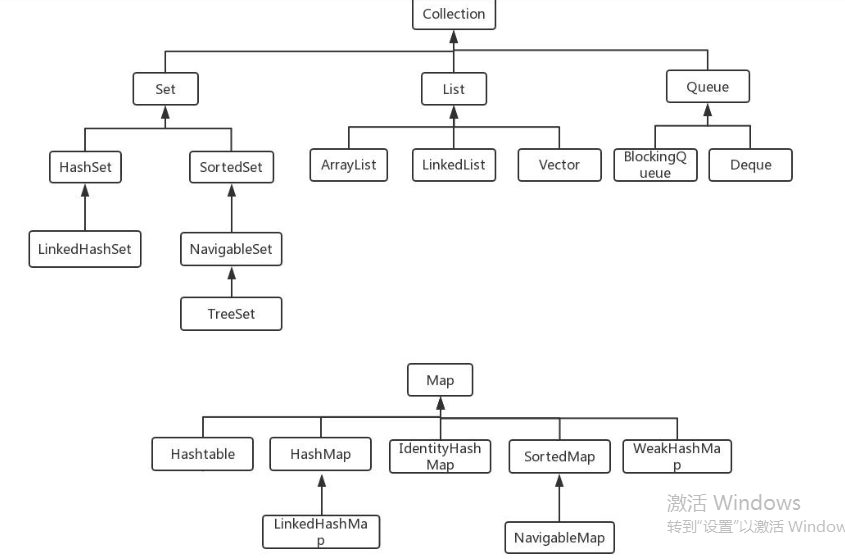
一、java集合:
1.collection接口的子接口:set接口跟list接口
2.map接口的实现类:hashMap、hashTable、concurrentHashMap、hashTable、treemap;
3.set接口的实现类:hashSet、LinkedHashSet、treeSet;
4.List接口的实现类:ArrayList、LinkedList、vector等;
二、java集合详细说明:
1.List:
ArrayList: 有序、非线程安全、值可以为null、值可以重复,底层实现Object数组,它实现了Serializable接口,因此它支持序列化;
优点:查询快,插入、删除慢;
ArrayList的动态扩容:
linkedList:有序、非线程安全、底层实现是链表,插入、删除快,查询效率不高;
vector:跟ArrayList结构相似,死线程安全的,加了synchronized;
2.Map:
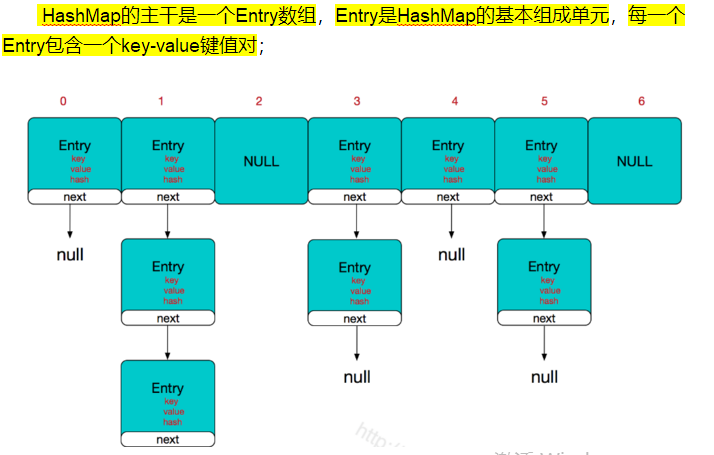
HashMap:
底层实现原理:jdk1.8之前,hasMap是数组+链表;jdk1.8之后,数组+链表+红黑树,当链表超过8的时候,链表就会转化为红黑树,利用红黑树快速增、删、改、查的特点提高HashMap的性能;
entry数组包含 key、val、hash值、next对象;
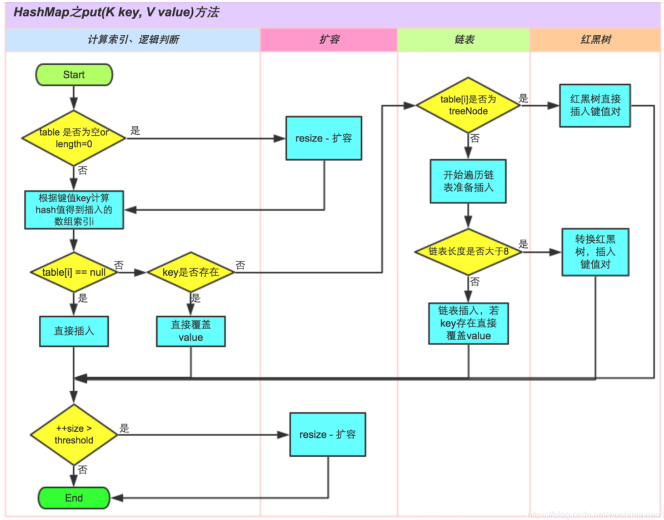
加载因子loadFactory:默认为0.75,初始化容量initialCapacity:默认为16,加载因子存在的原因:为了减少哈希冲突,如果初始桶为16,等到满16个元素才扩容,某些桶里可能就不止一个元素了,所以加载因子默认为0.75,也就是说大小为16的HashMap, 到了第13个元素就会扩容成32;
阀值threshold:一般为capacity*loadFactory;扩容的时候会用到阀值;
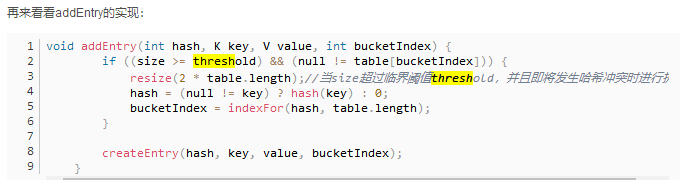
当发生哈希冲突,并且元素数量大于阀值的时候,就会扩容,扩容时需要创建一个为之前数组长度2倍的新的数组,然后将当前的Entry数组中的元素全部传输过去;
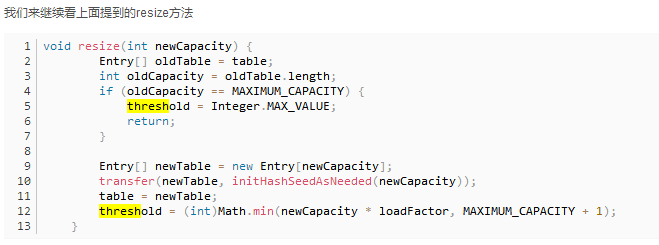
旧的数组的大小如果已经最大(2^30)了,那么将不再扩容,将阀值设定为int的最大值;如果没有,那就初始化一个原来数组长度两倍的新的数组,将数据转移到新的数组;
concurrentHashMap:
concurrentHashMap的数据结构:
在jdk1.7之前是segment数组+hashEntry数组,segment实际继承自可重入锁(ReentrantLock),在concurrentHashMap中扮演锁的角色,hashEntry则用于存储键值对数据,一个concurrentHashMap包含一个segment数组,一个segment包含一个hashEntry数组,称为table,每个HashEntry是一个链表结构的元素;
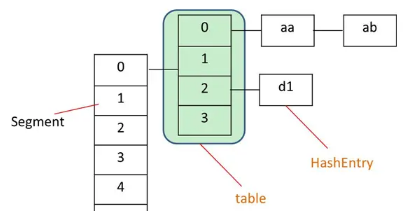
在get和put操作中,是如何快速定位元素放在哪个位置的?
对于某个元素而言,一定是存放在某个segment下的某个table元素中:
定位segment:取得key的hashcode值,进行一次再散列,拿到散列值后,以再散列值的高位进行取模,得到当前元素在哪个segment上;
定位table:取得key的再散列值,用再散列值的全部和table的长度进行取模,得到当前元素在table的哪个元素上;