键值对 RDD 是 Spark 中许多操作所需要的常见数据类型。键值对 RDD 通常用来进行聚合计算。我们一般要先通过一些初始 ETL(抽取、转化、装载)操作来将数据转化为键值对形式。键值对 RDD 提供了一些新的操作接口(比如统计每个产品的评论,将数据中键相同的分为一组,将两个不同的 RDD 进行分组合并等)。我们也会讨论用来让用户控制键值对 RDD 在各节点上分布情况的高级特性:分区。有时,使用可控的分区方式把常被一起访问的数据放到同一个节点上,可以大大减少应用的通信开销。这会带来明显的性能提升。分布式数据集选择正确的分区方式和本地数据集选择合适的数据结构很相似——在这两种情况下,数据的分布都会极其明显地影响程序的性能表现。
一、动机
Spark 为包含键值对类型的 RDD 提供了一些专有的操作。这些 RDD 被称为 pair RDD。PairRDD 是很多程序的构成要素,因为它们提供了并行操作各个键或跨节点重新进行数据分组的操作接口。例如,pair RDD 提供 reduceByKey() 方法,可以分别归约每个键对应的数据,还有 join() 方法,可以把两个 RDD 中键相同的元素组合到一起,合并为一个 RDD。我们通常从一个 RDD 中提取某些字段(例如代表事件时间、用户 ID 或者其他标识符的字段),并使用这些字段作为 pair RDD 操作中的键。
二、创建PairRDD
在 Spark 中有很多种创建 pair RDD 的方式。后面会学到,很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的 pair RDD。此外,当需要把一个普通的 RDD 转为 pair RDD 时,可以调用 map() 函数来实现,传递的函数需要返回键值对。下面会展示如何将由文本行组成的 RDD 转换为以每行的第一个单词为键的 pair RDD。
// Scala 中使用第一个单词作为键创建出一个pairRDD
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
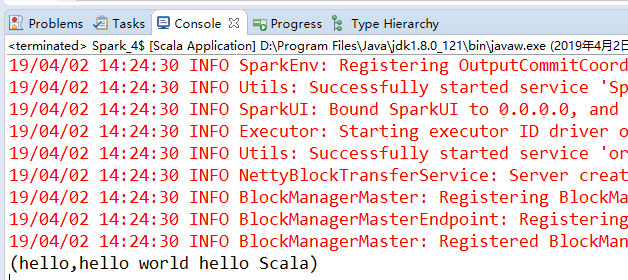
val lines = sc.parallelize(List("hello world hello Scala"))
val pairs = lines.map(x=>(x.split(" ")(0),x))
pairs.collect().foreach(println)
三、PairRDD的转化操作
Pair RDD 可以使用所有标准 RDD 上的可用的转化操作。由于 pair RDD 中包含二元组,所以需要传递的函数应当操作二元组而不是独立的元素。
Pair RDD的转化操作(以键值对集合 {(1, 2), (3, 4), (3, 6)} 为例)

针对两个pair RDD的转化操作(rdd = {(1, 2), (3, 4), (3, 6)} other = {(3, 9)} )


1、聚合操作
当数据集以键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。之前讲解过基础 RDD 上的 fold() 、 combine() 、 reduce() 等行动操作,pair RDD 上则有相应的针对键的转化操作。Spark 有一组类似的操作,可以组合具有相同键的值。这些操作返回 RDD,因此它们是转化操作而不是行动操作。
reduceByKey() 与 reduce() 相当类似;它们都接收一个函数,并使用该函数对值进行合并。reduceByKey() 会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。因为数据集中可能有大量的键,所以 reduceByKey() 没有被实现为向用户程序返回一个值的行动操作。实际上,它会返回一个由各键和对应键归约出来的结果值组成的新的 RDD。
foldByKey() 则与 fold() 相当类似;它们都使用一个与 RDD 和合并函数中的数据类型相同的零值作为初始值。与 fold() 一样, foldByKey() 操作所使用的合并函数对零值与另一个元素进行合并,结果仍为该元素。
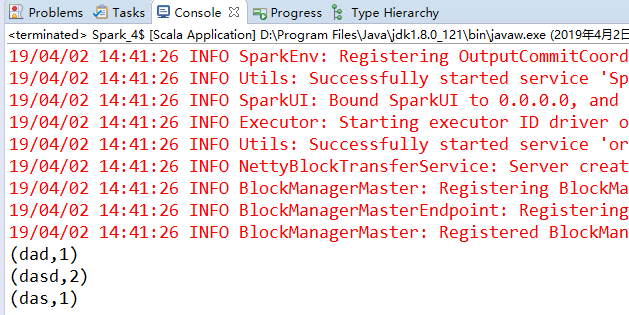
我们也可以使用表中的方法来解决经典的分布式单词计数问题。可以使用前面学过的 flatMap() 来生成以单词为键、以数字 1 为值的 pair RDD,然后使用 reduceByKey() 对所有的单词进行计数。
// 用Scala实现单词计数
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val input = sc.textFile("words.txt")
val words = input.flatMap(x=>x.split(" "))
val result = words.map(x=>(x,1)).reduceByKey((x,y)=>x+y)
result.collect().foreach(println)
// input.flatMap(x=>x.split(" ")).countByValue() 对第一个 RDD 使用 countByValue() 函数,以更快地实现单词计数
combineByKey() 是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和 aggregate() 一样, combineByKey() 可以让用户返回与输入数据的类型不同的返回值。
要理解 combineByKey() ,要先理解它在处理数据时是如何处理每个元素的。由于combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。
如果这是一个新的元素, combineByKey() 会使用一个叫作 createCombiner() 的函数来创建那个键对应的累加器的初始值。需要注意的是,这一过程会在每个分区中第一次出现各个键时发生,而不是在整个 RDD 中第一次出现一个键时发生。
如果这是一个在处理当前分区之前已经遇到的键,它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
combineByKey() 有多个参数分别对应聚合操作的各个阶段,因而非常适合用来解释聚合操作各个阶段的功能划分。为了更好地演示 combineByKey() 是如何工作的,下面来看一个统计男女个数的例子。
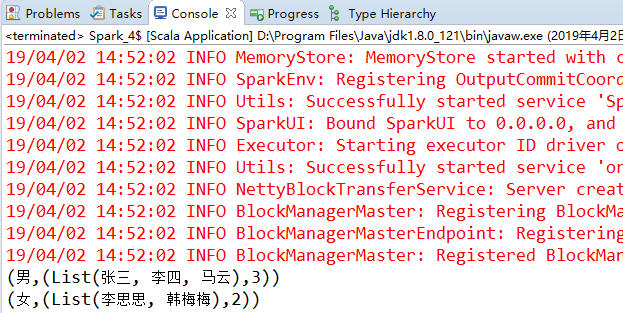
// 在Scala中使用combineByKey()求男女个数
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val people = List(("男", "李四"), ("男", "张三"), ("女", "韩梅梅"), ("女", "李思思"), ("男", "马云"))
val rdd = sc.parallelize(people,2)
val result = rdd.combineByKey(
(x: String) => (List(x), 1), //createCombiner
(peo: (List[String], Int), x : String) => (x :: peo._1, peo._2 + 1), //mergeValue
(sex1: (List[String], Int), sex2: (List[String], Int)) => (sex1._1 ::: sex2._1, sex1._2 + sex2._2)) //mergeCombiners
result.foreach(println)
到目前为止,我们已经讨论了所有的转化操作的分发方式,但是还没有探讨 Spark 是怎样确定如何分割工作的。每个 RDD 都有固定数目的分区,分区数决定了在 RDD 上执行操作时的并行度。在执行聚合或分组操作时,可以要求 Spark 使用给定的分区数。Spark 始终尝试根据集群的大小推断出一个有意义的默认值,但是有时候你可能要对并行度进行调优来获取更好的性能表现。本章讨论的大多数操作符都能接收第二个参数,这个参数用来指定分组结果或聚合结果的RDD 的分区数。
// 在Scala中自定义reduceByKey()的并行度
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val data = Seq(("a",3),("b",4),("a",1))
sc.parallelize(data).reduceByKey((x,y)=>x+y) // 默认并行度
sc.parallelize(data).reduceByKey((x,y)=>x+y,10) // 自定义并行度
有时,我们希望在除分组操作和聚合操作之外的操作中也能改变 RDD 的分区。对于这样的情况,Spark 提供了 repartition() 函数。它会把数据通过网络进行混洗,并创建出新的分区集合。切记,对数据进行重新分区是代价相对比较大的操作。Spark 中也有一个优化版的 repartition() ,叫作 coalesce()(合并) 。你可以使用 Scala 中的 rdd.partitions.size() 查看 RDD 的分区数,并确保调用 coalesce() 时将 RDD 合并到比现在的分区数更少的分区中。
2、数据分组
对于有键的数据,一个常见的用例是将数据根据键进行分组——比如查看一个顾客的所有订单。如果数据已经以预期的方式提取了键, groupByKey() 就会使用 RDD 中的键来对数据进行分组。对于一个由类型 K 的键和类型 V 的值组成的 RDD,所得到的结果 RDD 类型会是[K, Iterable[V]] 。groupBy() 可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。它可以接收一个函数,对源 RDD 中的每个元素使用该函数,将返回结果作为键再进行分组。
除了对单个 RDD 的数据进行分组,还可以使用一个叫作 cogroup() 的函数对多个共享同一个键的 RDD 进行分组。对两个键的类型均为 K 而值的类型分别为 V 和 W 的 RDD 进行cogroup() 时,得到的结果 RDD 类型为 [(K, (Iterable[V], Iterable[W]))] 。如果其中的一个 RDD 对于另一个 RDD 中存在的某个键没有对应的记录,那么对应的迭代器则为空。cogroup() 提供了为多个 RDD 进行数据分组的方法。cogroup() 是下一节中要讲的连接操作的构成要素。cogroup() 不仅可以用于实现连接操作,还可以用来求键的交集。除此之外,cogroup() 还能同时应用于三个及以上的 RDD。
3、连接
将有键的数据与另一组有键的数据一起使用是对键值对数据执行的最有用的操作之一。连接数据可能是 pair RDD 最常用的操作之一。连接方式多种多样:右外连接、左外连接以及内连接等。
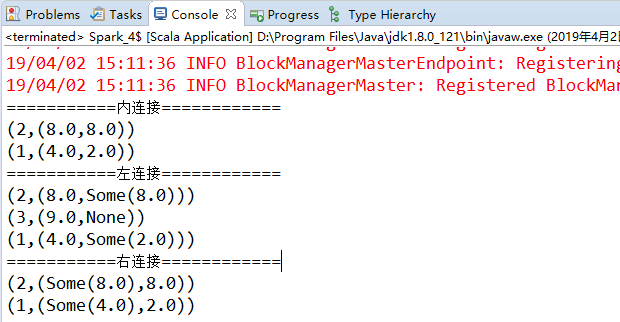
// Scala 连接操作
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val a =sc.parallelize(Array(("1",4.0),("2",8.0),("3",9.0)))
val b =sc.parallelize(Array(("1",2.0),("2",8.0)))
println("===========内连接============") // 内连接 返回结果是前面一个集合和后面一个集合中键相同的
val c=a.join(b)
c.foreach(println)
println("===========左连接============") // 左连接 返回结果以第一个RDD为主,关联不上的记录为空。
val d=a.leftOuterJoin(b)
d.foreach(println)
println("===========右连接============") // 右连接 返回结果以第二个RDD为主,关联不上的记录为空。
val e=a.rightOuterJoin(b)
e.foreach(println)
4、数据排序
很多时候,让数据排好序是很有用的,尤其是在生成下游输出时。如果键有已定义的顺序,就可以对这种键值对 RDD 进行排序。当把数据排好序后,后续对数据进行 collect()或 save() 等操作都会得到有序的数据。我们经常要将 RDD 倒序排列,因此 sortByKey() 函数接收一个叫作 ascending(上升) 的参数,表示我们是否想要让结果按升序排序(默认值为 true )。有时我们也可能想按完全不同的排序依据进行排序。要支持这种情况,我们可以提供自定义的比较函数。
// scala 排序
val conf = new SparkConf().setAppName("SortSecond").setMaster("local[1]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
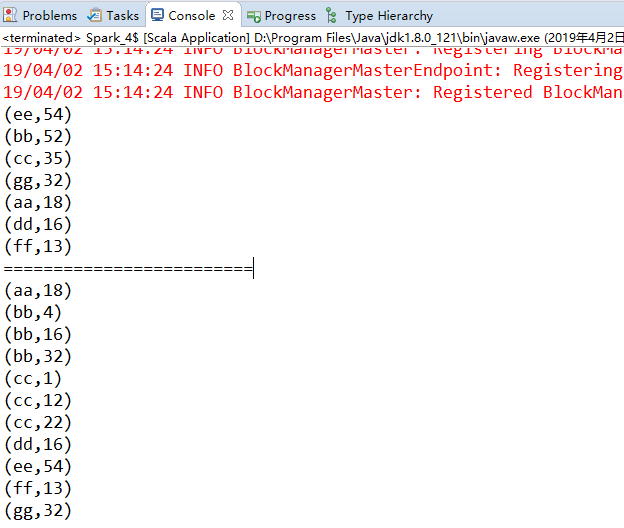
val datas = sc.parallelize(Array(("cc",12),("bb",32),("cc",22),("aa",18),("bb",16),("dd",16),("ee",54),("cc",1),("ff",13),("gg",32),("bb",4)))
// 统计key出现的次数
val counts = datas.reduceByKey(_+_)
// val sorts = counts.sortByKey()
// 按照value进行降序排序
val sorts = counts.sortBy(_._2,false)
sorts.collect().foreach(println)
// 先按照第一个元素升序排序,如果第一个元素相同,再进行第二个元素进行升序排序 自定义排序
println("=========================")
val sorts2 = datas.sortBy(e => (e._1,e._2))
sorts2.collect().foreach(println)
四、PairRDD的行动操作
和转化操作一样,所有基础 RDD 支持的传统行动操作也都在 pair RDD 上可用。Pair RDD提供了一些额外的行动操作,可以让我们充分利用数据的键值对特性。
Pair RDD的行动操作(以键值对集合 {(1, 2), (3, 4), (3, 6)} 为例)

五、数据分区
最后一个 Spark 特性是对数据集在节点间的分区进行控制。在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能。和单节点的程序需要为记录集合选择合适的数据结构一样,Spark 程序可以通过控制RDD 分区方式来减少通信开销。分区并不是对所有应用都有好处的——比如,如果给定RDD 只需要被扫描一次,我们完全没有必要对其预先进行分区处理。只有当数据集多次在诸如连接这种基于键的操作中使用时,分区才会有帮助。
Spark 中所有的键值对 RDD 都可以进行分区。系统会根据一个针对键的函数对元素进行分组。尽管 Spark 没有给出显示控制每个键具体落在哪一个工作节点上的方法(部分原因是Spark 即使在某些节点失败时依然可以工作),但 Spark 可以确保同一组的键出现在同一个节点上。比如,你可能使用哈希分区将一个 RDD 分成了 100 个分区,此时键的哈希值对100 取模的结果相同的记录会被放在一个节点上。你也可以使用范围分区法,将键在同一个范围区间内的记录都放在同一个节点上。
// 获取RDD的分区方式
val conf = new SparkConf().setAppName("SortSecond").setMaster("local[1]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val pairs = sc.parallelize(List((1,1),(2,2),(3,3)))
println(pairs)
println(pairs.partitioner)
val partitioned = pairs.partitionBy(new HashPartitioner(2)).persist() // 转为哈希分区 并持久化
println(partitioned)
println(partitioned.partitioner)

在这段简短的代码中,我们创建出了一个由 (Int, Int) 对组成的 RDD,初始时没有分区方式信息。然后通过对第一个 RDD 进行哈希分区,创建出了第二个 RDD。如果确实要在后续操作中使用 partitioned ,那就应当在定义partitioned 时,在第三行输入的最后加上 persist() 。如果不调用 persist() 的话,后续的 RDD 操作会对partitioned 的整个谱系重新求值,这会导致对 pairs 一遍又一遍地进行哈希分区操作。
注意, partitionBy() 是一个转化操作,因此它的返回值总是一个新的 RDD,但它不会改变原来的 RDD。RDD 一旦创建就无法修改。因此应该对 partitionBy() 的结果进行持久化,不进行持久化会导致整个 RDD 谱系图重新求值。那样的话, partitionBy() 带来的好处就会被抵消,导致重复对数据进行分区以及跨节点的混洗,和没有指定分区方式时发生的情况十分相似。此外,传给 partitionBy() 的100 表示分区数目,它会控制之后对这个 RDD 进行进一步操作(比如连接操作)时有多少任务会并行执行。总的来说,这个值至少应该和集群中的总核心数一样。
1、影响分区方式的操作
Spark 内部知道各操作会如何影响分区方式,并将会对数据进行分区的操作的结果 RDD 自动设置为对应的分区器。例如,如果你调用 join() 来连接两个 RDD;由于键相同的元素会被哈希到同一台机器上,Spark 知道输出结果也是哈希分区的,这样对连接的结果进行诸如 reduceByKey() 这样的操作时就会明显变快。
不过,转化操作的结果并不一定会按已知的分区方式分区,这时输出的 RDD 可能就会没有设置分区器。例如,当你对一个哈希分区的键值对 RDD 调用 map() 时,由于传给 map()的函数理论上可以改变元素的键,因此结果就不会有固定的分区方式。Spark 不会分析你的函数来判断键是否会被保留下来。不过,Spark 提供了另外两个操作 mapValues() 和flatMapValues() 作为替代方法,它们可以保证每个二元组的键保持不变。
这里列出了所有会为生成的结果 RDD 设好分区方式的操作: cogroup() 、 groupWith() 、join() 、 leftOuterJoin() 、 rightOuterJoin() 、 groupByKey() 、 reduceByKey() 、combineByKey() 、 partitionBy() 、 sort() 、 mapValues() (如果父 RDD 有分区方式的话)、flatMapValues() (如果父 RDD 有分区方式的话),以及 filter() (如果父 RDD 有分区方式的话)。其他所有的操作生成的结果都不会存在特定的分区方式。
最后,对于二元操作,输出数据的分区方式取决于父 RDD 的分区方式。默认情况下,结果会采用哈希分区,分区的数量和操作的并行度一样。不过,如果其中的一个父 RDD 已经设置过分区方式,那么结果就会采用那种分区方式;如果两个父 RDD 都设置过分区方式,结果 RDD 会采用第一个父 RDD 的分区方式。
2、自定义分区方式
虽然 Spark 提供的 HashPartitioner 与 RangePartitioner 已经能够满足大多数用例,但Spark 还是允许你通过提供一个自定义的 Partitioner 对象来控制 RDD 的分区方式。这可以让你利用领域知识进一步减少通信开销。
举个例子,当我们使用简单的哈希函数进行分区时,拥有相似的 URL 的页面(比如 http://www.cnn.com/WORLD 和 http://www.cnn.com/US)可能会被分到完全不同的节点上。然而,我们知道在同一个域名下的网页更有可能相互链接。因此把这些页面分组到同一个分区中会更好。可以使用自定义的分区器来实现仅根据域名而不是整个 URL 来分区。
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner 类并实现下面三个方法。
• numPartitions: Int :返回创建出来的分区数。
• getPartition(key: Any): Int :返回给定键的分区编号(0 到 numPartitions-1 )。
• equals() :Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个RDD 的分区方式是否相同。
有一个问题需要注意,当你的算法依赖于 Java 的 hashCode() 方法时,这个方法有可能会返回负数。你需要十分谨慎,确保 getPartition() 永远返回一个非负数。
下面展示了如何编写一个前面构思的基于域名的分区器,这个分区器只对 URL 中的域名部分求哈希。
// Scala 自定义分区方式
val conf = new SparkConf().setAppName("SortSecond").setMaster("local[1]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
class DomainNamePartitioner(numParts:Int) extends Partitioner{
override def numPartitions:Int = numParts
override def getPartition(key:Any):Int={
val domain = new java.net.URL(key.toString()).getHost()
val code = (domain.hashCode()%numPartitions)
if(code<0){
code+numPartitions // 使其非负
}else {
code
}
}
// 用来让Spark区分分区函数对象的Java equals方法
override def equals(other:Any):Boolean = other match {
case dnp:DomainNamePartitioner => dnp.numPartitions==numPartitions
case _ => false
}
}
使用自定义的 Partitioner 是很容易的:只要把它传给 partitionBy() 方法即可。Spark 中有许多依赖于数据混洗的方法,比如 join() 和 groupByKey() ,它们也可以接收一个可选的Partitioner 对象来控制输出数据的分区方式。
这篇博文主要来自《Spark快速大数据分析》这本书里面的第四章,内容有删减,还有本书的一些代码的实验结果。