一、搭建环境的前提条件
环境:ubuntu-16.04
hadoop-2.6.0
jdk1.8.0_161。
spark-2.4.0-bin-hadoop2.6。这里的环境不一定需要和我一样,基本版本差不多都ok的,但注意这里spark要和hadoop版本相对应。所需安装包和压缩包自行下载即可。
因为这里是配置spark的教程,首先必须要配置Hadoop,配置Hadoop的教程在Hadoop2.0伪分布式平台环境搭建。配置Java以及安装VMware Tools就自行百度解决哈,这里就不写了(因为教程有点长,可能有些地方有些错误,欢迎留言评论,我会在第一时间修改的)。
二、搭建的详细步骤
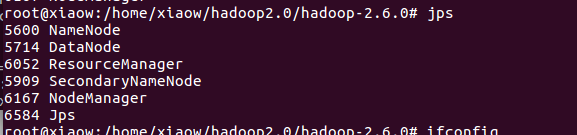
1、首先确保Hadoop伪分布式环境正在运行
2、首先对spark安装包解压缩
tar -zxvf spark-2.4.0-bin-hadoop2.6
3、进入spark/conf修改配置文件
cd spark-2.4.0-bin-hadoop2.6/ cd conf/ cp spark-env.sh.template spark-env.sh
然后在spark-env.sh文件最后添加内容
vim spark-env.sh
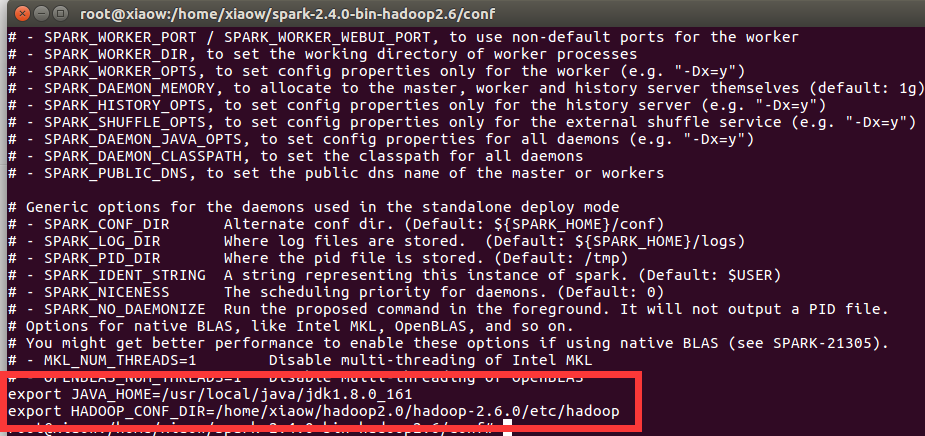
4、配置环境变量
vim ~/.bashrc
在文件最后加入spark的路径

保存使其立即生效。
source ~/.bashrc
5、启动spark
cd .. sbin/start-all.sh

jps查看进程
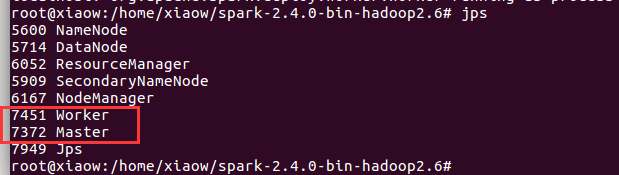
出现上面这些节点说明搭建成功。
6、webUI查看
http://localhost:8080/

7、若搭建成功的命令行界面,注意路径

退出命令为 :quit 。