1.栈的介绍
在许多算法设计中都需要一种"先进后出(First Input Last Output)"的数据结构,因而一种被称为"栈"的数据结构被抽象了出来。
栈的结构类似一个罐头:只有一个开口;先被放进去的东西沉在底下,后放进去的东西被放在顶部;想拿东西必须按照从上到下的顺序进行操作。
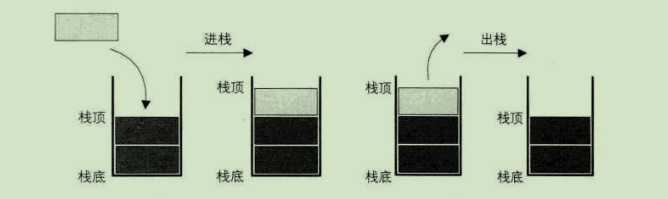 示意图来自《大话数据结构》
示意图来自《大话数据结构》
对于一个类似罐头的栈,用户能对其进行的操作很少:仅仅可以对栈顶开口处元素进行操作,因而栈的使用方式非常简单。
2.栈的ADT接口
/** * 栈ADT 接口定义 * */ public interface Stack<E>{ /** * 将一个元素 加入栈顶 * @param e 需要插入的元素 * @return 是否插入成功 * */ boolean push(E e); /** * 返回栈顶元素,并且将其从栈中移除(弹出) * @return 当前栈顶元素 * */ E pop(); /** * 返回栈顶元素,不将其从栈中移除(窥视) * @return 当前栈顶元素 * */ E peek(); /** * @return 返回当前栈中元素的个数 */ int size(); /** * 判断当前栈是否为空 * @return 如果当前栈中元素个数为0,返回true;否则,返回false */ boolean isEmpty(); /** * 清除栈中所有元素 * */ void clear(); /** * 获得迭代器 * */ Iterator<E> iterator(); }
3.栈的实现
如果我们将开口朝上的栈旋转90度,会发现栈和先前我们介绍过的线性表非常相似。栈可以被视为一个只能在某一端进行操作的,被施加了特别限制的线性表。
3.1 栈的向量实现
栈作为一种特殊的线性表,使用向量作为栈的底层实现是很自然的(向量栈)。
jdk的栈结构(Stack)是通过继承向量类(Vector)来实现的,这一栈的实现方式被java集合框架(Collection Framework)的作者Josh Bloch在其所著书籍《Effective Java》中所批评,Josh Bloch认为这是一种糟糕的实现方式,因为继承自向量的栈对使用者暴露了过多的细节。
原文部分摘录:
复合优先于继承
继承打破了封装性。
java对象中违反这条规则的:stack不是vector,所以stack不应该扩展vector。如果在合适用复合的地方用了继承,会暴露实现细节。
继承机制会把超类中所有缺陷传递到子类中,而复合则允许设计新的API来隐藏这些缺陷。
考虑到这一点,我们的向量栈采用复合的方式实现。通过使用之前我们已经实现的向量数据结构作为基础,实现一个栈容器。
向量栈基本属性和接口:
/** * 向量为基础实现的 栈结构 * */ public class VectorStack <E> implements Stack<E>{ /** * 内部向量 * */ private ArrayList<E> innerArrayList; /** * 默认构造方法 * */ public VectorStack() { this.innerArrayList = new ArrayList<>(); } /** * 构造方法,确定初始化时的内部向量大小 * */ public VectorStack(int initSize) { this.innerArrayList = new ArrayList<>(initSize); } @Override public int size() { return innerArrayList.size(); } @Override public boolean isEmpty() { return innerArrayList.isEmpty(); } @Override public void clear() { innerArrayList.clear(); } @Override public Iterator<E> iterator() { return innerArrayList.iterator(); } @Override public String toString() { return innerArrayList.toString(); } }
由于我们的向量容器已经具备了诸如自动扩容等特性,因而向量栈的许多接口都可以通过简单的调用内部向量的接口来实现,不需要额外的操作。
栈的特有接口实现:
@Override public boolean push(E e) { //:::将新元素插入内部向量末尾(入栈) innerArrayList.add(e); return true; } @Override public E pop() { if(this.isEmpty()){ throw new CollectionEmptyException("Stack already empty"); } //:::内部向量末尾下标 int lastIndex = innerArrayList.size() - 1; //:::将向量末尾处元素删除并返回(出栈) return innerArrayList.remove(lastIndex); } @Override public E peek() { if(this.isEmpty()){ throw new CollectionEmptyException("Stack already empty"); } //:::内部向量末尾下标 int lastIndex = innerArrayList.size() - 1; //:::返回向量末尾处元素(窥视) return innerArrayList.get(lastIndex); }
栈的FIFO的特性,使得我们必须选择内部线性表的一端作为栈顶。
由于向量在头部的插入/删除需要批量移动内部元素,时间复杂度为O(n);而向量尾部的插入/删除由于避免了内部元素的移动,时间复杂度为O(1)。
而栈顶的元素是需要频繁插入(push)和删除(pop)的。出于效率的考虑,我们将向量的尾部作为栈顶,使得向量栈的出栈、入栈操作都达到了优秀的常数时间复杂度O(1)。
3.2 栈的链表实现
链表和向量同为线性表,因此栈的链表实现和向量实现几乎完全雷同。
由于链表在头尾出的增加/删除操作时间复杂度都是O(1),理论上链表栈的栈顶放在链表的头部或者尾部都可以。为了和向量栈实现保持一致,我们的链表栈也将尾部作为栈顶。
/** * 链表为基础实现的 栈结构 * */ public class LinkedListStack<E> implements Stack<E>{ /** * 内部链表 * */ private LinkedList<E> innerLinkedList; /** * 默认构造方法 * */ public LinkedListStack() { this.innerLinkedList = new LinkedList<>(); } @Override public boolean push(E e) { //:::将新元素插入内部链表末尾(入栈) innerLinkedList.add(e); return true; } @Override public E pop() { if(this.isEmpty()){ throw new CollectionEmptyException("Stack already empty"); } //:::内部链表末尾下标 int lastIndex = innerLinkedList.size() - 1; //:::将链表末尾处元素删除并返回(出栈) return innerLinkedList.remove(lastIndex); } @Override public E peek() { if(this.isEmpty()){ throw new CollectionEmptyException("Stack already empty"); } //:::内部链表末尾下标 int lastIndex = innerLinkedList.size() - 1; //:::返回链表末尾处元素(窥视) return innerLinkedList.get(lastIndex); } @Override public int size() { return innerLinkedList.size(); } @Override public boolean isEmpty() { return innerLinkedList.isEmpty(); } @Override public void clear() { innerLinkedList.clear(); } @Override public Iterator<E> iterator() { return innerLinkedList.iterator(); } @Override public String toString() { return innerLinkedList.toString(); } }
4.栈的性能
栈作为线性表的限制性封装,其性能和其内部作为基础的线性表相同。
空间效率:
向量栈的空间效率和内部向量相似,效率很高。
链表栈的空间效率和内部链表相似,效率略低于向量栈。
时间效率:
栈的常用操作,pop、push、peek都是在线性表的尾部进行操作。因此无论是向量栈还是链表栈,栈的常用操作时间复杂度都为O(1),效率很高。
5.栈的总结
虽然从理论上来说,栈作为一个功能上被限制了的线性表,完全可以被线性表所替代。但相比线性表,栈结构屏蔽了线性表的下标等细节,只对外暴露出必要的接口。栈的引入简化了许多程序设计的复杂度,让使用者的思维能够聚焦于算法逻辑本身而不是其所依赖数据结构的细节。
通常,暴露出不必要的内部细节对于使用者是一种沉重的负担。简单为美,从栈的设计思想中可见一斑。
这篇博客的代码在我的 github上:https://github.com/1399852153/DataStructures ,文章还存在许多不足之处,请多指教。