系统架构
漏斗原理:请求在网络传输过程中,越往后,请求慢慢的会减少,所以说到数据库服务器的请求量会比在Web服务器的少
一、基本架构
一个系统的网络拓扑图:我们常说的服务器是软硬件结合的一个概念,服务器服务器,只有硬件没软件其实不能称之为一个完整的服务器

一个问题:什么是 to B ,什么是 to C?
有些人可能会说,B就是browser,C就是Client。但是实际上真的是如此么???
其实C就是面向用户,比如说淘宝、QQ、饿了么、美团、大众点评等对我们个人来讲,就是个 to C 的产品,客户端;但是,面向商家的就是 to B(bussiness) 端 ,比如淘宝有商家平台,B不是说一个浏览器,比如说QQ,是个客户端。
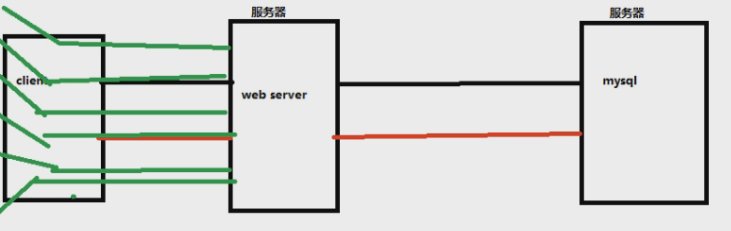
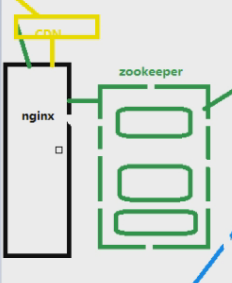
基本的系统架构就是上图,但是当我们的请求加多,日活增多,请求会发到哪里???其实第一步是打在了网络上!所以网络加速发展了,但是最终的请求量全部打到了服务器上,早期就引入了一个名词,叫——负载均衡,早期一般用apache做负载均衡,但是单机只能支持1W的并发,Nginx官方的介绍是支持20W的并发
二、负载均衡
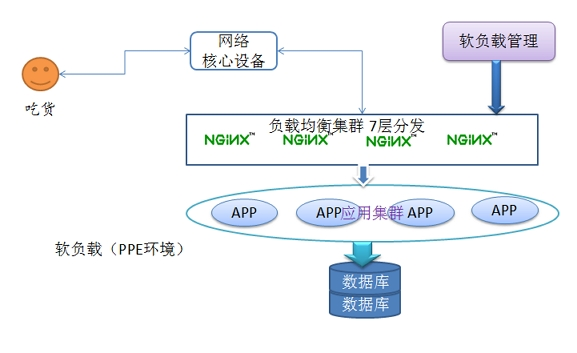
分为两种:硬负载,软负载。那么什么叫硬负载,什么叫软负载呢?(左图硬负载、右图软负载)
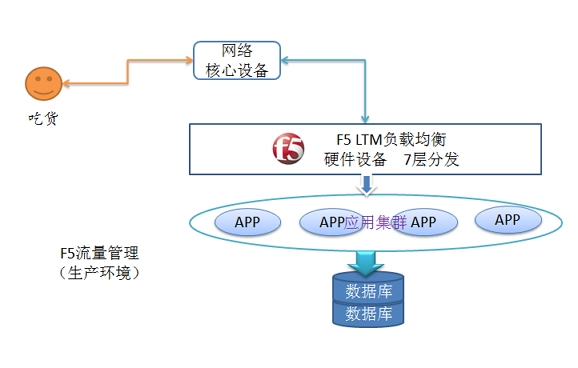
硬负载(F5):就是企业单位,事业单位一般用到的,叫 F5 。直接在服务器和外部网络间安装负载均衡设备,这种设备我们通常称之为负载均衡器。由于专门的设备完成专门的任务,独立于操作系统,整体性能得到大量提高,加上多样化的负载均衡策略,智能化的流量管理,可达到最佳的负载均衡需求。 一般而言,硬件负载均衡在功能、性能上优于软件方式,不过成本昂贵,比如最常见的就是F5负载均衡器。
优点:能够直接通过智能交换机实现,处理能力更强,而且与系统无关,负载性能强更适用于一大堆设备、大访问量、简单应用
缺点:成本高,除设备价格高昂,而且配置冗余.很难想象后面服务器做一个集群,但最关键的负载均衡设备却是单点配置;无法有效掌握服务器及应用状态.
硬件负载均衡,一般都不管实际系统与应用的状态,而只是从网络层来判断,所以有时候系统处理能力已经不行了,但网络可能还来 得及反应(这种情况非常典型,比如应用服务器后面内存已经占用很多,但还没有彻底不行,如果网络传输量不大就未必在网络层能反映出来)
软负载(Nginx、lvs、proxy):把请求分发到软件上。
优点:基于系统与应用的负载均衡,能够更好地根据系统与应用的状况来分配负载。这对于复杂应用是很重要的,性价比高,实际上如果几台服务器,用F5之类的硬件产品显得有些浪费,而用软件就要合算得多,因为服务器同时还可以跑应用做集群等。
缺点:负载能力受服务器本身性能的影响,性能越好,负载能力越大。
综述:对我们管理系统应用环境来说,由于负载均衡器本身不需要对数据进行处理,性能瓶颈更多的是在于后台服务器,通常采用软负载均衡器已非常够用且其商业友好的软件源码授权使得我们可以非常灵活的设计,无逢的和我们管理系统平台相结合。
Nginx的图可以这样理解:这三个服务器,所放置的代码都是一致的,连接的数据库,也是一致的,否则我的数据就不知道跑到哪里去了。。。Nginx相当于是处理请求的流向,相当于秩序的维护者
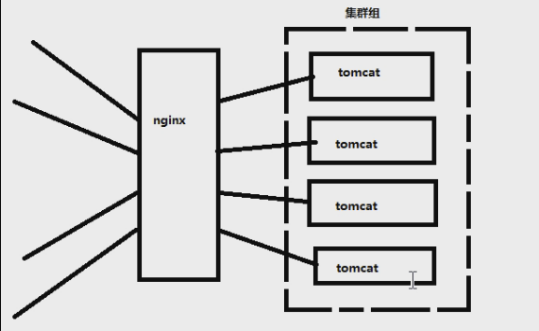
这样,可以处理20W的用户并发,但是如果我的请求再很大呢???那就做 Nginx 集群,Nginx 下面再套 Nginx 去分发请求,但是我们一般小公司用不到
三、数据库
那么,在 Web 服务器能处理这些请求的前提下,这些请求全部发送到一个数据库服务器,数据库访问量大一个服务器能抗住么???用户量大加机器,数据库要怎么弄?
结论:数据库也做集群组
方式:
1、数据库备份
早期都是用数据库的备份,就是我有两个数据库服务器 A 和 B ,挂了 A 我还有 B 在撑着,定时把数据库备份到其他数据库。这样数据库是有丢数据的现象的,一般晚上备份,但是丢数据总比没有的强
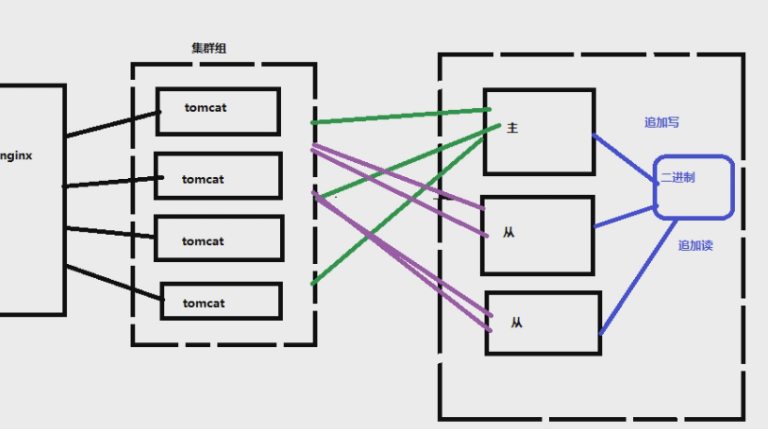
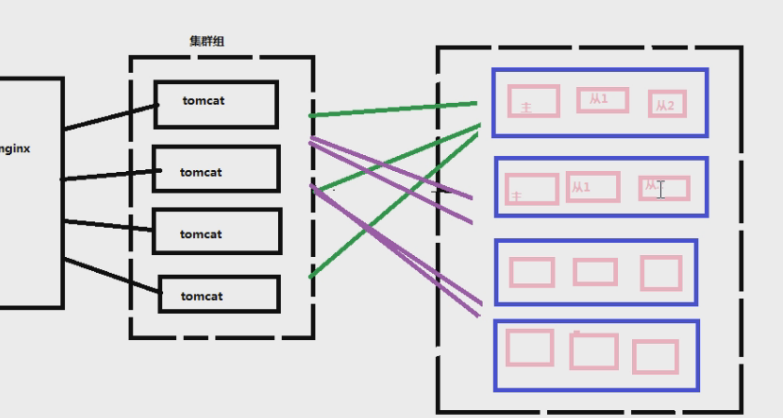
2、数据库读写分离
现在都是对数据库进行读写分离。主库负责写(insert、delete、update),从库负责读。一般读操作更多,所以读操作的机器一般会更多。这样数据库的压力会减轻
四、微服务
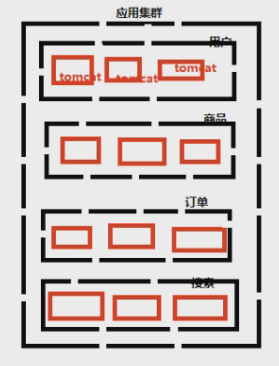
我们用淘宝举例子:简单说一个业务:比如说账户系统,用户系统。用户系统不仅仅是账户系统,是个大核心,对接多少东西?支付宝、天猫、阿里云、阿里妈妈、饿了么、web系统等……所以不仅仅是一张表能把它存完,那些积分,收货地址,收藏等。除了用户系统,还有些商品模块,商品的展示模块有很多东西:库存,分类,价格,销量等等。检索模块,搜索不只是搜索,里面有很多内容在里面,广告、销量排名等等。还有很多小业务:订单,购物车,支付,消息等。这些小的业务就叫做微服务。
如果这些服务在一个系统内实现,一个服务出了问题,那么整个系统都得崩溃。天猫双11上次的事件,改不了收件地址;退款退不了。这些个别功能使用不好使,并没影响到其他公司功能的使用,登录==>搜索==>下单==>付款都没问题。把大的业务,拆分成一个一个的服务,减少系统的耦合度。降低由单个功能的故障引起整个系统不可用的可能性。

五、缓存
我们之前讲为什么要参数化,是为了避免数据库查询缓存。关系型数据库本身有缓存,指的是我们查询出一条数据,会生成一条查询计划,存在数据库的缓存内,下次我们查询语句假设一模一样,就会命中这个缓存,就可以很快地返回出要的查询数据。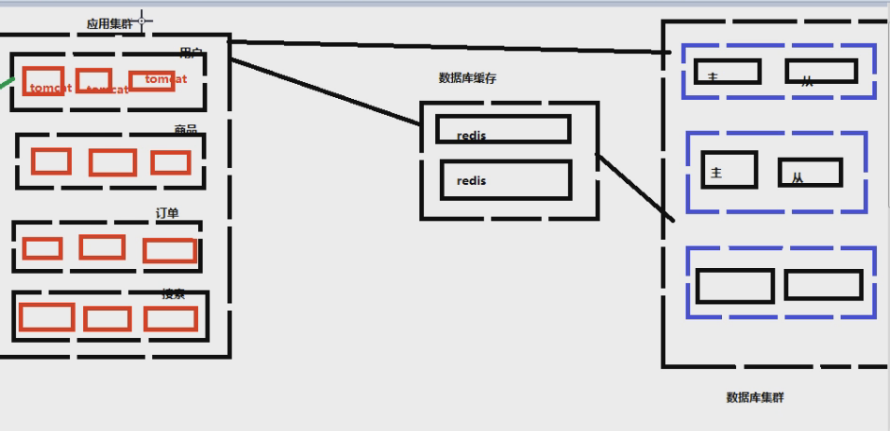
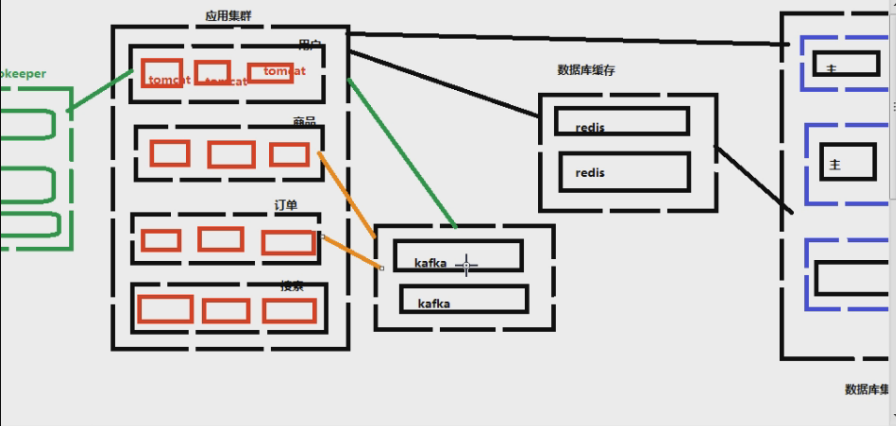
六、消息系统
Kafka,消息中心。什么叫消息中心呢?
比如说在淘宝上支付商品完成,对系统来说要做哪几件事?
七、图片服务器&文件服务器
图片是存在哪?放在数据库?如果在数据库要从数据库读地址,再去DNS地址内找图片再显示?每个公司都有图片服务器,专门是负责处理图片压缩,拉伸放大,存储等。
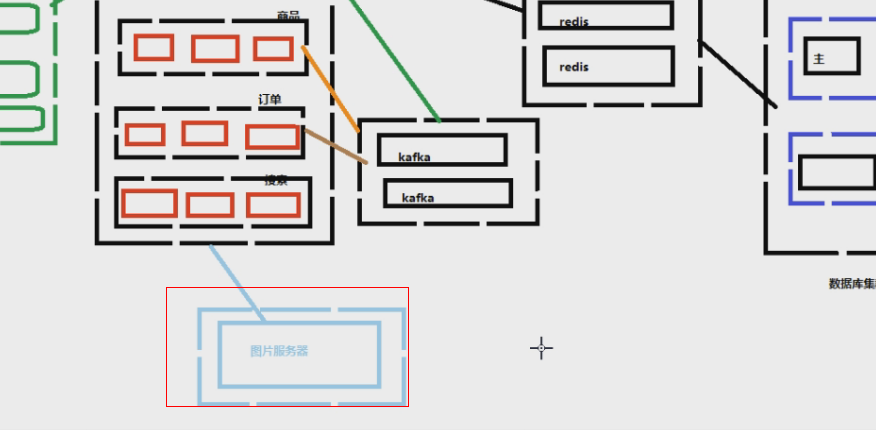
文件服务器DFS(存入数据,报表之类的)比如说,淘宝的销量表,不可能是实时生成的,那样查询太慢了,是存储在服务期内的。比如说小米的双11销量表,客户从哪儿买的?分布的城市,买的型号,价格等等;其他厂商也是如此。如果要都是去数据库查询,那不就完蛋了。那么肯定是先生成,再展示,数据文件存储在文件服务期内。文件服务器常见的是DFS

八、CDN节点加速
国内最出名的cdn两家是哪两家?蓝汛 网宿
也是一种缓存,缓存的是啥?一般来讲是缓存图片,怎么缓存?
把那些图片存在就近的那个地域的服务器上,不同的用户区请求服务器,就从就近的服务器取,而不是从最大的那个后台的服务器取;比如说广州的请求,就在南方这边的服务器上取,而不是从北京的终端后台。cdn存的是静态的资源,某些一段时间不变的东西,js,css那些;可以看下f12,域名不是自己的基本是从cdn节点取
比如说百度的首页:有些js,图片,这个域名都不是baidu,所以是存在cdn节点上的

请求通过DNS域名解析,解析成一个ip:port这个ip:port是Nginx的域名和端口,不是的话那就直接访问到后面的应用服务器了。Nginx是负载均衡,请求来了,分发给后面的服务器,Nginx干了活但是不处理请求的业务逻辑,只是分配任务。请求分发到注册中心(配后台有哪些接口的,这些接口谁能调用它?),然后看接口是谁配的,给接口的提供者,然后再处理业务逻辑注册,然后去数据库里面查有没有这个用户,给出相应提示。这里我们没用到redis,因为不是重复的,注册一次就行了。那么什么会用到redis?天猫首页的商品,那些首页的商品金额等。也就是用户会频繁点击,用户访问量大的东西。哪里用到kafuka呢?日过做了某件事,对其他的服务有通知,有影响,那么就需要kafuka,比如典型的下单付款等。这意思是,不是每个业务逻辑都得走完服务器所有东西。
整个架构:
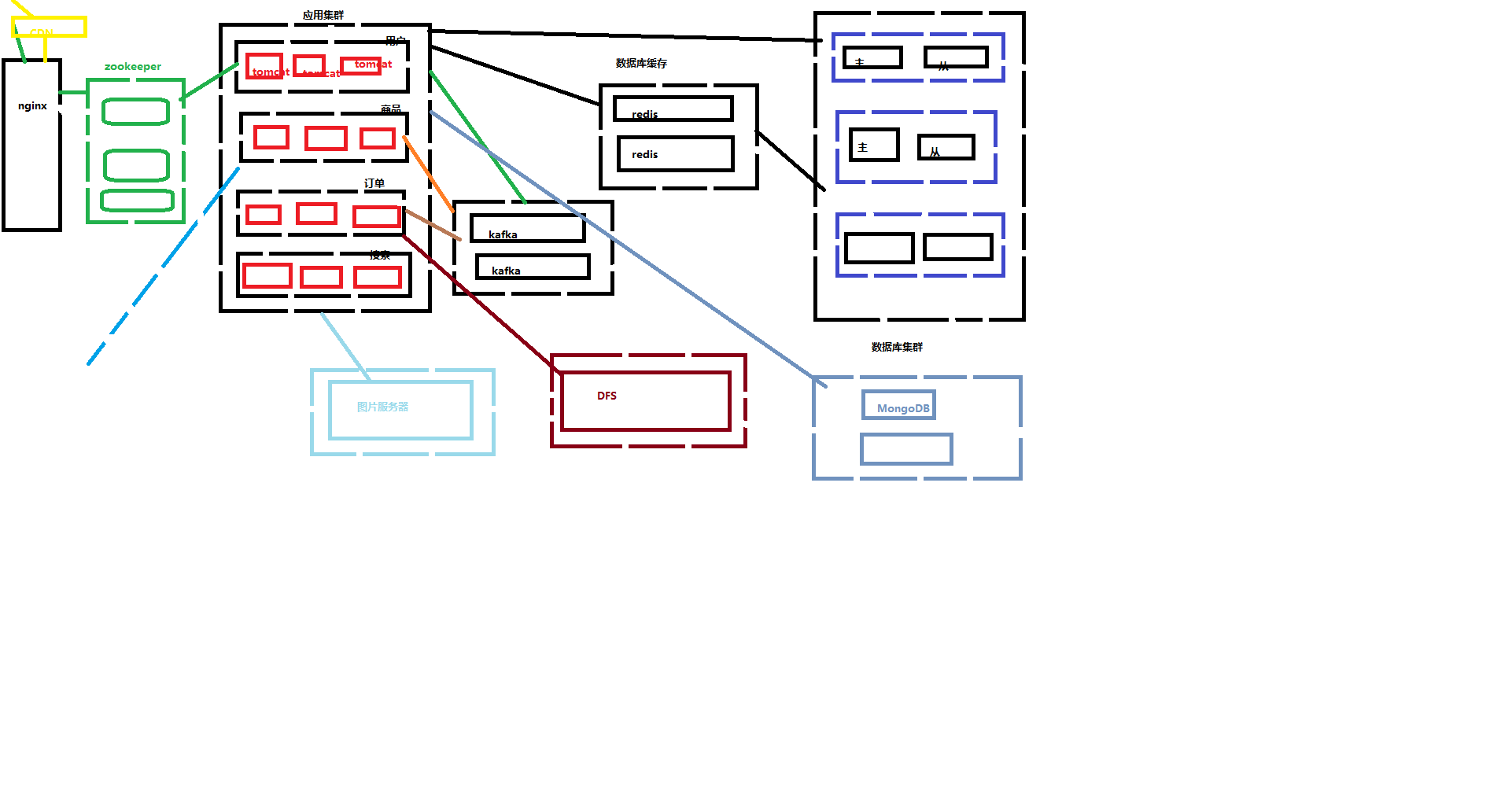
以上算是一个比较成熟的系统,应用服务期内并没有完全写完,不同的服务内部也有不同的内部架构,要深入理解并且记住,对于不理解的内容,中间件等的原理还得自己深入去理解。
系统分析
一、响应时间
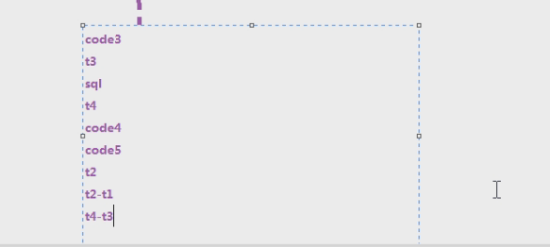
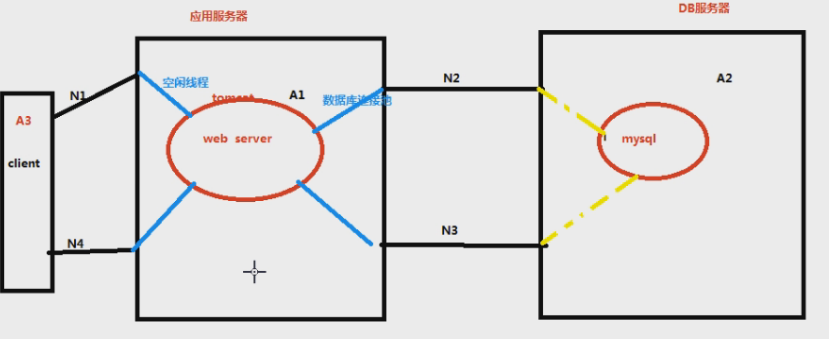
响应时间是哪些的和?N1+N2+N3+N4+A1+A2
服务端的接口处理的时间其实是分为两部分的,一是接口本身响应的时间,二是去数据库查数据的时间之和:=A1+A2+N2+N3

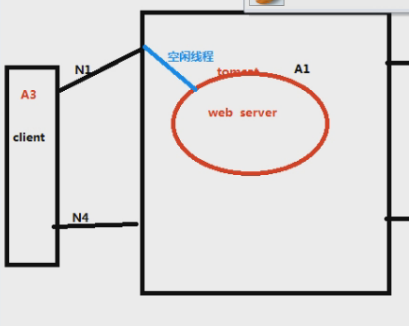
读代码之后,读到请求数据库的语句时,这个线程就会挂起,需要找到空闲的程序与数据库的连接池,才能把请求发到数据库内,容器里面一般配20-30个,120个最大
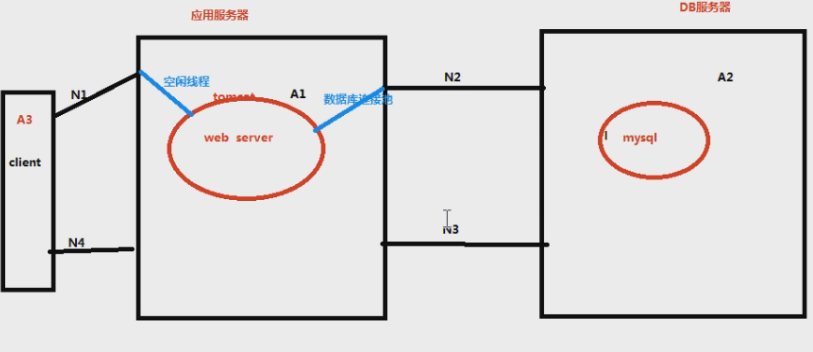
数据库本身也有连接池,一般1800(黄线)
响应时间太慢,可能的原因在哪???
1、自身的Client端产生请求阻塞(CPU排队/带宽满了)
2、网络传输时间过长/网络带宽是否有瓶颈(带宽能上传多少,要除以8,比如说100Mbps,一秒只能上传100/8Mb)
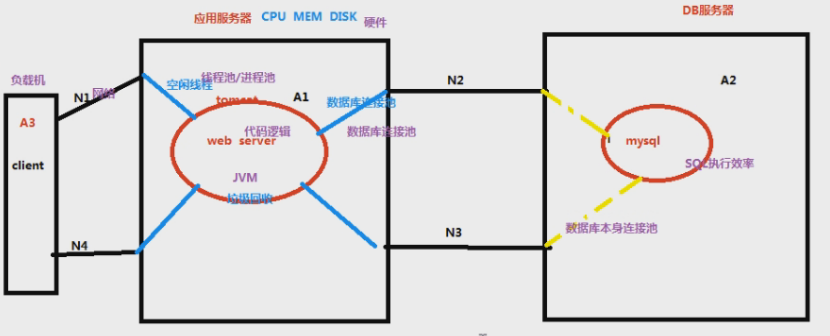
3、web应用服务器里面的问题分以下几点:
- 服务器的CPU/内存/磁盘是不是符合条件; CPU满了,内存满了,磁盘满了不够资源后面的就不用看了,应为软件运行的基本环境都不具备,然后往下走
- web容器tomcat没有空闲线程/进程; 有空闲线程才能处理,如果都繁忙,容器内没有线程处理,都满了,在容器池那里就得排队,没问题再往下走
- 代码的业务逻辑实现好坏; 进入到web服务期内,才开始读代码,读到代码的业务逻辑实现太烂了也可能会影响运行的时间
- 如果请求需要请求数据库,需要看应用程序跟数据库服务器没有空闲的连接池,是否要进行排队; 有数据库交互要看web和db之间有没有空闲的连接池通道,没有也得排队
- 应用服务器与数据库服务器连接,网络是否通畅; 如果这俩不在一个服务器上,也是用网络连接
4、DB服务器
- 数据库本身的连接池够不够
- 这里面的CPU、内存、磁盘分析
- 数据库的执行效率太低
5、web服务器容器内没有进行垃圾回收(GC),没有足够的内存去执行代码
6、返回的网络以及带宽
怎么分析问题所在?
- 拿到系统结构图,分析出架构的数据流向
- 根据系统架构画出业务请求的数据流图
- 根据数据流画出流程节点中可能存在的问题节点以及出现问题的可能性:易出现问题的9点
- 通过依次监控数据,排查以上问题是否存在
- 如果排查了节点,改了还有问题,重复第4步
- 可以通过经验做一些小的手段帮助自己快速排查问题

这里单单拎出第6点分析
有可能存在问题的点(紫色):负载机性能瓶颈,网络带宽,硬件资源,线程池/进程池,数据库连接池,代码逻辑,SQL执行效率,数据库本身连接池, JVM---9点
排查,从我们能拿到数据的地方去先排查,由简至难。
关于代码,让开发加日志。业务里面可以加日志,帮助定位业务问题。性能里面加日志,帮我们定位性能消耗在哪个时间。那怎么加呢?在web服务器上打印出时间戳
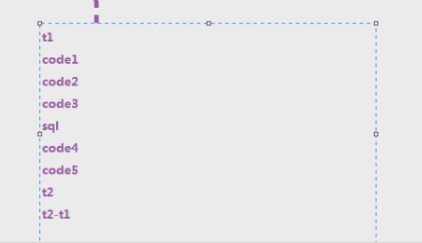
t4-t3是sql的执行时间