一、日常命令



- shutdown -h now ##立刻关机
- shutdown -h +10 ##10min以后关机
- shutdown -h 12:00:00 #12点整的时候关机
- halt ##等于立刻关机
- shutdown -r now
- reboot #等于立刻重启
- ctrl+z ##进程hi挂起在后台
- bg jonid ##让进程在后台继续执行(jobid为运行程序的id)
- fg jonid ##让进程回到前台(jobid为运行程序的id)
二、目录操作
|
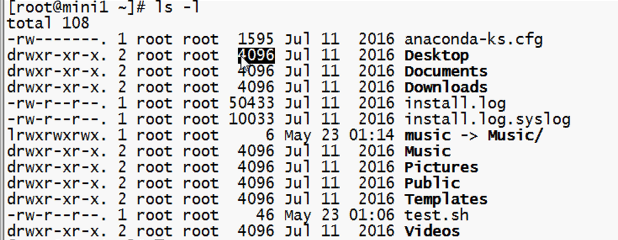
ls /
|
查看根目录下的子节点(文件夹和文件)信息
|
|
ls .
|
查看当前目录下信息
|
|
ls ../
|
查看上一级的目录信息
|
|
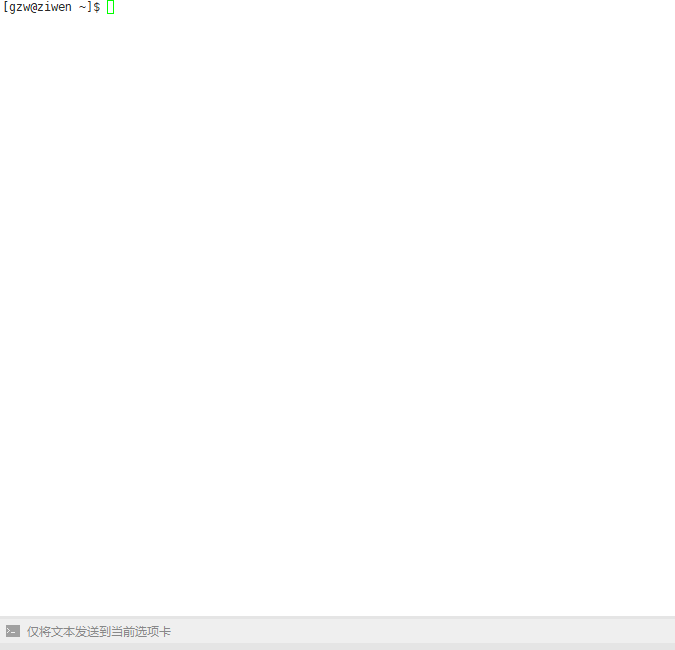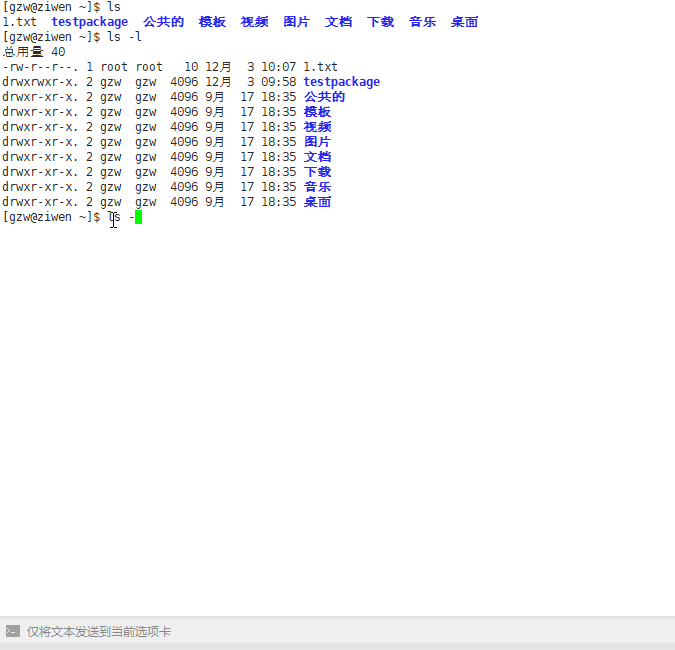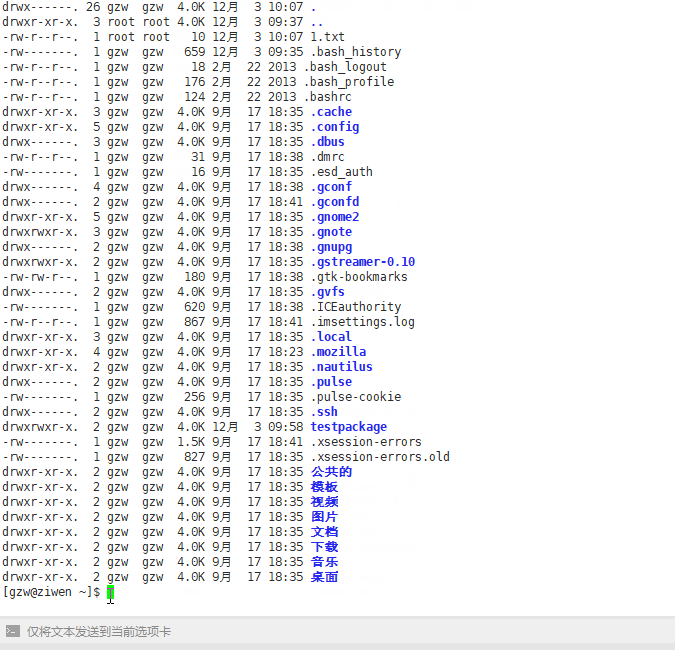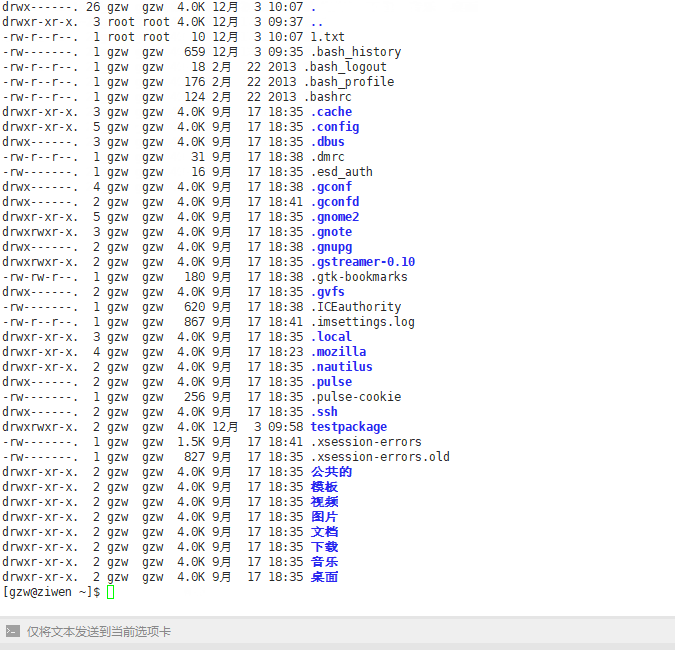
ls -l .
|
列出当前目录下文件的详细信息
|
|
ls -l
|
列出当前目录下文件的详细信息
|
|
ls -al
|
-a是显示隐藏文件 -l是以更详细的列表形式显示
|
|
ls -l -h
|
列出的文件大小会以K显示,而不是字节
|
总结(ls --help可以查看参数的写法):
ls . 和 ls其实一样
ls就是显示文件夹和可显示的文件名称
ls -l 会显示文件夹以及可显示文件的大小以及权限等
ls -al 就是在上一步之上加了一个显示隐藏的文件
ls -alh 就是在上一步的基础之上,将文件大小以Kb形式显示,更加直观
- cd /home/gzw ## 切换到用户的主目录(/home/用户名)
- cd ~ ## 切换到用户主目录(/home/用户名)
- cd ## 切换到用户的主目录(/home/用户名)
- cd - ## 切换到上一步的目录
- mkdir /aaa ## 这是绝对路径的写法的写法,在根目录下建立一个aaa
- mkdir /aaa/bbb ## 这是在aaa文件夹内新建一个bbb文件夹
- mkdir aaa ## 这是相对路径的写法
- mkdir -p aaa/bb/ccc ##假设aaa,bbb都不存在,就去建立ccc,前面加-p,会同时将aaa,bbb,ccc建立起来,遵循刚刚写的结构
- rmdir aaa ## 只能删除空白的目录
- rm -r aaa ## 可以将aaa整个文件夹和子节点全部删除,包括aaa
- rm -rf aaa ## 强制删除 aaa
- mv aaa angelababy ##将aaa文件夹移动到 angelababy文件夹内
- mv 本质上是移动
- mv install.log aaa/ ## 将当前目录下的install.log 移动到aaa文件夹中去
- mv install.log aaa/ notinstall.log ## 将instal.log移动到aaa下,且改名为notinstall.log
- mv a b/c ##将文件夹a移动到文件夹b内并且将文件夹a的名字改为c
- mv mubby/ mybaby ## 将mubaby改名为mybany
三、文件操作
一、创建文件
二、vi文本编辑器
- 首先会进入“一般模式”,此模式只接受各种命令快捷键,不能编辑文件内容
- 首先按“i”键,就会从一般模式进入编辑模式,此模式下,敲入的都是文件内容(这里按i键,可以在光标定位的位置输入,进行插入;按a,会在光标所在位置的后一个字符善后进行操作;按o,会在光标所在位置下面重新插入一个新的空白行,且光标在该行的第一个上)
- 编辑完成之后,按Esc退出编辑模式,回到一般模式
- 再按:进入的“底行命令模式”,输入wq命令,回车即可,这样是保存且退出;按w,就是保存;但是还是在一般模式下,还可以按i进行编辑
|
a
|
在光标的最后一位插入
|
|
A
|
在该行的最后插入
|
|
I
|
在该行的最前面插入
|
|
gg
|
直接跳到文件的首行
|
|
G
|
直接跳到文件的末行
|
|
dd
|
删除一行
|
|
3dd
|
删除3行
|
|
YY
|
复制一行
|
|
3YY
|
复制3行
|
|
p
|
粘贴
|
|
u
|
undo回退
|
三、查找并替换
四、拷贝、删除、移动
- cp somefile.1 /home/gzw ##复制一个文件到指定的目录下
- cp somefile.2 /home/gzw/somefile2.1 ##复制一个文件到gzw下,并且命名为somefile2.1
- rm /home/gzw/somefile.1 ##删除somfile.1(会提示确定删除,要输入y)
- fm -f/home/gzw/somefile.1
- mv /home/gzw/somefile.1 ../
五、查看文件内容
cat somefile.1 ## 一次性将文件内容全部输出(输出在控制台)
分页查看命令:
- more somefile.1 ## 将somefile.1输出在控制台,但是可以翻页查看,下一页按空格键,上一页按b(代表back),退出按(q)
- less somefile.1 ## 将somefile.1输出在控制台,但是可以翻页查看,下一页按空格键,上一页按b(代表back),上翻一行(↑),下翻一行(↓),且可以搜索关键字(/搜索内容)
跳到文件末尾:G
跳到文件首行:gg
退出less:q
六、查看日志
- tail -10 install.log ##查看文件尾部的10行
- tail +10 install.log ##查看文件第10-->最后一行
- tail -f install.log ##实时看日志的输出,追踪日志文件的信息(f追踪的是文件的唯一标识,就算文件被改了名字,也可以被追踪并输出,也就是说,将install.log改为install2.log,用这么命令依旧可以追踪到内容ll -i可以看文件的唯一标识,在文件的最前面那串)
- tail -F install.log ##实时看日志的输出,追踪日志文件的信息(F追踪的是文件名,改了就追踪不了)
- head -10 install.log ##查看文件的头10行
七、打包压缩
四、查找命令
一、常用查找命令的使用
二、grep命令(搜索文件的内容)
五、文件权限操作
- chmod 777 1.txt ##将1.txt变为rwxrwxrwx
- chmod +x 1.txt ##拥有者、所属用户、其他用户都加一个x权限
- chmod u+rx 1.txt ##拥有者加rx权限,其他的用户不变
- chmod g+rx 1.txt ##所属用户组加rx权限,其他的用户不变
- chmod o+rx 1.txt ##其他用户加rx权限,其他的用户不变
- chmod -x 1.txt ##所有人减去一个x权限
六、用户管理
需要掌握的:
添加一个用户:
- useradd spark
- passwd spark 根据提示设置密码即可
删除一个用户:
- userdel -r spark 加一个-r就表示将用户的主目录都删除
1、添加用户
添加一个tom用户,设置其属于 user 组,并添加注释信息:
分步完成过程如下:
useradd tom
usermod -g user tom
usermod -c "hr tom" tom
一步完成:
useradd -g user -c "hr tom" tom
设置tom密码:
passwd tom
2、修改用户
修改tom用户的登录名字为tomcat
usermod -l tomcat tom
将tomcat添加到sys和root组中
usermod -G sys,root tomcat
查看tomcat 的组信息
groups tomcat
3、用户组操作
添加一个叫america的组
groupadd america
将 jerry 添加到 america 组中
usermod -g america jerry
将tomcat用户从root组和sys组删除
gpasswd -d tomcat root
gpasswd -d tomcat sys
将 america 组名修改成 am
groupmod -n am america
4、为用户配置 sudo 权限
这是为了个普通用户一个管理员的权限
用 root 编辑 vi/etc/sudoers
在文件的如下位置,为 gzw 添加一行即可:
rooot ALL=(ALL) ALL
gzw ALL=(ALL) ALL
然后,gzw用户就可以用 sudo 来执行系统级别的命令
比如: sudo usersdd mayun
这行命令执行完,下一行如果不用sudo,还是依旧本身的权限
七、系统管理操作
一、挂载外部存储设备
比如说插入一个光盘,光盘里面有一个Oracle,或者说是一个镜像,我们在Linux里面是显示为一个设备,而不是文件;那我们如果要访问里面的文件,就要把它映射到文件目录,就叫做挂载
可以挂载什么呢?光盘、硬盘、磁带、光盘镜像文件等
1、挂载光驱
mkdir /mnt/cdrom 创建一个目录,用来挂载
mont -t iso9660 -o ro/dev/cdrom/mnt/cdrom/ 将设备/dev/cdrom挂载到挂载点:/mnt/cdrom 中
2、挂载光盘镜像文件(.iso文件)
mont -t iso9660 -o loop /home/gzw/Centos-6.7.DVD.iso /mnt/centos
注:挂载的资源在重启后即失效,需要重新挂载。想要自动挂载,可以将挂载信息设置到 /etc/fstab 配置文件中:
/dev/cdrom /mnt/cdrom iso9660 defaults 00
/root/CentOS-6.7-x86_64-bin-DVD1.iso /mnt/centos iso9660 defaults,ro,loop 00
3、卸载 umont
umont /mnt/cdrom
4、存储空间查看
df -h
二、统计文件以及文件夹的大小
1、du -sh /mnt/cdrom/packages
统计指定路径下的所有子目录和文件的大小
2、df -h
查看磁盘的空间
三、系统服务管理
service --status-all ##查看系统所有的后台服务进程
后面可以接管道:
service --status-all | grep httpd
servoce sshd status ##查看指定的后台服务进程的状态
service sshd stop
service sshd start
service sshd restart
配置后台服务进程的开机自启
chkconfig httpd on ##让httpd 服务开机自启
chkconfig httpd off ##让httpd 服务开机不要自启
查看开机自启服务的命令:
chkconfig --list | grep httpd
截图:

那么这几个你姐是什么意思呢?往下看
四、系统启动级别管理
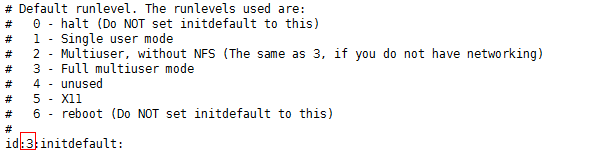
vi /etc/inittab
可以看到有以下几个级别
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this) ##关机,级别如果设置这个,那么一启动就会关机
# 1 - Single user mode ##单用户模式
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking) ##多用户系统,不支持网络文件系统
# 3 - Full multiuser mode ##全功能的多用户模式
# 4 - unused
# 5 - X11 ##带图形界面的全功能模式,比3多了个图形界面
# 6 - reboot (Do NOT set initdefault to this) ##重启
究竟要哪个级别,在这里填id就好了:一般来讲设置为3就ok
那么如果一个服务:
chkconfig httpd off
那么这个服务0-6都会被关闭
chkconfig --level35 httpd on
意味着,我这个服务在3,5的开机情况下可以自启
五、进程管理
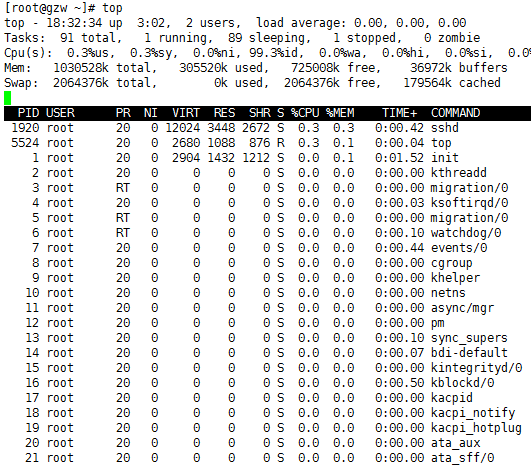
top
相当于Windows的任务管理器,是动态变化的:
free
显示内存的使用量,你发送的的那一瞬间的内存量

ps -ef | grep ssh 查看现在运行的跟ssh有关的进程
进程号 父进程号 启动的命令,哪个程序启动的

那如果我要把进程给杀掉,怎么做?
kill -9 1532 (1532为进程号,例如上边的第一个进程)
八、SSH免密登陆配置
一、SSH工作机制
1、相关概念
SSH为 Secure Shell(安全外壳协议)的缩写,是一种协议。网络远程访问Linux,敲Shell命令,提供安全协议,提供协议,本质上是为了会话内容加密和身份验证。
SSH的具体实现是由客户端和服务器的软件组成
服务端是一个守护进程(sshd),他在后台运行并响应来自客户端的连接请求;客户端包含ssh程序以及像scp(远程拷贝)、slogin(远程登录)、sftp(安全文件传输)等其他的应用程序。
2、认证机制
从客户端来看,SSH提供两种级别的安全验证
(一)基于口令的安全验证
只要你知道自己的账号和口令,就可以登录到远程主机(就像用xshll登录)
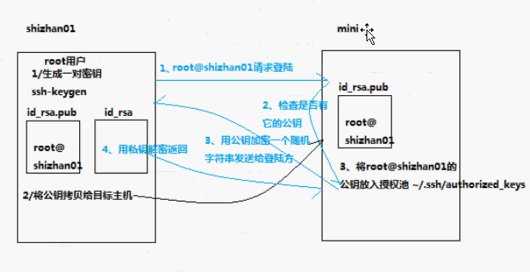
(二)基于密钥的安全验证(一台Linux登录另一台Linux,因为Linux上没有XShell)
需要依靠密钥,也就是你必须自己创建一堆密钥,并且把公用密钥放在需要访问的服务器上
假如A要登录B,


九、网络管理
一、主机名配置
1、查看主机名
hostname
2、改主机名
hostname gzw01 ##将主机名改成gzw01,重启后失效(重新登录可以查看)
3、永久改主机名
vi /etc/sysconfig/network 找到HOSTNAME,改掉值,就ok了
二、IP地址配置
1、setup(并不是所有的版本可用)
用root输入setup命令,进入交互修改界面
2、修改配置文件(重启后永久生效)
vi /etc/sysconfig/network-scripts/ifconfig-eth0
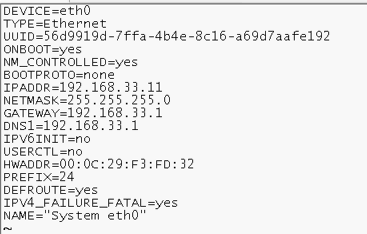
改完之后,要重启网络服务:
service network restart
3、ifconfig 命令(重启后无效)
ifconfig eth0 192.168.10.42
三、域名映射
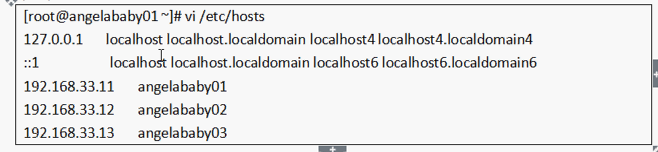
etc/hosts 文件(域名映射表) 用于在通过主机名访问时做ip解析之用。所以,你想访问一个什么样的主机名,就需要把这个主机名和它对应的ip地址配置在 etc/hosts 文件中
四、网络服务管理
1、后台服务管理
- service network status ##查看指定服务的状态
- service network stop ##停止指定服务
- service network start ##启动指定服务
- service network restart ##重启指定服务
- service --status-all ##查看系统中所有的后台服务
2、设置后台服务的自启配置
- chconfig ##查看所有服务器自启配置
- chkconfig iptables off ##关掉指定服务的自启动
- chkconfig iptables on ##开启指定服务的自启动
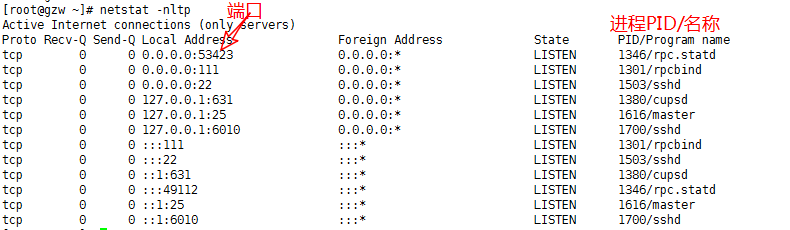
3、系统中网络进程的端口监听情况:
netstat -nltp
十、Linux上常用软件安装
一、Linux软件安装方式
常用以下几种方式:
1、二进制发布包
软件已经针对具体平台编译打包,只要解压,修改配置即可
2、RPM发布包(Redhat Package Mangement)
软件已经按照rehat的包管理工具规范RPM进行打包发布,需要获取到相应的软件RPM发布包,然后用RPM命令安装
3、Yum在线安装
软件已经以RPM规范打包,但已经发布在了网络上的一些服务器上,可用 yum 在线安装服务器上存在的 rpm 软件,并且会自动解决软件安装过程中的库依赖问题(类似maven
)
4、源码编译安装
软件以源码工程的形式发布,需要获取到源码工程后用相应的人开发工具进行编译打包部署
二、JAVA软件安装——JDK安装
1、上传jdk压缩包
通过sftp工具上传即可
2、解压jdk压缩包
tar -zxvf jdk-XXX.gz -C /usr/local/
3、修改环境变量PATH
vi /etc/profile
在文件最末尾(按G)加两行:
export JAVA_HOME=/usr/local/jdk1.7
export PATH=$PATH:$JAVA_HOME/bin
4、让环境变量生效
source /etc/profile
即可
三、JAVA软件安装——Tomcat安装
tar -zxvf /soft/apache-tomcat-7.0.47.tar.gz -C /usr/local/
cd /usr/local/apache-tomcat-7.0.47/bin/
./starttup.sh
四、使用rpm软件安装方式
1、安装Mysql服务端:
可以用 yum 来安装,这里我们用 rpm 包来演示:
2、安装Mysql客户端:
五、使用yum方式安装
六、使用源码方式安装
十一、防火墙的规则配置
一、防火墙配置
防火墙配置文件为
/etc/sysconfig/iptables
来控制本机的出、入网络访问行为
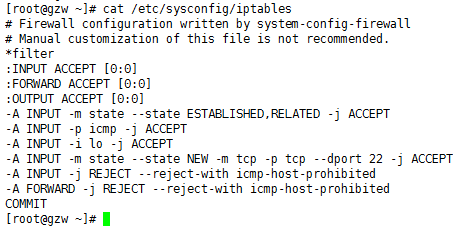
二、防火墙配置
查看防火墙状态
service iptables status
关闭防火墙
service iptables stop
启动防火墙
service iptables start
禁止防火墙自启
chkconfig iptables off
保存配置
service iptables save
禁止ssh登录
iptables -A INPUT -p tcp --dport 22 -j DROP
加入一条 INPUT 规则开放 80端口
iptables -I INPUT -p tcp --dport 80 -j ACCEPT
十二、高级文本处理命令(无需打开文本进行编辑)
- cut
概念:cut 命令可以从一个文本文件或者文本流中提取文本列
语法:
- cut -d '分隔字符' -f fields ##用于有特定分隔字符
- cut -c 字符区间 ##用于排列整齐的信息
选项和参数:
- -d:后面接分隔符。与 -f 一起使用;
- -f :依据 -d 的分隔字符将一段信息分割成数段,用 -f 取出第几段的意思;
- -c : 以字符 (characters) 的单位取出固定字符区间
实例:
PATH变量如下:
# echo $PATH /usr/lib/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/jdk1.8.0_131/bin:/usr/local/jdk1.8.0_131/jre/bin:/usr/local/apache-jmeter-5.0/bin/:/root/bin
这里我们可以发现,各个路径之间是用 : 分隔路径的,那么我们可以利用 cut 命令去将其分隔开,假如我想提取第 2 个路径,那么应该输入如下:
# echo $PATH /usr/lib/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/jdk1.8.0_131/bin:/usr/local/jdk1.8.0_131/jre/bin:/usr/local/apache-jmeter-5.0/bin/:/root/bin
# echo $PATH | cut -d ':' -f 2 ##提取第 2 个路径 /usr/local/sbin
# echo $PATH | cut -d ':' -f 2,4 ##提取第 2 和第 4 个路径
/usr/local/sbin:/sbin
# echo $PATH | cut -d ':' -f 2- ##提取第 2 个,直至最后一个路径
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/jdk1.8.0_131/bin:/usr/local/jdk1.8.0_131/jre/bin:/usr/local/apache-jmeter-5.0/bin/:/root/bin
# echo $PATH | cut -d ':' -f -2 ##提取第 1 到第 2 个
/usr/lib/qt-3.3/bin:/usr/local/sbin
# echo $PATH | cut -d ':' -f 1-3,5 ##提取 1-3 以及第 5 个
/usr/lib/qt-3.3/bin:/usr/local/sbin:/usr/local/bin:/bin
以上,就是 cut 的常用方法,可以理解并掌握一下
- sed(并不会保存文本,需要保存自行重定向)
用法:先新建一个 文本文件 ,随便编辑些内容进去
# cat example 1: fjpqejfpjewjfwejvjqwjev 2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f 3:mowedfwelfw ff] f]jf] 4:cnioecewcw owe ioqwe hfoqweh foweh fiupqw huipq ui uipqe ui ruipq 5:fwecv iefvqw
删除:d 命令 (delete)
# sed '2d' example ##删除 example 文件的第 2 行 1: fjpqejfpjewjfwejvjqwjev 3:mowedfwelfw ff] f]jf] 4:cnioecewcw owe ioqwe hfoqweh foweh fiupqw huipq ui uipqe ui ruipq 5:fwecv iefvqw
# sed '2,$d' example ##删除 example 文件的第 2 行到末尾的所有行(保留第 1 行)
1: fjpqejfpjewjfwejvjqwjev
# sed '$d' example ##删除 example 文件的最后一行
1: fjpqejfpjewjfwejvjqwjev
2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f
3:mowedfwelfw ff] f]jf]
4:cnioecewcw owe ioqwe hfoqweh foweh fiupqw huipq ui uipqe ui ruipq
# sed '/4/'d example ##删除 example 文件所有包含 ‘4’ 的行
1: fjpqejfpjewjfwejvjqwjev
2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f
3:mowedfwelfw ff] f]jf]
5:fwecv iefvqw
替换:s 命令(substitution)
# sed 's/2/change2/g' example ##在整行范围内将 ‘2’ 替换成 ‘change2’ 。如果无 g 标记,则只有每行第一个匹配的 ‘2’ 被替换 1: fjpqejfpjewjfwejvjqwjev change2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f 3:mowedfwelfw ff] f]jf] 4:cnioecewcw owe ioqwe hfoqweh foweh fiupqw huipq ui uipqe ui ruipq 5:fwecv iefvqw
# sed -n 's/^2/change2/p' example ##(-n)选项和 p 标志一起使用表示只打印那些发生替换的行。也就是以 ‘2’ 为开头的行,被替换成 ‘change2’,并打印这一行
change2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f
# sed 's/^1/&number one/' example ## & 符号表示在找到的字符串后追加一个字符串,比如在所有的以 ‘1’ 为首的字符串中,在 ‘1’ 后追加 ‘number one’ ,变成 ‘1number one’
1number one: fjpqejfpjewjfwejvjqwjev
2: djoiqjdowjodfwejocpf,vf,vf v]qfkv]qwefkqwjfe vqfjvnqwojnfqwjnc[f
3:mowedfwelfw ff] f]jf]
4:cnioecewcw owe ioqwe hfoqweh foweh fiupqw huipq ui uipqe ui ruipq
5:fwecv iefvqw
# sed -n 's/(fwe)cv/1changechange/p' example ##将文本中的 ‘fwe’ 标记为 1 ,并将所有的 ‘fwecv’ 替换成‘fwechangechange’,并且被替换的行被打印出来
5:fwechangechange iefvqw
……
- awk
说明:awk 是一个强大的文本你分析工具,相对于 grep 的查找,sed 的编辑,awk 在其对数据分析并生成报告时,显得尤为强大。简单来讲 awk 就是把文件逐行地读入,以空格为分隔符将每行切片,切开的那部分再进行各种分析处理
工作流程:读入有 ‘ ’ 换行符分割的一条记录,然后将记录按照指定的域分隔符划分域,填充域,$0 则表示所有域,$1 表示第一个域,$n表示第 n 个域。默认域分割符是 ‘空白键’ 或者 ‘[tab]键’ ,所以 $1 表示登录用户,$3 则表示用户 ip ,以此类推
# last -n 5 ##最近登录的 5 个账户的信息 root pts/2 192.168.66.1 Sat Dec 29 21:58 still logged in root pts/1 192.168.66.1 Sat Dec 29 18:28 still logged in root pts/0 192.168.66.1 Sat Dec 29 18:28 still logged in reboot system boot 2.6.32-358.el6.i Sat Dec 29 18:11 - 23:32 (05:21) root pts/1 192.168.66.1 Sat Dec 29 14:29 - down (03:41)
# last -n 5 | awk '{print $1}' ##只显示最近登录的 5 个账号,不需要要其他信息
root
root
root
reboot
root
# cat /etc/passwd|awk -F ':' '{print $1}' ##如果只显示 /etc/passwd/ 的账户;这里用 -F ‘:’ 表示将 ‘:’ 作为分隔符,然后取第一个域
root
bin
daemon
adm
lp
sync
……
# cat /etc/passwd|awk -F ':' '{print $1" "$7}' ##显示 /etc/passwd 的账户和对应的 shell,而账户与 shell 之间用 tab 键分隔
root /bin/bash
bin /sbin/nologin
daemon /sbin/nologin
adm /sbin/nologin
lp /sbin/nologin
sync /bin/sync
……
# cat /etc/passwd|awk -F ':' '{print $1"==="$7}' ##或者自己指定分隔符
root===/bin/bash
bin===/sbin/nologin
daemon===/sbin/nologin
adm===/sbin/nologin
lp===/sbin/nologin
sync===/bin/sync
……
# cat /etc/passwd|awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print"blue,/bin/nosh"}' ##显示 /etc/passwd 的账户以及对应的shell,用‘,’分隔,第一行加‘name,shell’,最后一行加‘blue,/bin/nosh’
name,shell
root,/bin/bash
bin,/sbin/nologin
daemon,/sbin/nologin
adm,/sbin/nologin
lp,/sbin/nologin
sync,/bin/sync
……
blue,/bin/nosh
十三、crontab配置
功能:通过 crontab 功能,可以在固定的间隔时间执行指定的系统指令或 shell script 脚本。时间间隔的单位可以是分钟、小时、日、月、周、及以上的任意组合。这个命令非常适合周期性的日志分析或者数据备份等工作。定时调度器
安装:
yum install crontabs
服务操作说明:
- service crond start ##启动服务
- service crond stop ##关闭服务
- service crond restart ##重启服务
- service crond reload ##重新载入配置
- service crond status ##查看 crontab 服务状态
- chkconfig --level 35 crond on ##加入开机自启动
命令格式:
crontab [-u user] file
crontab [-u user] [-e | -l -r]
参数说明:
- -u user :用来设定某个用户的 crontab 服务,例如:“ -u gzw ” 表示设定 gzw 用户 的 crontab 服务,此参数一般由 root 用户来运行,-u 如果不指定,默认就是帮本用户指定任务;
- file :file 是指命令文件的名字,表示将 file 作为 crontab 的任务列表文件并载入 crontab;
- -e :编辑某个用户的 crontab 文件内容,如果不指定用户,则表示编辑当前用户的 crontab 文件内容;
- -l : 显示某个用户的 crontab 文件内容,如果不指定用户,则表示显示当前用户的 crontab文件内容;
- -r : 删除定时任务配置,从 /var/spool/cron 目录中删除某个用户的 crontab 文件,如果不指定用户,则默认删除当前用户的 crontab 文件;
- -i : 在删除用户的 crontab 文件时给确认提示
命令实例:
crotab file [-u user] ##用指定的文件替代目前的 crontab
必须掌握:
- crontab -l [-u user] ##列出用户目前的 crontab
- crontab -e[-u user] ##编辑用户目前的 crontab
# crontab -l ##看当前用户有没有定时任务 no crontab for root
# crontab -e ##增加个定时任务,里面填入以下内容,保存
* * * * * date >> /root/date.txt
# crontab -l ##保存完之后,可进行查看
* * * * * date >> /root/date.txt
# cat date.txt ##可以看到结果,每分钟,文件内被追加写了一行 date
Sun Dec 30 00:47:01 CST 2018
Sun Dec 30 00:48:01 CST 2018
Sun Dec 30 00:48:01 CST 2018
Sun Dec 30 00:49:01 CST 2018
Sun Dec 30 00:49:01 CST 2018
调度配置
说明
格式如下:
* * * * * command
分 时 日 月 周 命令
第 1 列表示分钟 1-59 每分钟用 * 或者 */1 表示
第 2 列表示小时 0-23 (0表示 0点)7-9表示:8点到10点之间
第 3 列表示日期 1-31
第 4 列表示月份 1-12
第 5 列表示星期 0-6(0表示星期天)
第 6 列表示要运行的命令
配置实例
30 21 * * * /usr/local/etc/rc.d/httpd restart ## 表示每晚的 21:30 自动重启 apache
45 4 1,10,22 * * /usr/local/etc/rc.d/httpd restart ## 表示每月 1、10、22 日的 4:45 重启 apache
10 1 * * 6,0 /usr/local/etc/rc.d/httpd restart ## 表示每周六、日的 1:10 重启 apache
0,30 18-23 * * * /usr/local/etc/rc.d/httpd restart ## 表示在每天 18:00 至 23:00 之间每隔 30 分钟重启 apache
0 23 * * 6 /usr/local/etc/rc.d/httpd restart ## 表示每周六的 11:00 pm 重启 apache
* */1 * * * /usr/local/etc/rc.d/httpd restart ## 表示每 1 小时重启 apache
* 23-7/1 * * * /usr/local/etc/rc.d/httpd restart ## 表示晚上 11 点 到早上 7 点之间,每隔 1 小时重启 apache
0 4 1 jan * /usr/local/etc/rc.d/httpd restart ## 表示一月一号的 4 点重启 apache
shell编程
shell 是用户与内核进行交互的一种接口,目前最流行的 shell 称为 bash shell
shell 也是一门编程语言<解释型的编程语言>,即 shell 脚本,就是在用 linux 的 shell 命令编程
一个系统可以存在多个 shell ,可以通过 cat/etc/shell 命令查看系统中安装的 shell ,不同的 shell 可能支持的命令语法是不同的
一、基本格式
代码写在普通文本文件中,通常以 .sh 为后缀名
vi hello.sh
#!/bin/bash ##表示用哪一种 shell 解析器解析执行我们的这个脚本程序 echo "hello world"
执行脚本
sh hello.sh 为什么这里加 sh 不加路径可以运行?因为 sh 在环境变量内,不加路径就默认当前路径
或者给脚本添加 x 权限,直接执行
chmod 755 hello.sh
# ./hello.sh ##这里为啥要加 ./ ? 运行程序,系统都是从环境变量里面去找,很显然这个脚本的路径并不在环境变量内 ./ 已经指定在当前路径下
hello world
二、基本语法
-
系统变量
Linux shell 中的变量分为“系统变量”和“用户自定义变量”,可通过 set 命令查看系统变量
# set BASH=/bin/bash BASHOPTS=checkwinsize:cmdhist:expand_aliases:extquote:force_fignore:hostcomplete:interactive_comments:login_shell:progcomp:promptvars:sourcepath BASH_ALIASES=() BASH_ARGC=() BASH_ARGV=() BASH_CMDS=() BASH_LINENO=() BASH_SOURCE=() BASH_VERSINFO=([0]="4" [1]="1" [2]="2" [3]="2" [4]="release" [5]="x86_64-redhat-linux-gnu") BASH_VERSION='4.1.2(2)-release' COLORS=/etc/DIR_COLORS ……
系统变量:$BASH、$HOME、$PWD、$SHELL、$USER 等等
-
自定义变量
自定义的变量只能在当前进程生效,不能跨进程传递自定义变量
1、语法
变量=值 (例如 STR=abc)
等号两侧不能有空格
变量名称一般习惯大写
使用变量: $arg
双引号和单引号有区别,双引号仅仅将空格脱意,单引号会将变量引用也脱意
# mygirl1=angela baby ##中间有空格,linux 会认为是两个参数,所以要加引号 -bash: baby: command not found
# mygirl1='angela baby'
# echo $mygirl1
angela baby
# mygirl2="she is $mygirl1" ##将里面的变量也打印出其值
# echo $mygirl2
she is angela baby
# mygirl2='she is $mygirl1' ##里面的变量,只会按原样打印出来
# echo $mygirl2
she is $mygirl1
2、示例
STR="hello world"
A=9
echo $A
echo $STR
如果想打印 hello worlds is greate 怎么办?
echo $STR is greate 行么?
不行!正确的写法是:
echo ${STR}s is greate
# mycount=2000 # echo $mycount 2000 ##如果想打印 2000 is mycount 要这样写: # echo $mycount is mycount 2000 is mycount 或者: # echo ${mycount} is mycount 2000 is mycoun ##如果要打印 2000s is mycount 怎么写?
# echo $mycounts is mycount
is mycount
这样写,linux会认为 mycounts 是一个变量,但这个变量并没有定义,所以为空,正确的写法如下:
# echo ${mycount}s is mycount 2000s is mycount
unset A 撤销变量 A
redonly B=2 声明静态的变量 B=2 ,不能 unset
export A 将变量提升为当前 shell 进程中的全局环境变量,可供其他子 shell 程序使用
注意理解 export:
#vi a.sh
#!/bin/bash A=aaaa echo "in a.sh---"$A sh b.sh
#vi b.sh
#!/bin/bash
echo "in b.sh---"$A
上面的意思:我们在 a.sh 定义了一个变量 A ,并且打印 A,执行 b.sh;在 b.sh 里面是打印变量 A 的值 ,我们先把 a.sh 和 b.sh 赋予可执行权限,再分别执行下,看能不能得到正确结果:
# chmod +x a.sh b.sh # ./a.sh ## b.sh 没有结果 in a.sh---aaaa in b.sh--- # ./b.sh ## b.sh 没有结果 in b.sh---
# echo $A ## 没有结果
这是为什么呢?我们画个简单的图来理解一下:我们登录会话有一个进程,里面我们去调用个 a.sh 子进程,a.sh 进程里面去调用个 b.sh 子进程,这三个进程内的变量是不共用的,所以,我们在 登录会话中直接
打印 $A 的值,是不会出现的;同样的,我们在 b.sh 里面想去 echo $A 也是无法打印出来的
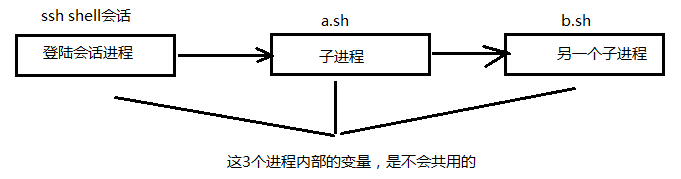
那么,怎么才能解决呢?答案是把 A 这个变量作为全局变量就 ok ,那么在当前进程 ,以及其子进程 ,就能用这个变量了,
#vi a.sh #!/bin/bash exoprt A=aaaa echo "in a.sh---"$A sh b.sh
b.sh 就不用管,我们再打印下:这里可以发现,b.sh 已经取到了 a.sh 内的变量
# ./a.sh in a.sh---aaaa in b.sh---aaaa
另一种方式:source
#!/bin/bash A=aaaa echo "in a.sh---"$A source /root/b.sh ##这里改成 b.sh 的绝对路径
看一下,a.sh 的结果:之前我们改过 /etc/profile 里面的环境变量 ,我们要 source 一下 profile ,source 是干嘛的?source 的功能在调用脚本,可以将 b.sh 在 a.sh 的进程空间内运行,而不是另外开一个进程
# ./a.sh in a.sh---aaaa in b.sh---aaaa
另一种方式:用 '.' 代表source ,后面的 '.' 代表本地,可以改成:. /root/b.sh
#!/bin/bash A=aaaa echo "in a.sh---"$A . ./b.sh
结果:
# ./a.sh in a.sh---aaaa in b.sh---aaaa
总结:
- a.sh 中直接调用 b.sh ,会让 b.sh 在 a 所在的 bash 进程的“子进程”空间中执行;
- 而子进程空间只能访问父进程中用 export 定义的变量;
- 一个 shell 进程无法将自己定义的变量提升到父进程空间中去;
- "."号执行脚本时,会让脚本在调用者所在的 shell 进程空间中执行
3、反引号赋值
A=`ls -la` ## 反引号,运行里面的命令,并将结果返回给变量 A(在esc下面那个键,在英文状态下输入)
A=$(ls -la) ## 等价于反引号
# a=`ls -la` # echo $a total 844 drwxr-xr-x 2 root root 4096 Jan 3 20:51 . drwxr-xr-x 9 root root 4096 Jan 3 14:37 .. -rw-r--r-- 1 root root 28857 Nov 9 19:09 bootstrap.jar -rw-r--r-- 1 root root 14867 Nov 9 19:09 catalina.bat -rwxr-xr-x 1 root root 22785 Jan 3 20:51 catalina.sh -rw-r--r-- 1 root root 1647 Nov 9 19:09 catalina-tasks.xml -rw-r--r-- 1 root root 25145 Nov 9 19:09 commons-daemon.jar -rw-r--r-- 1 root root 207125 Nov 9 19:09 commons-daemon-native.tar.gz -rw-r--r-- 1 root root 2040 Nov 9 19:09 configtest.bat -rwxr-xr-x 1 root root 1922 Nov 9 19:09 configtest.sh -rwxr-xr-x 1 root root 8508 Nov 9 19:09 daemon.sh -rw-r--r-- 1 root root 2091 Nov 9 19:09 digest.bat -rwxr-xr-x 1 root root 1965 Nov 9 19:09 digest.sh -rw-r--r-- 1 root root 3460 Nov 9 19:09 setclasspath.bat -rwxr-xr-x 1 root root 3680 Nov 9 19:09 setclasspath.sh -rw-r--r-- 1 root root 2020 Nov 9 19:09 shutdown.bat -rwxr-xr-x 1 root root 1902 Nov 9 19:09 shutdown.sh -rw-r--r-- 1 root root 2022 Nov 9 19:09 startup.bat -rwxr-xr-x 1 root root 1904 Nov 9 19:09 startup.sh -rw-r--r-- 1 root root 45466 Nov 9 19:09 tomcat-juli.jar -rw-r--r-- 1 root root 411789 Nov 9 19:09 tomcat-native.tar.gz -rw-r--r-- 1 root root 4550 Nov 9 19:09 tool-wrapper.bat -rwxr-xr-x 1 root root 5458 Nov 9 19:09 tool-wrapper.sh -rw-r--r-- 1 root root 2026 Nov 9 19:09 version.bat -rwxr-xr-x 1 root root 1908 Nov 9 19:09 version.sh
# a=`date +%Y-%m-%d`
# echo $a
2019-01-03
4、特殊变量
$? ## 表示上一个命令退出的状态
$$ ## 表示当前进程编号
$0 ##表示当前脚本名称
$n ##表示 n 位置的输入参数( n 代表数字,n >= 1)-----相当于传参
$# ##表示参数的个数,常用于循环
$* 和 $@ ##都表示参数列表
注:$* 和 $@ 的区别:
$* 和 $@ 都表示传递给函数或脚本的所有参数
- 不被双引号 " " 包含时
$* 和 $@ 都以 $1 $2……$n 的形式组成参数列表
- 当它们被双引号 " " 包含时
"$*" 会将所有的参数作为一个整体,以"$1 $2 …… $n" 的形式输出所有参数;
"$@" 会将各个参数分开,以 "$1" "$2"……"$n" 的形式输出所有参数
# echo $$ 14689 # echo $? 0
编辑 a.sh
#vi a.sh
#!/bin/bash
echo they are:
echo $1 $2 $3
结果:
# sh a.sh
they are:
#我们输入参数看看:
# sh a.sh liuyifei yangyin reba
they are:
liuyifei yangyin reba
三、运算符
一、算数运算1、用 expr
格式: expr m + n 或 $((m+n)) 注意 expr 运算符间要有空格
例如:计算 (2+3)*4 的值
1、分步计算
S=`expr 2 + 3` ## expr是接收运算符用的 ,` 是取出表达式的运算结果
expr $S * 4 ## * 号需要转义
2、一步计算完成
expr `expr 2 + 3` * 4
echo `expr \`expr 2 + 3\` * 4`
#分步计算 # S=`expr 2 + 3` # expr $S * 4
20
#一步计算完成
# expr `expr 2 + 3` * 4
20
# echo `expr \`expr 2 + 3\` * 4`
20
2、用(())——要取出运算结果
要取值需加 $ 符号,否则会报错;运算符间无需加空格
# a=$((1+2)) # echo $a 3
# a=$(((2+3)*4))
# echo $a
20
# count=1
# ((count++))
# echo $count
2
3、用[]
# a=$[1+2] # echo $a 3
四、流程控制
- if 语法
1、语法格式
if [ condition A ]
then
[结果A]
elif [ condition B ]
then [结果 B]
else
[结果 C ]
fi
2、实例
#vi hello.sh ## 编辑脚本 #!/bin/bash read -p "Please input yourname :" NAME ## 读取从控制台输入的变量,存为参数 NAME if [ $NAME = root ] ## 注意,这里的[]是有空格的,[]是命令,命令之间,就有空格 then echo "Hello ${NAME}, welcome !" elif [ $NAME = gzw ] then echo "Hello ${NAME}, welcome !" else echo "DSB,get out !" fi #输入值为 gzw # sh ./hello.sh Please input yourname :gzw Hello gzw, welcome !
#输入值为 root # sh ./hello.sh Please input yourname :root Hello root, welcome !
#输入值为 特殊值 # sh ./hello.sh Please input yourname :hhh DSB,get out !
3、判断条件
1、判断条件基本语法
[ condition ] ## 注意,条件的前后,是有空格的
# 条件非空,返回 true ,可用 $? 验证 (0 为 true ,> 1 为 false)
[ itcast ]
# 空返回 false
#vi if.sh #!/bin/bash if [ a=b ] ##等号左右没有加空格,就不会作为判断,而作为一个字符串,[]内字符为非空,就为 true 的结果 then echo ok else echo notok fi 结果: # sh ./if.sh ok
#!/bin/bash
if [ a = b ] ##等号左右有加空格,会作为判断,等号会变成命令,因为隔开了
then
echo ok
else
echo notok
fi
结果:
# sh ./if.sh
notok
#!/bin/bash
if [ ] ##左右只有俩空格,没有任何东西,或者里面只有三空格,会执行 false
then
echo ok
else
echo notok
fi
结果:
# sh ./if.sh
notok
2、条件判断组合
[ condition ] && echo ok || echo notok ## condition 成立 ,执行 echo ok ,不成立执行 echo notok ,可以理解为三元运算符
条件满足,执行后面的 && ,不满足执行 ||
注意:[ ] 和 [[ ]] 的区别:[[ ]] 中逻辑组合可以使用 && || 符号
而 [ ] 里面逻辑组合可以用 -a -o ## -a 是and关系,or 是或的关系
#vi if2.sh #!/bin/bash if [ a = b && b = c ] then echo ok else echo notok fi 结果: # sh ./if2.sh ./if2.sh: line 2: [: missing `]' notok
#!/bin/bash
if [[ a = b && b = c ]] ##这里是 俩 [[ ]] ,单括号不支持与或非符号的
then
echo ok
else
echo notok
fi
结果:
# sh ./if2.sh
notok
#!/bin/bash
if [ a = b -a b = c ]
then
echo ok
else
echo notok
fi
结果:
# sh ./if2.sh
notok
#!/bin/bash
if [ a = b -o b = b ]
then
echo ok
else
echo notok
fi
结果:
# sh ./if2.sh
ok
3、常用判断运算符
字符串比较: = != -z -n (=就是相等;!=就是不相等;-z是指字符串长度为0,返回 true;-n是字符串长度不为0,返回 true)

整数比较:
- -lt 小于
- -le 小于等于
- -eq 等于
- -gt 大于
- -ge 大于等于
- -ne 不等于
文件判断:
- -d 是否为目录
- -f 是否为文件
- -e 是否存在

- while 语法
1、方式1
while expression
do
command
...
done
2、方式2
i=1
while ((i<=3))
do
echo $i
let i++
done
- cese 语法
case $1 in
start)
echo "starting"
;;
stop)
echo "stoping"
;;
*)
echo "Usage:{start|stop}"
esac
- for 语法
五、函数使用
1、函数定义
#!/bin/sh # func1.sh hello() { echo "Hello there today's date is `date +%Y-%m-%d`" # return 2 } hello # echo $? echo "now going to the function hello" echo "back from the function" 执行结果: # sh ./func1.sh Hello there today's date is 2019-01-06 now going to the function hello back from the function
函数调用:
fuction hello() 或者 function hello 或者 hello
注意:
- 必须在调用函数之前,先声明函数,shell 脚本是逐行运行。不会像其他语言一样预先编译
- 函数返回值,只能通过 $? 系统变量或的,可以显示加 : return 返回,如果不加,将以最后一条命令运行结果,作为返回值。 return 后跟数值 n(0-255)
脚本调试:(基本不用)
sh -vx helloWorld.sh 或者在脚本中增加 set -x
2、函数参数
#!/bin/bash #func2.sh funcWithParam(){ echo "第一个参数为 $1 !" echo "第二个参数为 $2 !" echo "第十个参数为 $10 !" echo "第十个参数为 ${10} !" echo "第十一个参数为 ${11} !" echo "参数总数有 $# 个 !" echo "作为一个字符串输出所有参数 $* !" } funcWithParam 1 2 3 4 5 6 7 8 9 34 73 执行结果: # sh ./func2.sh 第一个参数为 1 ! 第二个参数为 2 ! 第十个参数为 10 ! 第十个参数为 34 ! 第十一个参数为 73 ! 参数总数有 11 个 ! 作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
注意:$10 不能获取第 10 个参数,获取第 10 个参数需要 ${10} 。当 n >= 10 时,需要使用 ${n} 来获取参数。
3、函数返回值
#!/bin/bash #func3.sh funcWithReturn(){ echo "这个函数会对输入的两个数字进行相加运算..." echo "输入第一个数字:" read aNum echo "输入第二个数字:" read anotherNum echo "两个数字分别为 $aNum 和 $anotherNum !" return $(($aNum+$anotherNum)) } funcWithReturn echo "输入的两个数字之和为:$? !" 结果: # sh ./func3.sh 这个函数会对输入的两个数字进行相加运算... 输入第一个数字: 8 输入第二个数字: 5 两个数字分别为 8 和 5 ! 输入的两个数字之和为:13 !
返回值的范围是 0-255之间
4、跨脚本调用函数
假如上述脚本的文件 fun2.sh 保存在路径:/root/fun2.sh
则可在脚本 fun_other.sh 中调用脚本 fun_other 中的函数
#!/bin/bash #func_other.sh . /root/func2.sh ##注:. 和 / 之间要有空格 为啥要有空格?因为 /root/func2.sh 是在一个子进程内加载,而我的当前进程脚本进程没有那个函数,所以要 source 一下,或者 . 一下 #或者 source /root/func2.sh funcWithParam 11 22 33 44 55 66 77 88 99 100 101 结果: # sh ./func_other.sh 第一个参数为 11 ! 第二个参数为 22 ! 第十个参数为 110 ! 第十个参数为 100 ! 第十一个参数为 101 ! 参数总数有 11 个 ! 作为一个字符串输出所有参数 11 22 33 44 55 66 77 88 99 100 101 !
shell 编程综合练习
自动化软件部署脚本
一、需求
1、描述:公司内部有一 N 个节点集群,需要统一安装一些软件,例如;jdk,开发一个脚本,实现对局域网中的 N 台节点批量自动下载,并且安装 jdk
思路
1、编写一个启动脚本,用来发送一个软件安装脚本到每一台机器
2、然后启动每台机器上的软件安装脚本来执行软件下载和安装
具体实现方式:我们可以用一台服务器配置成基服务器,上面搭建好一个 web 容器,比如 apache ,把 jdk 的包放在 var/www/html/software 下面,总之是个路径,让其他的服务器能够通过一个网页打开的方式,获取到这个 jdk 的安装包,而不是全部去 wget 下载,这样太慢了。
那么,我们可以写两个脚本 ,第一个脚本是 bootstrap.sh 作用是将第二个 install.sh 发送到每一个节点上。真正的安装软件的过程,是在 install.sh 上面。这样,每一台都有自己的 install.sh 。install.sh 内写啥呢?先从基服务器上下载安装包,下载后解压,解压后配置环境变量
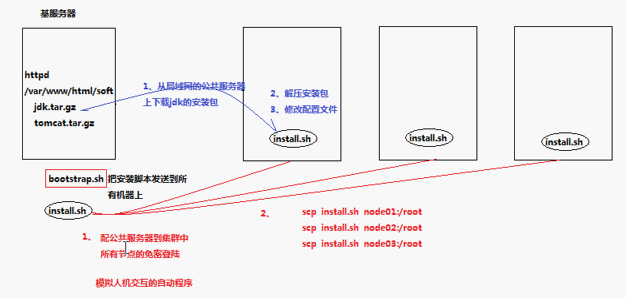
细节:那么我们公共服务器怎么将 install.sh 发送到各节点呢?用 scp install.sh node :/root 做循环,但是要 scp 就要配置免密登录,否则就得验证指纹啥的,脚本太复杂了。我们看免密登录怎么弄?人机交互expect 可以解决
expect的使用
痛点:使用 scp 命令远程拷贝文件时,会有人机交互的过程,如何让脚本完成人机交互?
妙药: expect
用法实例:
先观察 ssh localhost 的过程
再看 expect 的功能
# vi exp_test.sh
#!/bin/bash/expect ## exp_test.sh set timeout -1; spawn ssh localhost; expect { "(yes/no)" {send "yes ";exp_continue;} "password:" {send "123456 ";exp_continue;} eof {exit 0;} }
执行: expect -f exp_test.sh
脚本搞好了之后,可以在 /etc/hosts 内,以 ip 子机名 的形式 ,搞好 hosts 文件,ping 一下看是否可以 ping 通,可以写进 boot.sh 的 SERVERS 内
三、脚本开发
1、vi boot.sh
SERVERS="gzw1 gzw2" #要安装的服务器名称 PASSWORD=123456 #服务器上的password BASE_SERVER=47.107.183.88 #公共服务器的 ip ## 实现免密登录配置的函数 auto_ssh_copy_id(){ expect -c"set timeout -1; spawn ssh-copy-id $1; expect { *(yes/no)*{send --yes ;exp_continue;} *assword:*{send --$2 ;exp_continue;} eof {exit0;} }"; } ssh_copy_id_to_all(){ for SERVER in $SERVERS do auto_ssh_copy_id $SERVER $PASSWORD done } ## 调用免密登录配置函数,实现母机到个子机的免密登陆配置 ssh_copy_id_to_all ##完成分发 install.sh 到各子机的操作 ##并让子机启动 install.sh for SERVER in $SERVERS do scp insatll.sh root@$SERVER:/root ssh root@$SERVER /root/install.sh ##一台机器,执行另一台机器的 install.sh done
2、安装执行脚本
vi install.sh
#!/bin/bash BASE_SERVER=47.107.183.88 ##母机的 ip ## 为本机安装 wget 命令 yum install -y wget ## 使用 wget 从母机的 web 服务器上下载 jdk 压缩包 wget $BASE_SERVER/software/jdk-XXX ## 将下载的压缩包解压到一个相同路径下 tar -zxvf jdk-XXX -C /usr/local ## 修改 profile 配置文件 cat >> /etc/profile << EOF ##往 /etc/profile 内追加两行,如果修改很复杂,就要用 awk ,这里,cat 将 EOF 之间的内容重定向到 /etc/profile 内 export JAVA_HOME=/usr/local/jdk-XXX export PATH=$PATH:$JAVA_HOME/bin EOF
最后,在母机上 运行 boot.sh 就 ok