廖一梅《恋爱的犀牛》是我很爱的一本小说
所以这次大作业,我选择爬取豆瓣网书摘,并以此生成词云,完成可视化
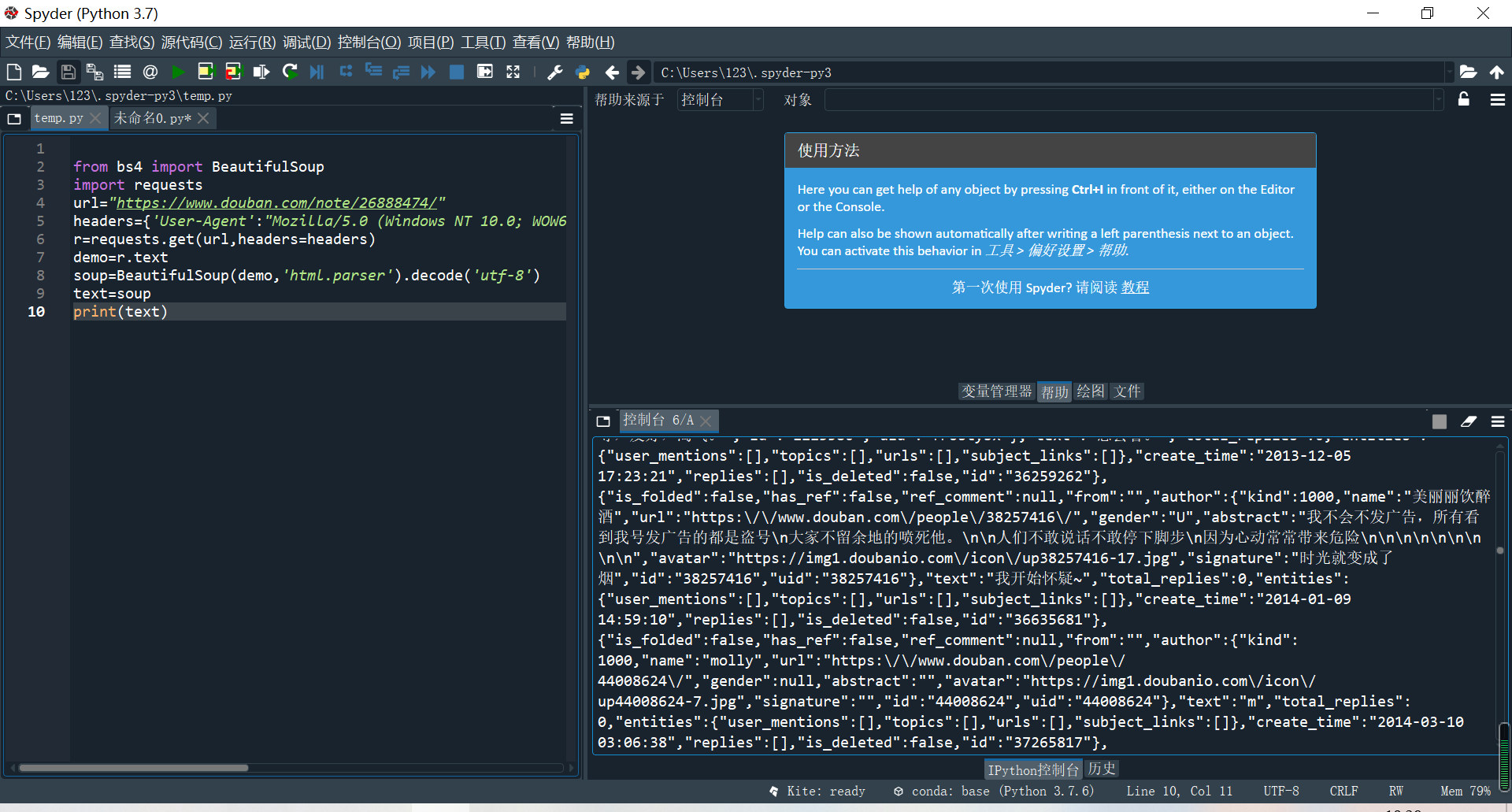
首先爬取网页信息:
https://www.douban.com/note/26888474/

我遇到的第一个问题就是网页拒绝访问,参考了教员发在群里的那篇博文,最后成功访问


第二个问题就是我爬下来的信息混杂着中文英文和各种奇怪的字符:
于是我使用了chinese_only = ''.join(x for x in text if ord(x) > 256)语句进行筛选:

还剩下汉字和字符
接下来就是使用jieba分词和word cloud生成词云的过程
为了使词云更美观,我使用了从网上下载的汉仪小麦简体,背景图是一只猫猫的形状
第一次生成的词云如下:

可见其中有许多的废词 “豆瓣” “什么” ……
于是在stopwords字典当中添加出不需要显示的词汇
修改后效果如下:

献上源代码:











# -*- coding: utf-8 -*- """ Created on Fri May 1 08:27:02 2020 @author: 123 """ import wordcloud import jieba from bs4 import BeautifulSoup import requests url="https://www.douban.com/note/26888474/" headers={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"} r=requests.get(url,headers=headers) demo=r.text soup=BeautifulSoup(demo,'html.parser').decode('utf-8') text=soup chinese_only = ''.join(x for x in text if ord(x) > 256)
from imageio import imread mask = imread("C:/Users/123/Desktop/miaomiao.jpg") excludes = {'豆瓣','什么','东西'} ls = jieba.lcut(chinese_only) txt = " ".join(ls) w = wordcloud.WordCloud(font_step=2,width = 1000, height = 700, background_color = "white",mask = mask, stopwords=excludes,font_path='C:/Users/123/Desktop/汉仪小麦体简.ttf') w.generate(txt) w.to_file("恋爱的犀牛.png")










