进程
现实生活中
在很多的场景中的事情都是同时进行的,比如开车的时候 手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的;
如下是一段视频,迈克杰克逊的一段视频:
http://v.youku.com/v_show/id_XMzE5NjEzNjA0.html?&sid=40117&from=y1.2-1.999.6
试想:如果把唱歌和跳舞这2件事分开以此完成的话,估计就没有那么好的效果了
程序中
如下程序,来模拟“唱歌跳舞” 这件事情
11 from time import sleep 12 13 def sing(): 14 for i in range(3): 15 print('正在唱歌...%d'%i) 16 sleep(1) 17 18 def dance(): 19 for i in range(3): 20 print('正在跳舞...%d'%i) 21 sleep(1) 22 23 if __name__=="__main__": 24 sing() 25 dance()
运行结果如下:
正在唱歌...0 正在唱歌...1 正在唱歌...2 正在跳舞...0 正在跳舞...1 正在跳舞...2
注意!!!
很显然刚刚的程序并没有完成唱歌和跳舞同事进行的要求
如果想要实现“唱歌跳舞”同时进行,那么就需要 一个新的方法,叫做 多任务
多任务的概念
什么叫做多任务呢?简单的说,就是操作系统可以同时运行多个任务。打个比方,你一边用浏览器上网,一边在听mp3,一边在赶word作业,这就是多任务,至少同时有3个任务正在运行。很有很多任务悄悄的在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒, 切换到任务2,任务2执行0.01秒,切换到任务3,执行0.01秒......,这样反复的执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们就感觉所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
单核CPU完成多个任务的执行的原因?
- 时间片论法
- 优先级调度
并行和并发
并发:看上去一直执行
并行:真正的一起执行
进程的创建-fork
进程VS程序
编写完毕的代码,在没有运行的时候,称之为 程序
正在运行的代码,就称为 进程
进程,除了包含代码以外,还有需要运行的环境等,所以和程序是有区别的
fork()
python的os模块封装了常见的系统调用,其中就包括fork,可以在python程序中轻松创建子进程:
11 import os 12 13 pid = os.fork() #使用os.fork创建出一个新的进程,以下的代码父子进程都会执行 14 15 if pid == 0: 16 print('哈哈0') 17 else: 18 print('哈哈1')
运行结果如下:
哈哈1
哈哈0
还有一个例子:
11 import os 12 import time 13 14 ret = os.fork() 15 if ret==0: 16 while True: 17 print('------------1-------------') 18 time.sleep(1) 19 else: 20 while True: 21 print('------------2-------------') 22 time.sleep(1)
运行结果如下:
------------2-------------
------------1-------------
------------1-------------
------------2-------------
------------1-------------
------------2-------------
------------2-------------
------------1-------------
......
相当于程序在运行到了os.fork()时,产生了一个新的进程,ret用来接受两个进程返回值,旧的进程执行最下面的语句,而新的进程去执行上面的语句,因为新的进程的返回值为0。之前的进程称之为父进程,新创建出来的进程叫做子进程。
因为要分辨出父进程和子进程,所以操作系统给父进程的返回值大于0,给子进程的返回值等于0。
操作系统调度算法决定了父进程和子进程的运行顺序。
说明:
- 程序执行到os.fork(),操作系统会创建一个新的进程(子进程),然后复制父进程的所有信息到子进程中
- 然后父进程和子进程都会从fork()函数中得到一个返回值,在子进程中这个值一定是0,而父进程中是子进程的id号
在Unix/Linux操作系统中,提供了一个fork()函数,它非常特殊。
普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID号。
这样做的理由是:一个父进程可以fork出很多的子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
fork的返回值
11 import os 12 13 ret = os.fork() 14 print(ret)
运行结果:
26517 #代表着父进程
0 #代表子进程
getpid()、getppid()
getpid()获取当前进程的值,getppid()获取当前进程的父进程的值。
12 import os 13 pid = os.fork() 14 15 if pid<0: 16 print('fork调用失败.') 17 elif pid==0: 18 print('我是子进程(%s),我的父进程是(%s)'%(os.getpid(),os.getppid())) 19 else: 20 print('我是父进程(%s),我的子进程是(%s)'%(os.getppid(),os.getpid())) 21 22 print(' 父子进程都可以执行的代码<F8>')
运行结果如下:
我是父进程(2774),我的子进程是(25874) 父子进程都可以执行的代码<F8> 我是子进程(25875),我的父进程是(25874) 父子进程都可以执行的代码<F8>
第二个例子:
11 import os
12 pid = os.fork()
13 print(pid)
14
15 if pid>0:
16 print('父进程:%d'%os.getpid())
17 else:
18 print('子进程:%d-%d'%(os.getpid(),os.getppid()))
运行结果:
26685 #pid的返回值,操作系统为了管理给它的值,父类的返回值,就是子进程的ID号 父进程:26684 #26684是父进程ID号 0 子进程:26685-26684 #26685是子进程ID号,子进程的父进程是26684
多进程修改全局变量
11 import os 12 import time 13 14 num = 0 15 16 pid = os.fork() 17 18 if pid==0: 19 num+=1 20 print('哈哈1------num=%d'%num) 21 else: 22 time.sleep(2) 23 num+=1 24 print('哈哈2------num=%d'%num)
运行结果如下:
哈哈1------num=1 哈哈2------num=1
说明:
- 在多进程中,每个进程中的数据(包含全局变量)都各自拥有一份,互不影响,进程和进程之间不会数据共享
多次fork问题
如果有一个程序,有2次的fork函数调用,是否就会有3个进程呢?
11 import os 12 import time 13 14 pid = os.fork() 15 if pid==0: 16 print('哈哈1') 17 else: 18 print('哈哈2') #一共运行了2次 19 20 pid = os.fork() 21 if pid==0: 22 print('哈哈3') 23 else: 24 print('哈哈4') #一共运行了4次 25 26 time.sleep(1)
运行结果如下:
python@ubuntu:~/codes/liunx系统编程/01-进程$ python 05-多次fork调用.py 哈哈2 哈哈1 哈哈4 哈哈4 哈哈3 哈哈3
说明:
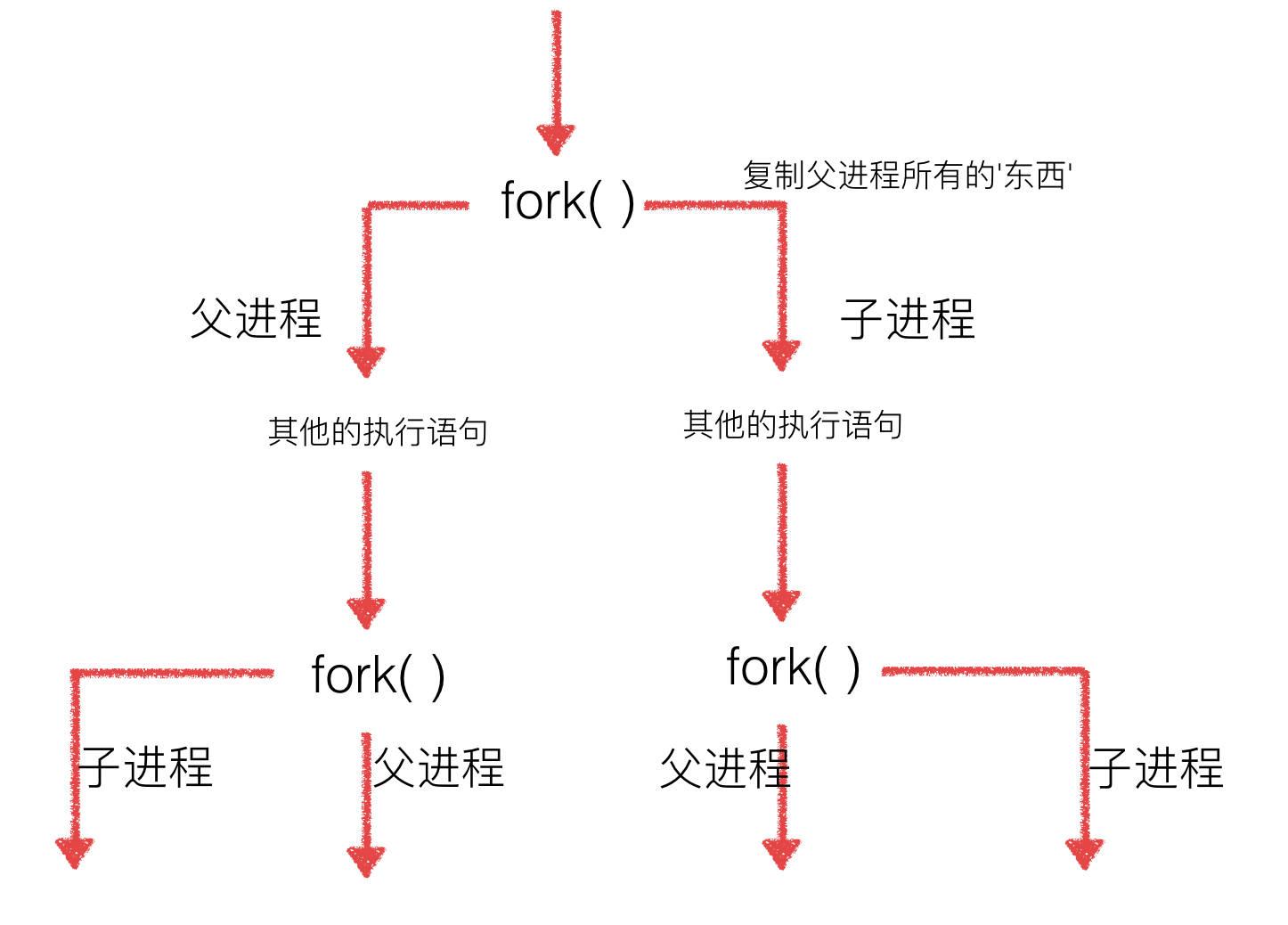
3次fork
11 import os 12 os.fork() 13 os.fork() 14 os.fork() 15 16 print('-----------1------------')
运行结果如下:
-----------1------------ -----------1------------ -----------1------------ python@ubuntu:~/codes/liunx系统编程/01-进程$ -----------1------------ -----------1------------ -----------1------------ -----------1------------ -----------1------------
一共是8个,相当于乘以两
父子进程的执行顺序
父进程、子进程执行顺序没有规律,完全取决于操作系统的调度算法
11 import os 12 import time 13 ret = os.fork() 14 15 if ret==0: 16 print('子进程') 17 time.sleep(1) 18 print('子进程over') #end="" 19 else: 20 print('父进程')
运行结果如下:
python3 04-父子进程的运行顺序.py
父进程
子进程
python@ubuntu:~/codes/liunx系统编程/01-进程$ 子进程over
因为父进程已经结束了,意味着终端已经可以开始提示了,所以当父进程一执行完,那么终端就会立马出来。
多任务的优点
增加程序的运行效率,例如爬虫
multiprocessing
如果打算编写多进程的服务程序,Unix和Linux无疑是正确的选择。由于windows没有fork调用,难道在 windows上无法用python编写多进程的程序?
由于python是跨平台的,自然也应该提供一个跨平台的多进程支持,multiprocess模块就是跨平台版本的多进程模块。
multiprocessessing模块提供了一个Process类来代表一个进程对象,下面的例子演示了启动一个子进程并等待其结束:
11 from multiprocessing import Process #因为fork不能跨平台,所以需要使用Process 12 import os 13 import time 14 15 def test(): 16 while True: 17 print("--------------test1---------") 18 time.sleep(1) 19 p = Process(target=test) #执行要执行的代码,即创建完对象后自动去test里执行代码 20 p.start() #让这个进程开始执行test里的代码 21 while True: 22 print('------------main------------') 23 time.sleep(1)
运行结果如下:
------------main------------
--------------test1---------
------------main------------
--------------test1---------
------------main------------
--------------test1---------
.......
Process创建子进程和主进程的结束:
11 from multiprocessing import Process 12 import time 13 14 def test(): 15 for i in range(5): 16 print("--------------test1---------") 17 time.sleep(1) 18 p = Process(target=test) #执行要执行的代码,即创建完对象后自动去test里执行代码 19 p.start() #让这个进程开始执行test里的代码
运行结果如下:
python@ubuntu:~/codes/liunx系统编程/01-进程$ python3 08-Process创建的子进程和主进程的结束.py --------------test1--------- --------------test1--------- --------------test1--------- --------------test1--------- --------------test1--------- python@ubuntu:~/codes/liunx系统编程/01-进程$ #5秒钟后,子进程结束,才会弹出终端
结论:
- 如果是fork创建的子进程,如果主进程一关,那么终端提示符会立马出来,如果是用Process创建的子进程,那么主进程会在结束之前等待所有的子进程先结束才over。
join子进程
11 from multiprocessing import Process 12 import time 13 import random 14 15 def test(): 16 for i in range(random.randint(1,5)): 17 print('%d'%i) 18 time.sleep(1) 19 20 p = Process(target=test) 21 p.start() 22 p.join() #等到这个对象标记的对象结束后,join才会继续往下走 join()可以添加等待的最长时间,即等待时间后,才可以弹出终端 23 24 print('-----main-----')
查看运行结果如下:
0
1
2
-----main----- #等待子进程结束后,才会运行
p.join()堵塞:理论上按照程序流程往下走,主程序到了p.join()等待某个条件的发生,如果不发生,那么主程序就会卡在这,这种现象叫做堵塞。join前面的对象,就是条件的发生,调节结束之后,才会解堵塞。
Process子类创建进程
创建新的进程还能够使用类的方式, 可以字定义一个类,继承Process类,每次实例化这个类的时候,就等于实例化了一个对象,请看下面的实例:
11 from multiprocessing import Process 12 import time 13 import os 14 15 class MyNewProcess(Process): 16 def run(self): 17 while True: 18 print('--1--') 19 time.sleep(2) 20 21 p = MyNewProcess() 22 p.start() #父类有run方法,会去自动执行run方法 23 while True: 24 print('----main-----') 25 time.sleep(1)
运行结果如下图:
----main-----
----main-----
--1--
----main-----
----main-----
--1--
----main-----
......
进程池Pool
缓冲数据用的。创建进程,用不用不管,什么时候用,就给你,相当于增加了重复使用率。
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程,但如果时上百个甚至上前个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool时,如果池还没有满,那么就会创建一个新的进程来执行该请求;但是如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会创建新的进程来执行,请看下面的实例:
11 from multiprocessing import Pool 12 import os 13 import random 14 import time 15 16 17 def worker(num): 18 for i in range(3): 19 print('pid = %d,num=%d'%(os.getpid(),num)) 20 time.sleep(1) 21 22 pool = Pool(3) #最多容纳3个进程,表示进程池中最多有3个进程一起执行 23 24 for i in range(10): 25 print('----%d----'%i) 26 #向进程池中添加任务 27 #注意:如果添加的任务数量超过了进程池中的个数的话,那么不会导致添加不进去 28 # 添加到进程中的任务,如果还没有被执行的话,那么此时 他们会等待进程池中的 29 # 进程完成一个任务后,会自动的取用刚刚哪个进程完成当前的新任务 30 pool.apply_async(worker,(i,)) #开始启动一个进程去完成这个任务 非堵塞方式
31 32 pool.close() #关闭进程池,关闭后pool不再接收新的请求 33 pool.join() #主进程 创建/添加 任务后,主进程 默认不会等待进程池中的任务执行完后结束 34 # 而是当主进程的任务做完之后立马结束,如果这个地方没有join,会导致 35 # 进程池中的任务不会执行
运行结果如下图:
----0---- ----1---- ----2---- pid = 27877,num=0 ----3---- pid = 27878,num=1 ----4---- pid = 27879,num=2 ----5---- ----6---- ----7---- ----8---- ----9---- pid = 27877,num=0 pid = 27878,num=1 pid = 27879,num=2 pid = 27878,num=1 pid = 27877,num=0 pid = 27879,num=2 pid = 27877,num=3 pid = 27878,num=4
多种方式的比较
11 ret = os.fork() 12 if ret ==0: 13 #子进程 14 else: 15 #父进程 16 17 p1 = Process(target=xxxx) 18 p1.start() #主进程同样不会结束,主、子进程都可以用 19 20 pool = Pool(3) #Pool里面的数要压力测试 21 pool.apply_async(xxxx) #主进程一般用来等待,真正的任务都在子进程中执行