针对这段时间所学的做了一个简单的综合应用,应用的场景为统计一段时间内各个小区的网络信号覆盖率,计算公式如下所示:
分子:信号强度大于35的采样点个数
分母:信号强度为非空的所有采样点个数
网络覆盖率=分子/分母
原始数据为xml格式,记录各小区在各时刻的采样点,采样时间精确到ms,我们需要做的是计算单个小区以小时为间隔的信号覆盖率。通过简单的java代码解析xml文件,并将解析后的数据通过kafka生产者进程发送的kafka消息集群中,利用spark streaming进行实时处理并将处理结果存入redis。下面是数据处理过程
原始数据格式: 小区ID 信号强度 时间
155058480 49 2015-11-27T00:00:03.285
155058480 33 2015-11-27T00:00:05.000
155058480 空 2015-11-27T00:00:23.285
原始数据处理: 小区ID 分子 分母 时间
155058480 1 1 2015-11-27T00
155058480 0 1 2015-11-27T00
155058480 0 0 2015-11-27T00
统计合并处理: 小区ID 分子 分母 时间
155058480 1 2 2015-11-27T00
小区155058480的网络覆盖率=分子/分母=1/2=0.5
说明:以小区155058480为例的三个采样点,其中满足上述分子条件的非空记录的分子记为为1,不满足分子条件的非空记录与空记录的分子记为0,非空记录的分母记为1。同时对时间进行分割,保留到小时,并以时间个小区id为复合主键利用reduceByKey方法进行累加统计。
下面给出spark streaming代码:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.kafka.KafkaUtils
import redis.clients.jedis.Jedis
object SparkStreamConsumer {
private val checkpointDir = "data-checkpoint"
private val msgConsumerGroup = "message-consumer-group"
def main(args: Array[String]) {
if (args.length < 2) {
println("Usage:zkserver1:2181,zkserver2:2181,zkserver3:2181 consumeMsgDataTimeInterval(secs)")
System.exit(1)
}
val Array(zkServers,processingInterval) = args
val conf = new SparkConf().setAppName("Web Page Popularity Value Calculator")
val ssc = new StreamingContext(conf, Seconds(processingInterval.toInt))
//using updateStateByKey asks for enabling checkpoint
ssc.checkpoint(checkpointDir)
val kafkaStream = KafkaUtils.createStream(
//Spark streaming context
ssc,
//zookeeper quorum. e.g zkserver1:2181,zkserver2:2181,...
zkServers,
//kafka message consumer group ID
msgConsumerGroup,
//Map of (topic_name -> numPartitions) to consume. Each partition is consumed in its own thread
Map("spark-stream-topic" -> 3))
//原始数据为 (topic,data)
val msgDataRDD = kafkaStream.map(_._2)
//原始数据处理
val lines = msgDataRDD.map { msgLine =>
{
val dataArr: Array[String] = msgLine.split(" ")
val id = dataArr(0)
val timeArr: Array[String] = dataArr(1).split(":")
val time = timeArr(0)
val val1: Double = {
if (dataArr(2).equals("NIL")) 0 else if (dataArr(2).toFloat > 35) 1 else 0
}
val val2: Double = {
if (dataArr(2).equals("NIL")) 0 else if (dataArr(2).toFloat > 0) 1 else 0
}
((id,time),(val1,val2))
}
}
//通过reduceByKey方法对相同键值的数据进行累加
val test = lines.reduceByKey((a,b)=>(a._1+b._1,a._2+b._2))
//错误记录:Task not serializable
//遍历接收到的数据,存入redis数据库
test.foreachRDD(rdd=>{
rdd.foreachPartition(partition=>{
val jedis = new Jedis("192.168.1.102",6379)
partition.foreach(pairs=>{
jedis.hincrByFloat("test",pairs._1._1+"_"+pairs._1._2+":1",pairs._2._1)
jedis.hincrByFloat("test",pairs._1._1+"_"+pairs._1._2+":2",pairs._2._2)
jedis.close()
})
})
})
/*//通过保存在spark内存中的数据与当前数据累加并保存在内存中
val updateValue = (newValue:Seq[(Double,Double)], prevValueState:Option[(Double,Double)]) => {
val val1:Double = newValue.map(x=>x._1).foldLeft(0.0)((sum,i)=>sum+i)
val val2:Double = newValue.map(x=>x._2).foldLeft(0.0)((sum,i)=>sum+i)
// 已累加的值
val previousCount:(Double,Double) = prevValueState.getOrElse((0.0,0.0))
Some((val1,val2))
}
val initialRDD = ssc.sparkContext.parallelize(List((("id","time"), (0.00,0.00))))
val stateDstream = lines.updateStateByKey[(Double,Double)](updateValue)
//set the checkpoint interval to avoid too frequently data checkpoint which may
//may significantly reduce operation throughput
stateDstream.checkpoint(Duration(8*processingInterval.toInt*1000))
//after calculation, we need to sort the result and only show the top 10 hot pages
stateDstream.foreachRDD { rdd => {
val sortedData = rdd.map{ case (k,v) => (v,k) }.sortByKey(false)
val topKData = sortedData.take(10).map{ case (v,k) => (k,v) }
//val topKData = sortedData.map{ case (v,k) => (k,v) }
//org.apache.spark.SparkException: Task not serializable
topKData.foreach(x => {
println(x)
jedis.hincrByFloat("test",x._1._1+"_"+x._1._2+":1",x._2._1)
})
}
}*/
ssc.start()
ssc.awaitTermination()
}
}
一开始我将数据库连接操作放在foreachRDD方法之后,程序运行出错,在网上没有找到对应的解决方案,于是仔细阅读官网资料,在官网上找到了下面一段话:
Often writing data to external system requires creating a connection object (e.g. TCP connection to a remote server) and using it to send data to a remote system. For this purpose, a developer may inadvertently try creating a connection object at the Spark driver, and then try to use it in a Spark worker to save records in the RDDs. For example (in Scala),This is incorrect as this requires the connection object to be serialized and sent from the driver to the worker. Such connection objects are rarely transferrable across machines. This error may manifest as serialization errors (connection object not serializable), initialization errors (connection object needs to be initialized at the workers), etc. The correct solution is to create the connection object at the worker.
其中,需要注意的是foreachRDD方法的调用,该方法运行于driver之上,如果将数据库连接放在该方法位置会导致连接运行在driver上,会抛出connection object not serializable的错误。因此需要将数据库连接方法创建在foreach方法之后,需要注意的是这种做法还需要优化,因为这样会对每个rdd记录创建数据库连接,导致系统运行变慢,可以通过先调用foreachPartition方法为每个分区单独重建一个数据库连接然后再该分区之内再遍历rdd记录。这样可以减少数据库连接的创建次数,还可以通过构建数据库连接池的方法继续优化,这里就不再赘述了。
利用idea将程序编译成jar包之后上传到spark安装目录的lib目录下,通过spark-submit SparkStreamConsumer.jar datanode1:2181 2,运行程序。其中datanode1:2181是集群中zookeeper的地址。
另外需要注意的就是,需要将jedis包发送到集群中各节点的spark安装目录的lib目录下。
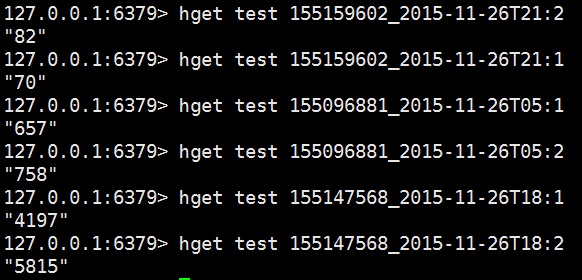
通过redis客户端可以查看存储的计算结果,存储结构为(key,value)=>(id_time:1,val1) (id_time:2,val2),例如155159602小区在2015-11-26 21点的网络覆盖率为70/82=0.85。