本文从如何建立mysql索引以及介绍mysql的索引类型,再讲mysql索引的利与弊,以及建立索引时需要注意的地方
首先:先假设有一张表,表的数据有10W条数据,其中有一条数据是nickname='css',如果要拿这条数据的话需要些的sql是 SELECT * FROM award WHERE nickname = 'css'
一般情况下,在没有建立索引的时候,mysql需要扫描全表及扫描10W条数据找这条数据,如果我在nickname上建立索引,那么mysql只需要扫描一行数据及为我们找到这条nickname='css'的数据,是不是感觉性能提升了好多咧....
mysql的索引分为单列索引(主键索引,唯索引,普通索引)和组合索引.
单列索引:一个索引只包含一个列,一个表可以有多个单列索引.
组合索引:一个组合索引包含两个或两个以上的列,
本文使用的案例的表
CREATE TABLE `award` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '用户id', `aty_id` varchar(100) NOT NULL DEFAULT '' COMMENT '活动场景id', `nickname` varchar(12) NOT NULL DEFAULT '' COMMENT '用户昵称', `is_awarded` tinyint(1) NOT NULL DEFAULT 0 COMMENT '用户是否领奖', `award_time` int(11) NOT NULL DEFAULT 0 COMMENT '领奖时间', `account` varchar(12) NOT NULL DEFAULT '' COMMENT '帐号', `password` char(32) NOT NULL DEFAULT '' COMMENT '密码', `message` varchar(255) NOT NULL DEFAULT '' COMMENT '获奖信息', `created_time` int(11) NOT NULL DEFAULT 0 COMMENT '创建时间', `updated_time` int(11) NOT NULL DEFAULT 0 COMMENT '更新时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='获奖信息表';
(一)索引的创建
1.单列索引
1-1) 普通索引,这个是最基本的索引,
其sql格式是 CREATE INDEX IndexName ON `TableName`(`字段名`(length)) 或者 ALTER TABLE TableName ADD INDEX IndexName(`字段名`(length))
第一种方式 :
CREATE INDEX account_Index ON `award`(`account`);
第二种方式:
ALTER TABLE award ADD INDEX account_Index(`account`)
如果是CHAR,VARCHAR,类型,length可以小于字段的实际长度,如果是BLOB和TEXT类型就必须指定长度,
1-2) 唯一索引,与普通索引类似,但是不同的是唯一索引要求所有的类的值是唯一的,这一点和主键索引一样.但是他允许有空值,
其sql格式是 CREATE UNIQUE INDEX IndexName ON `TableName`(`字段名`(length)); 或者 ALTER TABLE TableName ADD UNIQUE (column_list)
CREATE UNIQUE INDEX account_UNIQUE_Index ON `award`(`account`);
1-3) 主键索引,不允许有空值,(在B+TREE中的InnoDB引擎中,主键索引起到了至关重要的地位)
主键索引建立的规则是 int优于varchar,一般在建表的时候创建,最好是与表的其他字段不相关的列或者是业务不相关的列.一般会设为 int 而且是 AUTO_INCREMENT自增类型的
2.组合索引
一个表中含有多个单列索引不代表是组合索引,通俗一点讲 组合索引是:包含多个字段但是只有索引名称
其sql格式是 CREATE INDEX IndexName On `TableName`(`字段名`(length),`字段名`(length),...);
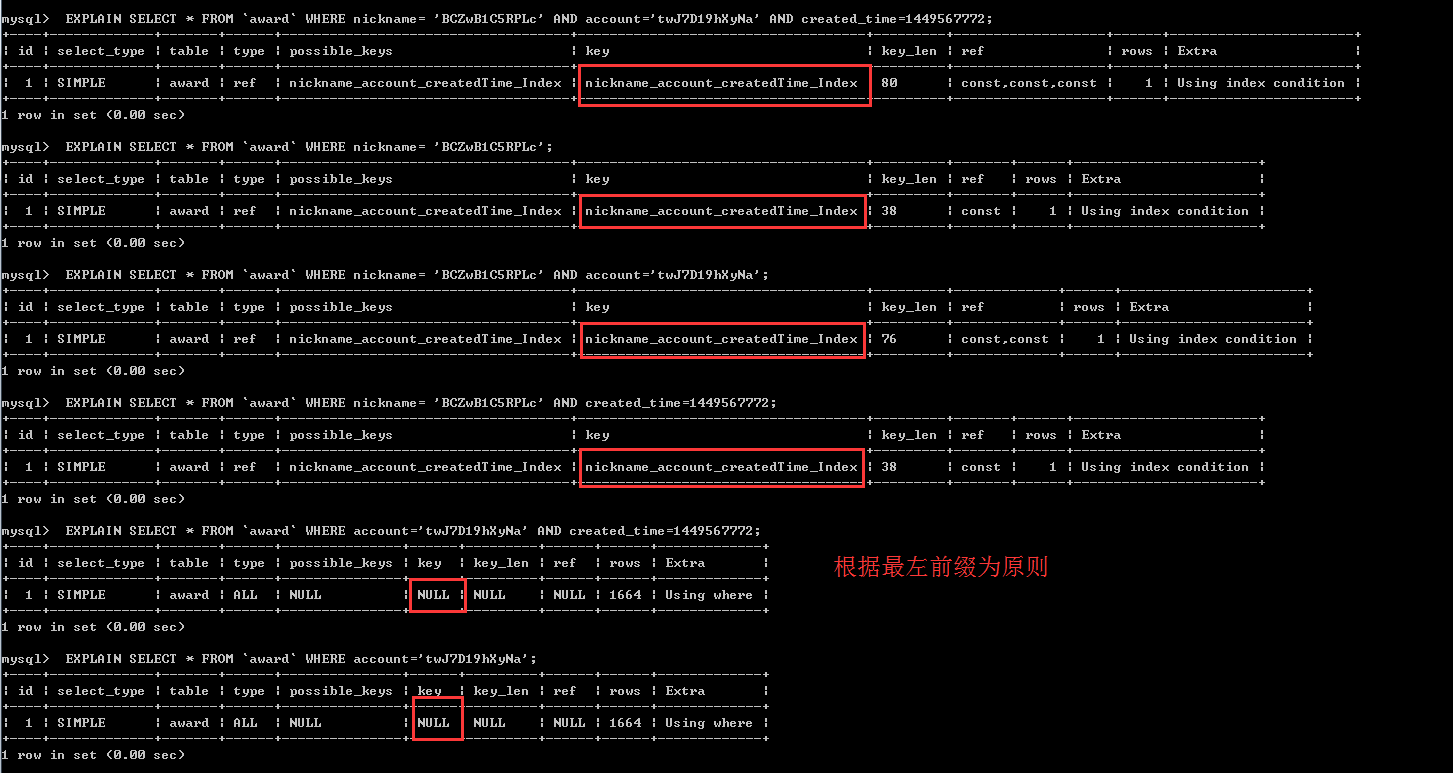
CREATE INDEX nickname_account_createdTime_Index ON `award`(`nickname`, `account`, `created_time`);


如果你建立了 组合索引(nickname_account_createdTime_Index) 那么他实际包含的是3个索引 (nickname) (nickname,account)(nickname,account,created_time)
在使用查询的时候遵循mysql组合索引的"最左前缀",下面我们来分析一下 什么是最左前缀:及索引where时的条件要按照建立索引的时候字段的排序方式
1、不按索引最左列开始查询(多列索引) 例如index(‘c1’, ‘c2’, ‘c3’) where ‘c2’ = ‘aaa’ 不使用索引,where `c2` = `aaa` and `c3`=`sss` 不能使用索引
2、查询中某个列有范围查询,则其右边的所有列都无法使用查询(多列查询)
Where c1= ‘xxx’ and c2 like = ‘aa%’ and c3=’sss’ 改查询只会使用索引中的前两列,因为like是范围查询
3、不能跳过某个字段来进行查询,这样利用不到索引,比如我的sql 是
explain select * from `award` where nickname > 'rSUQFzpkDz3R' and account = 'DYxJoqZq2rd7' and created_time = 1449567822; 那么这时候他使用不到其组合索引.
因为我的索引是 (nickname, account, created_time),如果第一个字段出现 范围符号的查找,那么将不会用到索引,如果我是第二个或者第三个字段使用范围符号的查找,那么他会利用索引,利用的索引是(nickname),
因为上面说了建立组合索引(nickname, account, created_time), 会出现三个索引
(3)全文索引
文本字段上(text)如果建立的是普通索引,那么只有对文本的字段内容前面的字符进行索引,其字符大小根据索引建立索引时申明的大小来规定.
如果文本中出现多个一样的字符,而且需要查找的话,那么其条件只能是 where column lick '%xxxx%' 这样做会让索引失效
.这个时候全文索引就祈祷了作用了
ALTER TABLE tablename ADD FULLTEXT(column1, column2)
有了全文索引,就可以用SELECT查询命令去检索那些包含着一个或多个给定单词的数据记录了。
ELECT * FROM tablename
WHERE MATCH(column1, column2) AGAINST(‘xxx′, ‘sss′, ‘ddd′)
这条命令将把column1和column2字段里有xxx、sss和ddd的数据记录全部查询出来。
(二)索引的删除
删除索引的mysql格式 :DORP INDEX IndexName ON `TableName`
(三)使用索引的优点
1.可以通过建立唯一索引或者主键索引,保证数据库表中每一行数据的唯一性.
2.建立索引可以大大提高检索的数据,以及减少表的检索行数
3.在表连接的连接条件 可以加速表与表直接的相连
4.在分组和排序字句进行数据检索,可以减少查询时间中 分组 和 排序时所消耗的时间(数据库的记录会重新排序)
5.建立索引,在查询中使用索引 可以提高性能
(四)使用索引的缺点
1.在创建索引和维护索引 会耗费时间,随着数据量的增加而增加
2.索引文件会占用物理空间,除了数据表需要占用物理空间之外,每一个索引还会占用一定的物理空间
3.当对表的数据进行 INSERT,UPDATE,DELETE 的时候,索引也要动态的维护,这样就会降低数据的维护速度,(建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快)。
(五)使用索引需要注意的地方
在建立索引的时候应该考虑索引应该建立在数据库表中的某些列上面 哪一些索引需要建立,哪一些所以是多余的.
一般来说,
1.在经常需要搜索的列上,可以加快索引的速度
2.主键列上可以确保列的唯一性
3.在表与表的而连接条件上加上索引,可以加快连接查询的速度
4.在经常需要排序(order by),分组(group by)和的distinct 列上加索引 可以加快排序查询的时间, (单独order by 用不了索引,索引考虑加where 或加limit)
5.在一些where 之后的 < <= > >= BETWEEN IN 以及某个情况下的like 建立字段的索引(B-TREE)
6.like语句的 如果你对nickname字段建立了一个索引.当查询的时候的语句是 nickname lick '%ABC%' 那么这个索引讲不会起到作用.而nickname lick 'ABC%' 那么将可以用到索引
7.索引不会包含NULL列,如果列中包含NULL值都将不会被包含在索引中,复合索引中如果有一列含有NULL值那么这个组合索引都将失效,一般需要给默认值0或者 ' '字符串
8.使用短索引,如果你的一个字段是Char(32)或者int(32),在创建索引的时候指定前缀长度 比如前10个字符 (前提是多数值是唯一的..)那么短索引可以提高查询速度,并且可以减少磁盘的空间,也可以减少I/0操作.
9.不要在列上进行运算,这样会使得mysql索引失效,也会进行全表扫描
10.选择越小的数据类型越好,因为通常越小的数据类型通常在磁盘,内存,cpu,缓存中 占用的空间很少,处理起来更快
(六)什么情况下不创建索引
1.查询中很少使用到的列 不应该创建索引,如果建立了索引然而还会降低mysql的性能和增大了空间需求.
2.很少数据的列也不应该建立索引,比如 一个性别字段 0或者1,在查询中,结果集的数据占了表中数据行的比例比较大,mysql需要扫描的行数很多,增加索引,并不能提高效率
3.定义为text和image和bit数据类型的列不应该增加索引,
4.当表的修改(UPDATE,INSERT,DELETE)操作远远大于检索(SELECT)操作时不应该创建索引,这两个操作是互斥的关系
四五六部分引用了一个高手的见解,感觉非常到位啊。。。所以就全部粘贴过来了