一、拾遗
1、生成器表达式形式的多个函数之间的协同工作。
例:做一包子吃一个包子
优点:更省内存。
以上例子的原理: 重点★★★★★

源代码:
import time
import random
# 装饰器
def init(func):
'''生成器表达式的初始化'''
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper
def cook(people,count):
'''定义一个厨师'''
for i in range(count):
time.sleep(random.randrange(1,4))
x='包子%s' % i
print('�33[47m厨师做好的包子:%s�33[0m' %x)
people.send(x)
@init
def eater(name):
'''定义一个吃货'''
while True:
bun=yield
time.sleep(random.randrange(1, 4))
print('�33[46m%s开始吃%s�33[0m' %(name,bun))
cook(eater('小白'),20)
2、三元表达式之生成器表达式的补充。
例:
要求:求一个商品文件中所有物品的价格总和
有一个记载了商品的.txt文件,里面的内容如下:

代码如下:

以上代码太长,这里用三元表达式中的列表解析来精简代码,但是列表解析是把文件内容都放到内存空间,会造成占用过多内存。所以最好是用生成器表达式,一来精简代码,二来节省内存。
代码如下:
money = []
with open('shop_list','r',encoding='utf-8') as f:
t = (float(line.split('|')[1]) * int(line.split('|')[2]) for line in f)
print(sum(t))
输出结果:
724280.0
3、模拟数据库查询操作
要求:把第2小点中的例子中的数据取出来,拼接成一个有结构一样的数据,类似数据库的查询功能
分析:把所以数据查出来,它们只是一串字符串,然后把这些字符串拼接成一个字典的形式,这样我们就能通过键找到相对应的值了。
商品列表如下:
代码如下:
goods_info = [] # 用来存放所有的商品,每件商品以字典的形式存放
with open('shop_list','r',encoding='utf-8') as f:
goods_info = [{'name':line.split('|')[0],'price':line.split('|')[1],'count':line.split('|')[2]} for line in f]
print(goods_info)
输出结果:


[{'name': 'apple', 'price': '3.2', 'count': '1000'}, {'name': 'banana', 'price': '1.8', 'count': '600'}, {'name': 'ipad', 'price': '4000', 'count': '100'}, {'name': 'macbook pro', 'price': '10000', 'count': '30'}, {'name': 'soap', 'price': '2', 'count': '10000'}]
将要求更改:只取价格大于等于4000的商品。
代码如下:
goods_info = [] # 用来存放所有的商品,每件商品以字典的形式存放
with open('shop_list','r',encoding='utf-8') as f:
goods_info = [{'name':line.split('|')[0],'price':float(line.split('|')[1]),'count':int(line.split('|')[2])} for line in f
if float(line.split('|')[1]) >= 4000]
print(goods_info)
输出结果:
[{'name': 'ipad', 'price': 4000.0, 'count': 100}, {'name': 'macbook pro', 'price': 10000.0, 'count': 30}]
二、内置函数与lambda
之前学过的函数都是有函数名的,该函数名是用于绑定值的,与变量名的定义类似,当创建一个函数时,此时函数名绑定了一个值,这个值的引用计数器则加1,一旦没有函数名来引用这个值了,这个值将会被python的内存回收机制给回收。但是匿名函数除外。
1、匿名函数——lambda
(1)特性:
(1)没有函数名
(2)函数参数的命名规则与有名函数是一样的。
(3)定义形参时直接写参数名且不用加上括号
(4)一行代码即可完成创建函数
(5)自带return效果,所以一定有返回值
(6)定义完后就会被python内存回收机制回收
(2)格式:
lambda 参数1,参数2...... :函数体 # 匿名函数的函数体就相当于有名函数的retturn返回值。
(3)应用场景:
只能应用简单的函数,不能应用复杂的函数
有时我们只需要用一次函数时,且必须要清理该函数时便可以用到匿名函数。
(4)例子:
res1 = lambda x:x**2 print(res1(3)) res2 = lambda x,y:x+y print(res2(100,1000)) res3 = lambda x:x>1 print(res3(0))
输出结果:
9
1100
False
2、内置函数—max()
定义:比较最大值
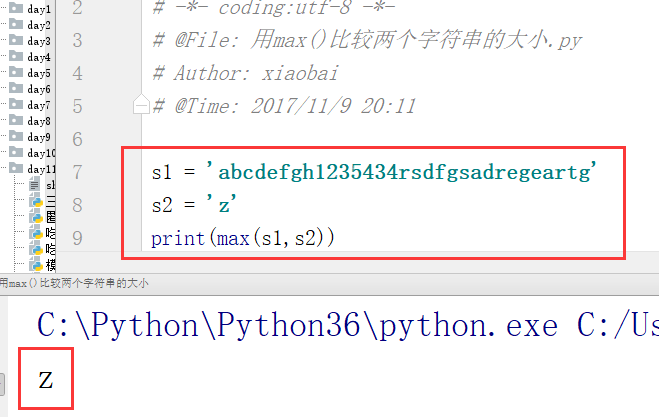
注意:当用max()比较字符串的最大值时,不是比较字符串的长度,而是比较按字符串中的首字母排序位置进行比较。
例1:比较两个字符串的大小:
例2:用max()比较出年龄最大的人。
如果直接用print打印max(user_age)则得到谢公子,但是谢公子对应的年龄才32岁,所以得出结论,传入一个字典给max比较的是字典key的大小,而key是字符串则是按字符串中的首字母排序大小来进行比较的。
user_age = {
'xiaobai':30,
'lisa':18,
'张鑫宇':80,
'糖宝':70,
'小宋':25,
'谢公子':32
}
res = zip(user_age.values(),user_age.keys()) # zip()的作用是拉链的作用,左边取一个值,右边也取一个值相互对应,将每次取到的左右的值组成一个个的小元组。
print(max(res)[-1])
输出结果:
张鑫宇
例3:用有名函数+max()比较出最大年龄的人
user_age = {
'xiaobai':30,
'lisa':18,
'张鑫宇':80,
'糖宝':70,
'小宋':25,
'谢公子':32
}
def age(x):
return user_age[x]
print(max(user_age,key=age))
输出结果:
张鑫宇
例4、用匿名函数+max()比较出最大年龄的人
user_age = {
'xiaobai':30,
'lisa':18,
'张鑫宇':80,
'糖宝':70,
'小宋':25,
'谢公子':32
}
print(max(user_age,key=lambda x:user_age[x]))
输出结果:
张鑫宇
max()函数与min()函数操作都是一样的,只是一个是比较最大值,一个是比较最小值而已。
三、递归
1、定义:
递归也叫递归调用,在调用一个函数的过程中,直接或者间接调用了该函数的本身
2、无限递归
就是自己调用自己,python中已经限制了这种方式的调用了。因为它会使内存溢出。
(1)直接调用
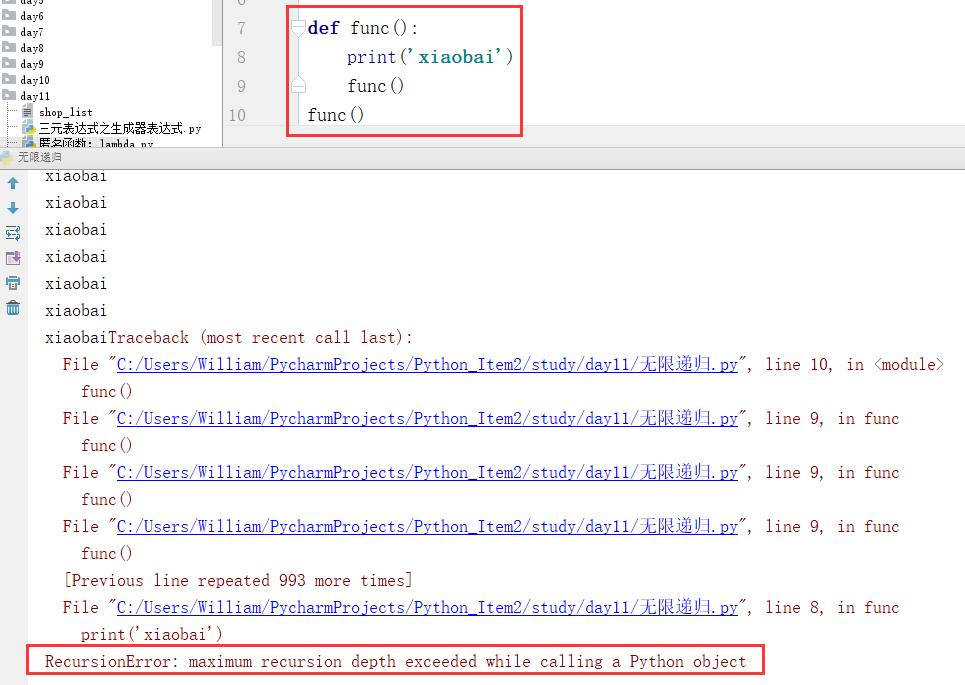
可以通过python中的sys模块里的getrecursionlimit值去查看python对递归的限制
import sys from sys import getrecursionlimit print(sys.getrecursionlimit())
输出结果:
1000
说明,最多可以递归到1000层,超出这个值,python就会报错。可以通过sys模块中的setrecursionlimit值去更改限制递归层数。
import sys from sys import setrecursionlimit print(sys.setrecursionlimit(1000000000)) # 增加递归层数至1000000000,但是受限于内存,最好是不要去更改。
输出结果:
1000000000
(2)间接调用

3、递归的层级限制:
在python中,递归的效率低,只要进入下一次递归,就要把上一次状态保留着,因为上一次还没有执行完,只有在下一个阶段执行完了它才算执行完。
另外python中没有尾递归,且对递归层级做了以下 限制:
(1)必须有一个明确的结束条件
(2)每次进入更深一层递归时,问题规模相比上次递归都应用所减少
(3)递归效率不低,递归层次过多会导栈溢出
4、递归的两个阶段
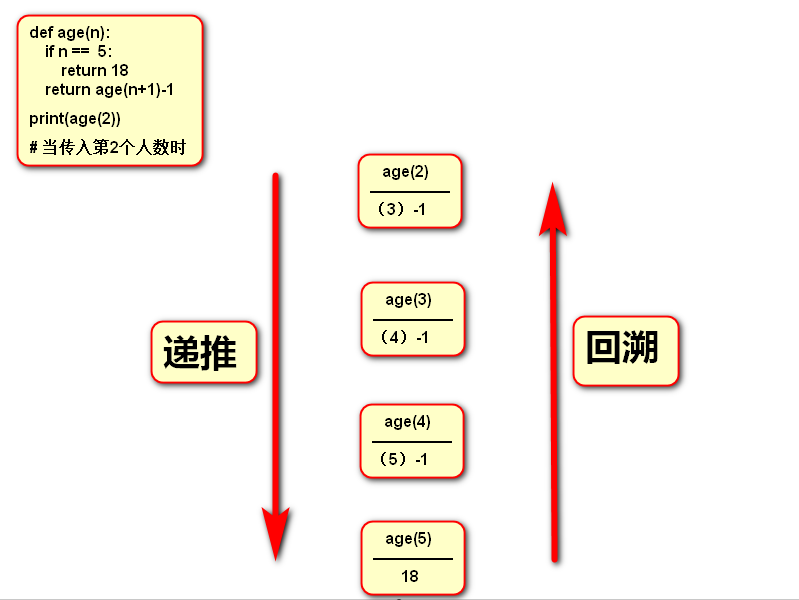
递推和回溯
定义:一层一层推下去,一直推到目标阶段才停止,这就是递推。最后由目标阶段再沿着这条路线返回去,这就叫回溯。
例子:
用一个形象的例子说明递归的两个阶段——猜年龄
递推:
学生a要想要知道学生b的年龄,但是学生b只说了比学生c小1岁,于是学生a又去问学生c的年龄,学生c又说比学生d小1岁,此时学生a又不得去问学生d的年纪,学生d又说比学生e小1岁,最后学生a再去问学生e,学生e就告诉学生a他今年18岁了。这个过程就类似于python递归中的递推。
回溯:
然后学生a根据学生e的年龄倒推回来,猜出学生d的年龄为17岁,再通过学生d的年龄最终猜出学生c的年龄为16岁。最终通过学生c的年龄猜出学生b的年龄为15岁,这个过程就类似于python中递归中的回溯。

写一个代码描述以上猜年龄的例子
分析:
根据以上例子可以总出一个规律:被猜年龄的每位同学都比之前的同学小一岁,最后一位学生e的年龄为18岁,那么可以先用一个变量来表示有多少学生,当数到年龄等于18岁的学生时则拿到最终结果。每传来代码如下:
def age(n):
if n == 5: # 表示当到达第5个人时,则返回第5个人的年龄
return 18
return age(n+1)-1 # n+1表示人数,后面的-1表示规律:后一个人的年龄比前一个的小1岁。
# 当传入其他人数时,则将返回其他人的年龄
print(age(2)) # 传入人数进去
输出结果:
15
用一个流程图来说明以上猜年龄的例子。
小练习:
要求:取出列表“l”中所有的元素
# 取出列表“l”中所有的元素
l = [1,2,[3,4,[5,6,[7,8,[9,10,[11,12,[13,14]]]]]]]
# 此列表可以用for循环取出,但是不知道这个列表嵌套了多少层,所以用for循环取值麻烦,
# 所以在场景下最好的方法就是用递归的方式取值
def func(l):
for i in l: # 先遍历得到“l”列表中最外层内有多少个元素
if isinstance(i,list): # 判断遍历出的元素如果是列表,则调用该列表继续循环。
func(i) # 此时的“i”继续传给func函数继续调用。
else:
print(i) # 否则,如果是元素则打印出来
func(l)
输出结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
结论:
经以上例子说明递归在不知道循环多少次,只知道什么时候应该结束掉时最好用递归