由于项目的需要,使用到了全文检索技术,这里将前段时间所做的工作进行一个实践总结,方便以后查阅。在实际的工作中,需要灵活的使用lucene里面的查询技术,以达到满足业务要求与搜索性能提升的目的。
一、全文检索介绍
1.1为什么需要全文检索
数据可以分为结构化数据和非结构化数据,对数据查询时,结构化数据可以通过SQL语句等方式查询,而非结构化数据(如txt,word等)无法用此方式查询。
我们利用将非结构化数据转化为非结构化数据(即先将文件中单词按空格拆分,把单词创建一个索引,然后查询索引,根据单词和文档的关系找到文档列表,即全文检索),进行快速查询。
1.2什么是全文检索
先创建索引,然后查询索引的过程是全文检索
具有一次创建,多次使用的特点(创建的速度有点慢)。
二、全文检索流程
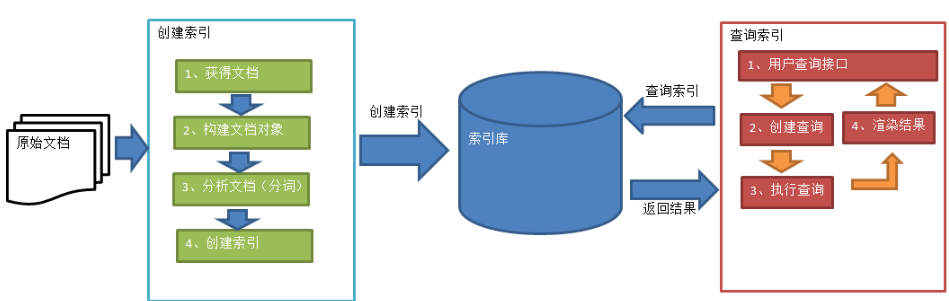
1. 绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:确定原始内容即要搜索的内容→采集文档→创建文档→分析文档→索引文档。
2. 红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面→创建查询→执行搜索,从索引库搜索→渲染搜索结果。
三、全文检索索引
3.1倒排索引
倒排索引即为全文检索的核心的部分,所谓倒排索引,简单地就是,根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。这就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他的一些策略(如页面点击投票率)等来给你返回结果。这个过程中,倒排索引就起到很关键的作用。

3.2创建索引
你可以利用你的技术从数据库、互联网、爬虫、word等方式获取原始数据,即采集信息
3.3构建索引文档
对应每个原始文档创建一个Document对象(拥有唯一的ID)
每个Document中包含多个Field
不同的Document可以有不同的Field
同一个Document可以有相同的Field
域中以键值对的形式保存域的名称和值
四、全文检索使用
1、所需核心库
|
lucene-core |
lucene核心库 |
|
lucene-queryparser |
lucene查询解析器 |
|
lucene-analyzers-common |
lucene默认分词器 |
|
lucene-analyzers-smartcn |
lucene提供的中文分词器 |
|
ik-analyzer |
开源中文分词器 |
2、lucene查询
|
查询方式 |
意义 |
| TermQuery | 精确查询 |
| TermRangeQuery | 查询一个范围 |
| PrefixQuery | 前缀匹配查询 |
| WildcardQuery | 通配符查询 |
| BooleanQuery | 多条件查询 |
| PhraseQuery | 短语查询 |
| FuzzyQuery | 模糊查询 |
| Queryparser | 万能查询(上面的都可以用这个来查询到 |