今天首先是继续看了一下关于GIL的问题,其实昨天验证后存在的问题本身之外,还有一个更加令人震惊的问题,为啥listen和game在使用了多线程之后时间缩短了,而之后的add和cheng的用了多线程运算时间却反而增多了,下面我就慢慢叙来:
首先是我们常处理的任务分为两种类型:
1.IO密集型(存在大量的数据输入)
2.计算密集型(非常高端的底层计算,或者像昨天出现数据差异的那种)
特别说明一下,time.sleep()就是一个类似的等待数据输入过程,这就合理解释了为啥listen和game是节省时间的,大致情况如下图:
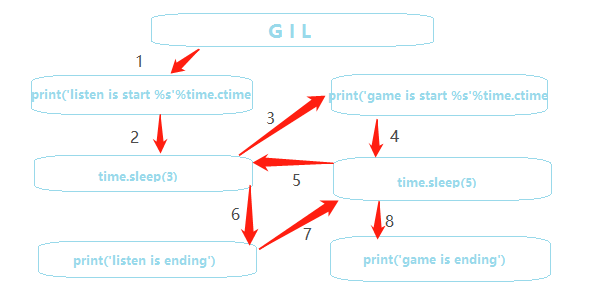
可以发现,当listen运行至等待3秒的时候,多线程就安排了game进行运行,而在game等待5秒的过程中就把listen部分的3秒内容全部执行完了,切换执行的时间是远小于等待io输入的时间,所以其实也就是线程io等待时间那个少,就节约那个的时间。
然后是add和cheng的问题,这两者基本就没有io操作的等待时间,就是一堆纯计算,但是解释器还要不停的对这两个线程进行切换,所以浪费了很多时间,导致老老实实把一个计算完再计算下一个更为节约时间。
所以Python语言是更适合进行操作io密集型的任务的,其实生活中的大多数实例就是io密集型,但是还存在一个本质的问题,就是没办法发挥我四核电脑的强大性能,这个该如何实现呢,继续看昨天的图,加了些东东。
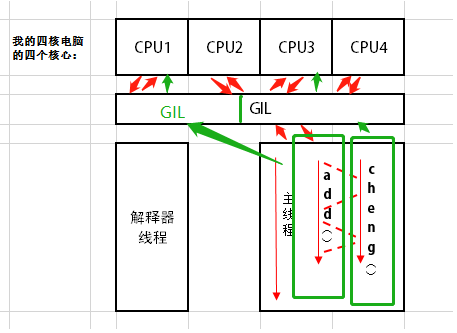
其实这里的GIL是针对每个进程设置了一个锁,那么如果我们多建立一个进程去分别执行两个方法,那不就OK了嘛,这样两个内核同时开始执行任务。
但是此方法还是推荐高手使用,每增加一次进程内存消耗还是比较大,所以谨慎使用吧,然后教程也没告诉我到底该怎么使用。
总结:多线程在处理io密集型任务的过程中,就是将cpu等待用户进行数据输入的时间,安排去执行别的线程,等你完成输入后再返回继续执行,从而提高了cpu的使用效率
然后提到了一个概念:多线程 + 协程
下面是第二部分:
上面说清楚了多线程的工作机制,下面就发生了这么一个因为多线程造成的错误:
要求,利用多线程实现一个递减的过程。
先看正确形式运行的代码:
import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 num-=1 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('final num:', num )
此时最终的输出结果num是0
然后我们修改一下addNum的形式,然赋值和运算分为两步进行,同时中间休息0.01秒
import time import threading def addNum(): global num #在每个线程中都获取这个全局变量 temp=num time.sleep(0.1) num =temp-1 #对此公共变量进行-1操作 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('final num:', num )
然后此时你会发现,num的值会随着time.sleep()的时间长短发生变化
数字贼小的时候还是有机会等于0的,但是大多数情况还是会变成一个大于0的数字
大致的运行过程
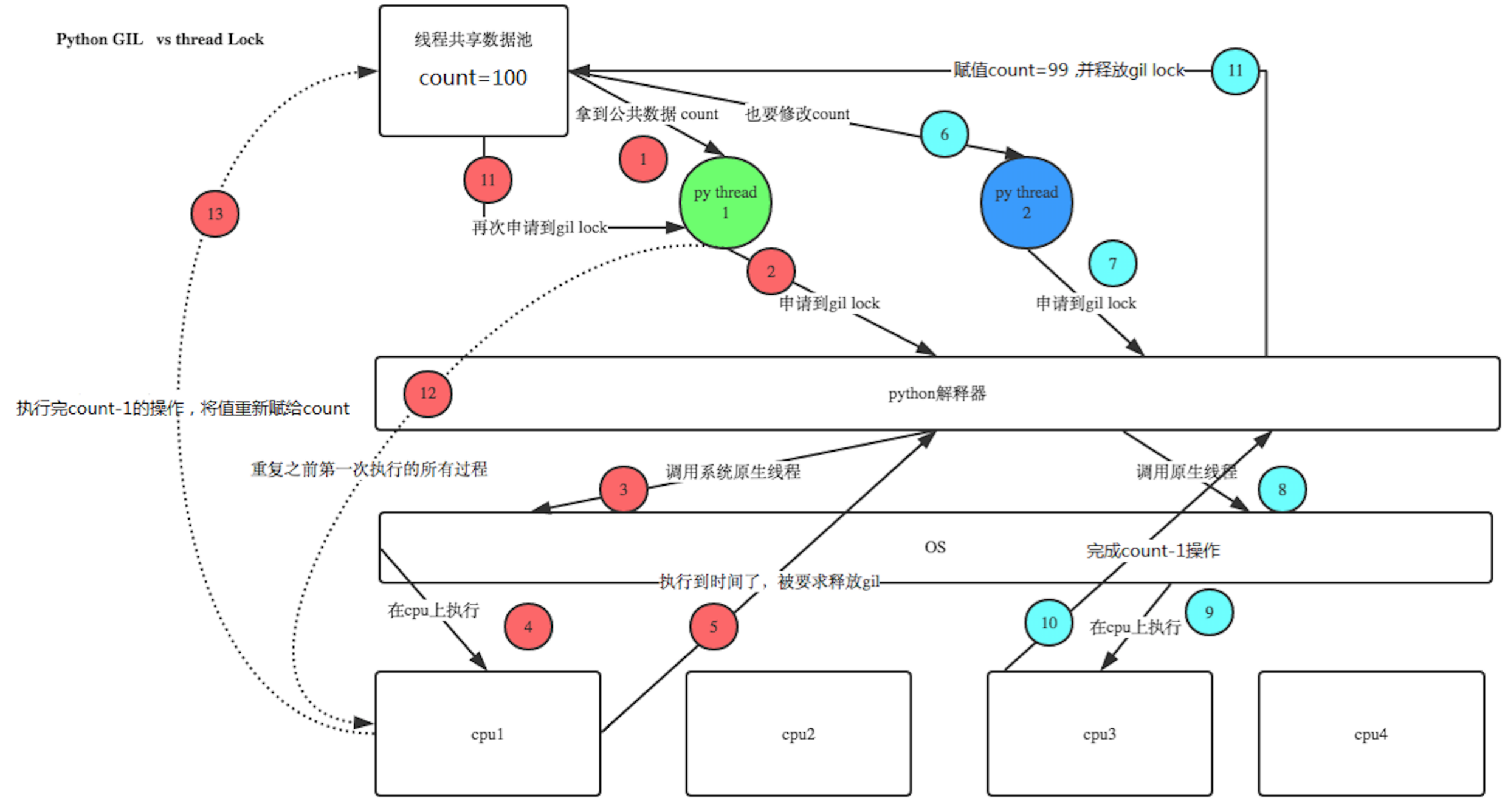
原因非常的明显,在第一次递减进入等待的时候,其他线程开始运行,导致可能存在多个temp被赋值为100,这样最终导致了运算结果的偏差,主要是我们一个线程在没有运行完之前进行了线程之间的切换,那么为了保证这样不被切换,我们引入了同步锁
同步锁:同步锁内程序不运行完,坚决不进行切换
修改之后就能完美解决上面的问题了
import time import threading lock = threading.Lock() def addNum(): global num #在每个线程中都获取这个全局变量 lock.acquire() #上锁 temp=num time.sleep(0.1) num =temp-1 #对此公共变量进行-1操作 lock.release() #解锁 num = 100 #设定一个共享变量 thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('final num:', num )
通过增加 lock.acquire() 和 lock.release() 保证了在他们中间运行的代码不会发生线程的切换,这样就能完美保证程序的逐个运行。
最近理论知识好多啊,然后上班工作好多好杂,脑瓜子很疼,抽空得复习了,还有前面放了很多的卫星,一直没有去做,感觉现在都忘的干净了,晚安啦。。。