今天内容不多,所以都进行了测试
一、bin.py文件也存在与子目录之下,如何通过bin.py文件转入main.py
文件存储的大致位置:
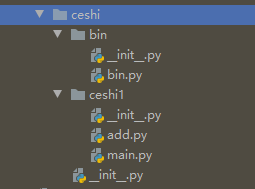
main.py文件存放内容
from ceshi1 import add def run(): print('main def start') print(add.ad(2,3)) return 'main def start'
add.py文件存放内容
def add(x,y): return x+y
bin.py文件内容和总结
# 关于昨天讲到的bin.py文件放在ceshi(package)下,与ceshi1(package)放在同一子目录下的情况进行了补充 # 大部分时候bin.py文件也会放在一个package下面,作为其中的一个文件,此时bin.py和main.py文件分别属于不同的文件夹 # 此时应该如何实践import导入,最终正常执行main.py文件 #之前的方法是 # from ceshi.ceshi1 import main #此时因为bin.py文件所在的路径已经不和ceshi1属于同一子目录,所以无法实现引入 import sys,os # print(sys) #此时显示文件的路径是C:/Users/xiaoyao28.CRHD0A/PycharmProjects/python_s1/venv/模块和包/ceshi/bin/bin.py #但是这是pycharm修改后的结果,在终端运行的过程中往往只显示bin.py文件 #此时我们知道了bin.py 的默认执行路径,我们可以跟怒sys内置的方法进行修改其默认路劲,再进行相关引入即可 # sys.path.append(r'C:/Users/xiaoyao28.CRHD0A/PycharmProjects/python_s1/venv/模块和包/ceshi') #此时已经修改默认路径为ceshi(package)所在目录,再进行from导入,查看是否可以运行 # from ceshi1 import main # main.run() #此时文件可以正常运行,但是这样得到的固定文件路径,一旦更换运行设备就没法正常运行了 #所以需要引入os模块中的一些功能 #os.path.dirname 获得文件路径的上一层路径 #但是我们在前面也提到__file__获得的只是bin.py,而前面的路径是pycharm加上的 #os.path.abspath(__file__) 获得文件的绝对路径,即前面那一堆加上了 # bas = os.path.abspath(__file__) #获取当前执行的bin.py文件所在绝对路径 # bas_up = os.path.dirname(os.path.dirname(bas)) #这样通过两次返回上一层,就获得了正确的默认测试路径 # #即为C:/Users/xiaoyao28.CRHD0A/PycharmProjects/python_s1/venv/模块和包/ceshi # sys.path.append(bas_up) #以bas_up变量为参数,临时修改默认路径 # from ceshi1 import main # main.run() #可正常运行,就算更换设备也不影响正常使用
二、os模块
import os #os模块内容 #os.getcwd 获取当前工作目录,即为上一级的绝对路径 # print(os.getcwd()) #输出结果:C:Usersxiaoyao28.CRHD0APycharmProjectspython_s1venvday22 #os.chdir('path') 改变当前工作目录,输入path为要切换的文件名,如果输入'..'表示返回上一级 # os.chdir('..') # print(os.getcwd()) #os.makedirs('dirname/dirname') 生成多层递归目录 # os.makedirs('dirname/dirname1') #os.removedirs('path') 删除该文件目录,若该文件目录为空,则删除,同时递归至上一层文件目录,若为空则删除,以此类推 # os.removedirs('dirname/dirname1') #os.mkdir('dirmame') 生成单级目录 # os.mkdir('dirname') #os.rmdir('dirname') 删除单级目录,若该单级目录不为空则无法删除,系统会报错 # os.rmdir('dirname') #os.listdir('dirname') 列出制定目录下的所有文件和子目录,包含隐藏文件,并以列表方式打印 # print(os.listdir()) #输出:['os_test.py', '__init__.py'] #os.remove('path') 制定删除一个文件 #os.rename('oldname','newname') 重新命名文件或目录 #os.stat('dirname') 获取文件的相关状态,访问时间、修改时间、大小等 # os.chdir('..') # print(os.stat('ceshi')) #输出os.stat_result(st_mode=33206, st_ino=3377699720828849, st_dev=4176561250, st_nlink=1, # st_uid=0, st_gid=0, st_size=1077, st_atime=1583500656, st_mtime=1583506954, st_ctime=1583500638) # atime上次访问时间 mtime最新修改时间 ctime文件创建时间 #os.sep('path/filename') 获取文件/目录的信息 # print(os.sep) #不同操作系统输出不同斜线 # os.linesep 输出当前平台使用的行终止符 # os.pathsep 输出当前平台文件路径字符串的分隔符 win是';' linux是':' # os.name 输出当前运行的平台,用于跨平台运行的选择 # os.system('dir') 运行shell命令,直接显示(这个还不是很清晰) # os.path.split('path') 将path分割成目录和文件名二元组返回 # os.path.dirname('path') 返回path的目录名 # os.path.basename('path') 返回path的文件名 # print(os.path.split(__file__)) #输出结果:('C:/Users/xiaoyao28.CRHD0A/PycharmProjects/python_s1/venv/day22', 'os_test.py') # print(os.path.dirname(__file__)) #输出结果就是split输出元组的前半部分,C:/Users/xiaoyao28.CRHD0A/PycharmProjects/python_s1/venv/day22 # print(os.path.basename(__file__)) #输出结果就是split输出元组的后半部分,os_test.py # os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False # os.chdir('..') # print(os._exists('day22')) # os.path.isabs(path) 如果path是绝对路径,返回True # b = os.path.abspath(__file__) # print(os.path.isabs(b)) # os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False # print(os.path.isfile('os_test.py')) # os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False # os.chdir('..') # print(os.path.isdir('day22')) # os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 # print(os.path.abspath(__file__)) #C:Usersxiaoyao28.CRHD0APycharmProjectspython_s1venvday22os_test.py # a = 'C:ooyao28.CRHD0APycharmProjects' # b = 'python_s1venvday22os_test.py' # print(os.path.join(a,b)) #用join拼接的字符串可以适应各种操作系统 # os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 # os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 # 相当于直接获取os.stat中的部分内容 # os.environ 获取系统环境变量 # print(os.environ)
三、sys模块
import sys,time # sys模块部分内容比较少 # sys.argv 命令行参数List,第一个元素是程序本身路径 # 我们在制作或者执行文件时,中间会让程序停下来进行input()操作,而使用sys.argv则可在程序运行开始就传输相关参数 # sys.exit(n) 退出程序,正常退出时exit(0) # sys.version 获取Python解释程序的版本信息 # sys.maxint 最大的Int值 # sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 # sys.platform 返回操作系统平台名称 # sys.stdout.write() 类似于输出语句,可用于制作进度条 # for i in range(50): # sys.stdout.write('_') # time.sleep(0.2) # sys.stdout.flush() #增加此句的功能是为了让一旦有输出语句就可以立即刷新 # #以前都是等整个for循环完成后统一一块输出,这样可以做成类似进度条
四、json&pickle模块
import json,pickle #json是可以将数据转换为json类型的字符串,可用于任何语言的传输 #下面以文件写入字典为例介绍一下json #需求:信件文件test,吸入字典{'name':'alex','age':18},保证可被读取 #之前都是用的eval # dic = {'name':'alex','age':18} # # f = open('json_test','w') # dic = str(dic) # f.write(dic) # f.close() # # f_read = open('json_test','r') # a = eval(f_read.read()) # print(a['name']) #但是在实际操作过程中eval也存在有局限性,不能保存函数,以及不能被其他语言识别等 #引入json #json.dumps() 将数据转换为json类型的字符串 #json.loads() 读取json类型字符串,将其转化回来 # dic = {'name':'alex','age':18} # f = open('json_test','w') # dic = json.dumps(dic) # print(dic) #此处输出结果:{"name": "alex", "age": 18} # #在json.dumps的过程中,首先是把dic内的所有单引号变为双引号,同时在外部加入引号,保证成为标准json字符串类型 # print(type(dic),dic) #输出结果:<class 'str'> {"age": 18, "name": "alex"} # f.write(dic) #关于dumps的用法,直接书写为json.dump(dic,f) # json.dump(dic,f) #这一句等同于dic = json.dumps(dic) f.write(dic) #为了便于记录,还是不要这么偷懒 #json.load 和 json.loads的区别也是一样的 # f.close() # # f_read = open('json_test','r') # a = json.loads(f_read.read()) #json.loads使用的前提是对应的值必须是一个标准的json类型字符串 #如果我们自己书写的字符串,必须满足双引号的要求才能转换 # print(a['name']) # 关于pickle的作用,本质上和json相同,但是pickle是用于python之间的数据交换,能够转换的范围更大 # # pickle是将给的数据类型转换为字节的形式储存 # dic = {'name':'alex','age':18} # f = open('json_test','wb') # dic = pickle.dumps(dic) # print(dic) #输出结果是:b'x80x03}qx00(Xx04x00x00x00nameqx01Xx04x00x00x00alexqx02Xx03x00x00x00ageqx03Kx12u.' # print(type(dic),dic) #输出结果是:<class 'bytes'> b'x80x03}qx00(Xx03x00x00x00ageqx01Kx12Xx04x00x00x00nameqx02Xx04x00x00x00alexqx03u.' # #pickle将对应数据转换为了字节形式储存写入和读取 # f.write(dic) # f.close() # # f_read = open('json_test','rb') # a = pickle.loads(f_read.read()) # print(a['name']) #可正常得到'alex'
后面我会把自己的进度放的慢一些,因为感觉内容真的越来越多,主要还是需要更多的练习,今天的内容就是这些啦。