/data - /data/influxdb/meta:/var/lib/influxdb/meta - /data/influxdb/wal:/var/lib/influxdb/wal environment: - INFLUXDB_DB=prometheus - INFLUXDB_ADMIN_ENABLED=true - INFLUXDB_ADMIN_USER=admin - INFLUXDB_ADMIN_PASSWORD=xxx - INFLUXDB_USER=prom - INFLUXDB_USER_PASSWORD=xxx
启动后创建一个名称为 prometheus 的库
docker exec -it influxdb bash
influx
create database prometheus
Prometheus集群
在A和B 上分别使用docker安装Prometheus
参照https://www.cnblogs.com/xiaoyou2018/p/14037006.html
A :http://192.168.1.190:9090
B :http://192.168.1.206.9090
在B 上安装nginx,使用nginx代理A和B
[root@kibana vhost]# cat prometheus.conf upstream prom.midust.com{ server 192.168.1.190:9090 max_fails=0 fail_timeout=0s weight=3; server 192.168.1.106:9090 max_fails=0 fail_timeout=0s weight=3; keepalive 300; } server { listen 80; server_name prom.test.com; access_log /var/log/nginx/prom.midust.com.access.log; error_log /var/log/nginx/prom.midust.com.error.log; # Load configuration files for the default server block. #include /etc/nginx/default.d/*.conf; location / { proxy_pass http://prom.test.com; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for; proxy_redirect default; proxy_http_version 1.1; proxy_set_header Connection ""; } error_page 404 /404.html; location = /40x.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }
解析之后,
访问 http://prom.test.com
A和B 上的Prometheus 接入 influxdb
A 读和写
B只读
安装remote_storage_adapter 组件
链接:https://pan.baidu.com/s/1c0rWQhRg9QZpDb4eadkeOg
提取码:cu6n
放在 /data/prometheus目录
A和B 分别运行
nohup /data/prometheus/remote_storage_adapter --influxdb-url=http://192.168.1.206:8086 --influxdb.username=prom --influxdb.database=prometheus --influxdb.retention-policy=autogen &
A和B 上的Prometheus.yml 文件修改
A 的Prometheus.yml最后添加
remote_write: - url: "http://192.168.1.206:8086/api/v1/prom/write?db=prometheus&u=prom&p=xxx" remote_read: - url: "http://192.168.1.206:8086/api/v1/prom/read?db=prometheus&u=prom&p=xxx"
B 的Prometheus.yml最后添加
remote_read: - url: "http://192.168.1.206:8086/api/v1/prom/read?db=prometheus&u=prom&p=TTdjy911.500"
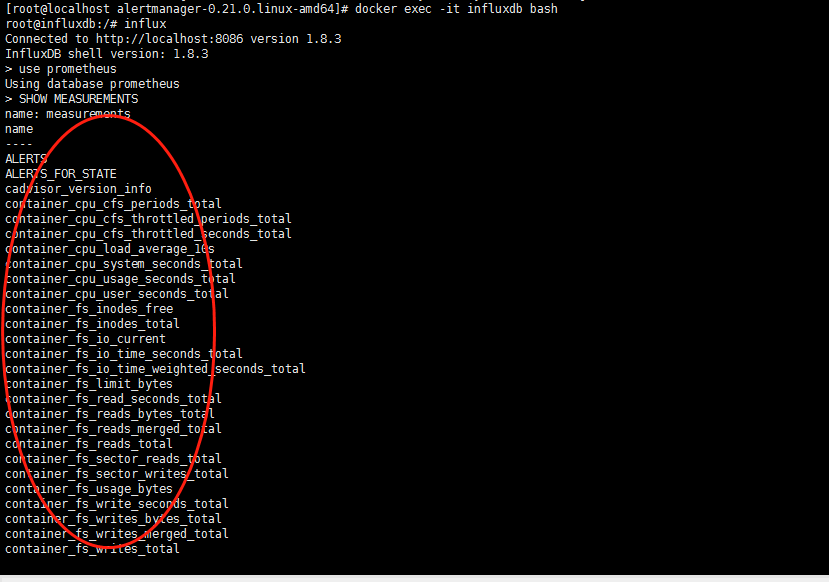
稍等一会查看influxdb是否有数据
[root@localhost alertmanager-0.21.0.linux-amd64]# docker exec -it influxdb bash root@influxdb:/# influx Connected to http://localhost:8086 version 1.8.3 InfluxDB shell version: 1.8.3 > use prometheus Using database prometheus > SHOW MEASUREMENTS
显示如下说明成功
管理influxDB 工具“InfluxDBStudio”
链接:https://pan.baidu.com/s/1c0rWQhRg9QZpDb4eadkeOg
提取码:cu6n
influxDB 设置保留数据期限:
Using database prometheus
> show retention policies
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 2160h0m0s 168h0m0s 1 true
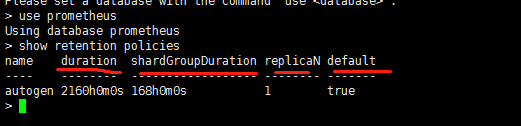
retention policy描述了influxdb中的数据会保留多长时间、数据保留几个副本(开源版的只能保留一个副本),以及每个shard保存多长时间的数据。每个influxdb数据库都有一个独立的retention policy。这里面涉及到几个基本概念,下面描述一下。
DURATION:这个描述了保留策略要保留多久的数据。这个机制对于时序型的数据来讲,是非常有用的。
SHARD:这个是实际存储influxdb数据的单元。每个shard保留一个时间片的数据,默认是7天。如果你保存1年的数据,那么influxdb会把连续7天的数据放到一个shard中,使用好多个shard来保存数据。
shard duration这个描述了每个shard存放多数据的时间片是多大。默认7天。需要注意的是,当数据超出了保留策略后,influxdb并不是按照数据点的时间一点一点删除的,而是会删除整个shard group。
SHARD GROUP:顾名思义,这个一个shard group包含多个shard。对于开源版的influxdb,这个其实没有什么区别,可以简单理解为一个shard group只包含一个shard,但对于企业版的多节点集群模式来讲,一个shard group可以包含不同节点上的不同shard,这使得influxdb可以保存更多的数据。
SHARD REPLICATION:这个描述了每个shard有几个副本。对于开源版来讲,只支持单副本,对于企业版来讲,每个shard可以冗余存储,这样可以避免单点故障。
默认数据一直保留
如果想修改retention policy的数据保留时间,可以使用alter retention policy语句
alter retention policy autogen on prometheus duration 30d REPLICATION 1 SHARD DURATION 7d default
alertmanager集群
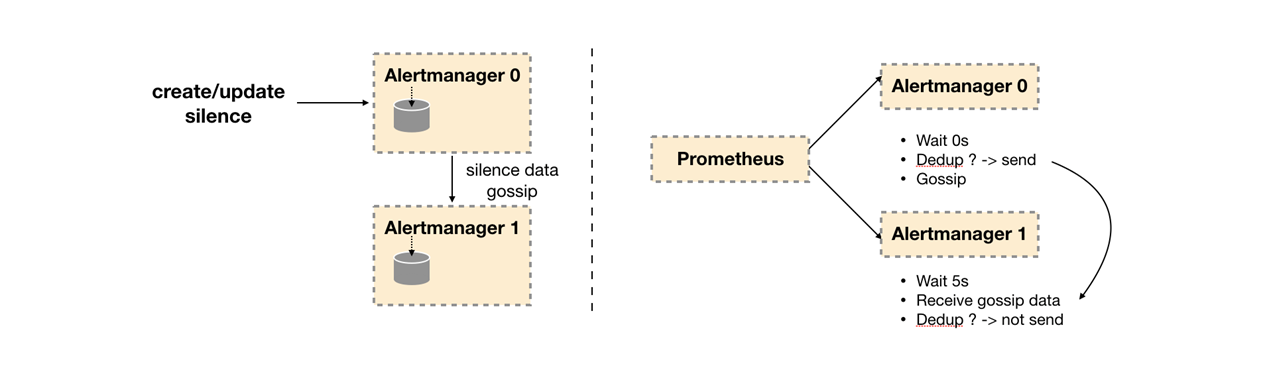
Alertmanager引入了Gossip机制。Gossip机制为多个Alertmanager之间提供了信息传递的机制。确保及时在多个Alertmanager分别接收到相同告警信息的情况下,也只有一个告警通知被发送给Receiver。
Gossip协议
Gossip是分布式系统中被广泛使用的协议,用于实现分布式节点之间的信息交换和状态同步。Gossip协议同步状态类似于流言或者病毒的传播,如下所示:

Gossip分布式协议
一般来说Gossip有两种实现方式分别为Push-based和Pull-based。在Push-based当集群中某一节点A完成一个工作后,随机的从其它节点B并向其发送相应的消息,节点B接收到消息后在重复完成相同的工作,直到传播到集群中的所有节点。而Pull-based的实现中节点A会随机的向节点B发起询问是否有新的状态需要同步,如果有则返回。在简单了解了Gossip协议之后,我们来看Alertmanager是如何基于Gossip协议实现集群高可用的。如下所示,当Alertmanager接收到来自Prometheus的告警消息后,会按照以下流程对告警进行处理:

通知流水线
- 在第一个阶段Silence中,Alertmanager会判断当前通知是否匹配到任何的静默规则,如果没有则进入下一个阶段,否则则中断流水线不发送通知
- 在第二个阶段Wait中,Alertmanager会根据当前Alertmanager在集群中所在的顺序(index)等待index * 5s的时间。
- 当前Alertmanager等待阶段结束后,Dedup阶段则会判断当前Alertmanager数据库中该通知是否已经发送,如果已经发送则中断流水线,不发送告警,否则则进入下一阶段Send对外发送告警通知。
- 告警发送完成后该Alertmanager进入最后一个阶段Gossip,Gossip会通知其他Alertmanager实例当前告警已经发送。其他实例接收到Gossip消息后,则会在自己的数据库中保存该通知已发送的记录。
因此如下所示,Gossip机制的关键在于两点:
Gossip机制
- Silence设置同步:Alertmanager启动阶段基于Pull-based从集群其它节点同步Silence状态,当有新的Silence产生时使用Push-based方式在集群中传播Gossip信息。
- 通知发送状态同步:告警通知发送完成后,基于Push-based同步告警发送状态。Wait阶段可以确保集群状态一致。
Alertmanager基于Gossip实现的集群机制虽然不能保证所有实例上的数据时刻保持一致,但是实现了CAP理论中的AP系统,即可用性和分区容错性。同时对于Prometheus Server而言保持了配置了简单性,Promthues Server之间不需要任何的状态同步。
下载alertmanager 组件,放在
https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
A和B 都安装
tar zxvf alertmanager-0.21.0.linux-amd64.tar.gz -C /data/alertmanager/
服务器A
vi /etc/systemd/system/alertmanager.service
[Unit]
Description=Alertmanager
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/data/alertmanager/alertmanager-0.21.0.linux-amd64/alertmanager --web.listen-address=":9093" --cluster.listen-address="192.168.1.190:9094" --cluster.peer=192.168.1.206:9094 --config.file=/data/alertmanager/alertmanager-0.21.0.linux-amd64/alertmanager.yml
[Install]
WantedBy=multi-user.target
启动alertmanager
systemctl daemon-reload
systemctl start alertmanager
systemctl status alertmanager
服务器B
vi /etc/systemd/system/alertmanager.service
[Unit] Description=Alertmanager After=network-online.target [Service] Restart=on-failure ExecStart=/data/alertmanager/alertmanager-0.21.0.linux-amd64/alertmanager --web.listen-address=":9093" --cluster.listen-address="192.168.1.206:9094" --cluster.peer=192.168.1.190:9094 --config.file=/data/alertmanager/alertmanager-0.21.0.linux-amd64/alertmanager.yml [Install] WantedBy=multi-user.target
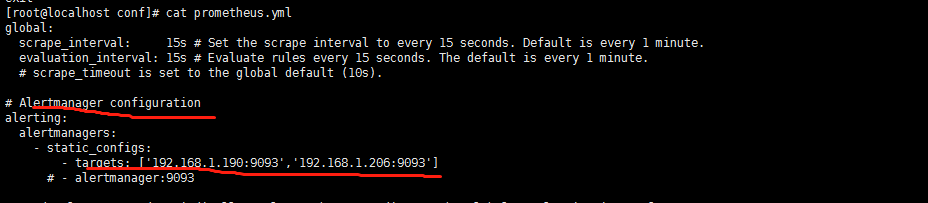
修改Prometheus.yml文件的Alertmanager configuration
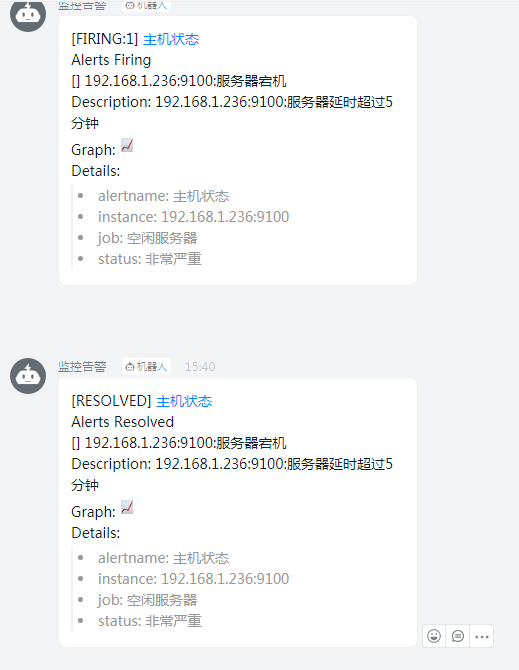
验证:
关闭一台服务器的node_exporter
登录 http://192.168.1.190:9093 和 http://192.168.1.206:9093
都能看到接收到的告警信息,但是钉钉只接收到一条告警