一、numpy、
1、下载pip install numpy
导入import numpy as np -----np是约定俗称的
2、ndarray-多维数组对象
1)创建:np.array()
2)多维数组列表
数组对象内的元素类型必须相同,切大小不可修改
3)属性
| 属性 | 描述 |
| T | 数组的转置 |
| dtype | 数组元素的数据类型 |
| size | 数组元素个数 |
| nadim | 数组的维数 |
| shape | 数组的维度大小(以元组的形式) |
4)数据类型
bool_
int_
uint8 : 无符号整型 即不能用来存负数
float_
complex
astype() 方法可以用来修改数据类型
5)nadarry创建
| 方法 | 描述 |
| array() | 将列表转换为数组,可选择显式指定dtype |
| arange() | range的numpy版,支持浮点数 |
| linspace() | 类似arange(),第三个参数为数组长度 |
| zeros() | 根据指定形状和dtype创建全0数组 |
| ones() | 根据指定形状和dtype创建全1数组 |
| empty() | 根据指定形状和dtype创建空数组(随机值) |
| eye() | 根据指定边长和dtype创建单位矩阵 |
6)切片、索引和布尔型索引
3、函数
3.0常用函数
abs(计算绝对值),fads(复数)
sqrt(平方根),square(平方的),exp(指数函数),
3.1数学统计方法
| 函数 | 功能 |
| sum | 求和 |
| cumsum | 求前缀和 |
| mean | 求平均数 |
| std | 求标准差 |
| var | 求方差 |
| min | 求最小值 |
| max | 求最大值 |
| argmin | 求最小值索引 |
| argmax | 求最大值索引 |
3.2随机数
| 函数 | 功能 |
| rand | 随机数组(0~1之间的数) |
| randint | 随机整数 |
| chocie | 随机选择 |
| shuffle | 随机排序 |
| uniform | 随机数组 |
二、pandas
import pandas as pd
1)Series
-创建:


第一种: pd.Series([4,5,6,7,8]) 执行结果: 0 4 1 5 2 6 3 7 4 8 dtype: int64 # 将数组索引以及数组的值打印出来,索引在左,值在右,由于没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引,取值的时候可以通过索引取值,跟之前学过的数组和列表一样 ----------------------------------------------- 第二种: pd.Series([4,5,6,7,8],index=['a','b','c','d','e']) 执行结果: a 4 b 5 c 6 d 7 e 8 dtype: int64 # 自定义索引,index是一个索引列表,里面包含的是字符串,依然可以通过默认索引取值。 ----------------------------------------------- 第三种: pd.Series({"a":1,"b":2}) 执行结果: a 1 b 2 dtype: int64 # 指定索引 ----------------------------------------------- 第四种: pd.Series(0,index=['a','b','c']) 执行结果: a 0 b 0 c 0 dtype: int64 # 创建一个值都是0的数组
-缺失数据方法
dropna() # 过滤掉值为NaN的行
fill() # 填充缺失数据
isnull() # 返回布尔数组,缺失值对应为True
notnull() # 返回布尔数组,缺失值对应为False
1、 obj1.isnull() # 是缺失值返回Ture 运行结果: rocky True cloud False sean False yang False dtype: bool 2、 obj1.notnull() # 不是缺失值返回Ture 运行结果: rocky False cloud True sean True yang True dtype: bool 3、过滤缺失值 # 布尔型索引 obj1[obj1.notnull()] 运行结果: cloud 21.0 yang 19.0 sean 18.0 dtype: float64
-loc属性 # 以标签解释 (索引为具体标签)
iloc属性 # 以下表解释 (索引为行列数字)
2)DataFrame
DataFrame是一个表格型的数据结构,相当于是一个二维数组,含有一组有序的列。他可以被看做是由Series组成的字典,并且共用一个索引
-创建:
第一种: pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) # 产生的DataFrame会自动为Series分配所索引,并且列会按照排序的顺序排列 运行结果: one two 0 1 4 1 2 3 2 3 2 3 4 1 > 指定列 可以通过columns参数指定顺序排列 data = pd.DataFrame({'one':[1,2,3,4],'two':[4,3,2,1]}) pd.DataFrame(data,columns=['one','two']) # 打印结果会按照columns参数指定顺序 第二种: pd.DataFrame({'one':pd.Series([1,2,3],index=['a','b','c']),'two':pd.Series([1,2,3],index=['b','a','c'])}) 运行结果: one two a 1 2 b 2 1 c 3 3
-查看属性和方法
index获取行索引
columns获取列索引
T转置
values获取值索引
describe 获取快速统计
one two a 1 2 b 2 1 c 3 3 # 这样一个数组df ----------------------------------------------------------------------------- df.index 运行结果: Index(['a', 'b', 'c'], dtype='object') ---------------------------------------------------------------------------- df.columns 运行结果: Index(['one', 'two'], dtype='object') -------------------------------------------------------------------------- df.T 运行结果: a b c one 1 2 3 two 2 1 3 ------------------------------------------------------------------------- df.values 运行结果: array([[1, 2], [2, 1], [3, 3]], dtype=int64) ------------------------------------------------------------------------ df.describe() 运行结果: one two count 3.0 3.0 mean 2.0 2.0 std 1.0 1.0 min 1.0 1.0 25% 1.5 1.5 50% 2.0 2.0 75% 2.5 2.5 max 3.0 3.0
-可以通过loc和iloc两种方法进行索引和切片
3、时间对象处理(baidu)
4、数据分组和聚合
分组(groupby)
df = pd.DataFrame({'key1':['x','x','y','y','x',
'key2':['one','two','one',',two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
运行结果:
key1 key2 data1 data2
0 x one 0.951762 1.632336
1 x two -0.369843 0.602261
2 y one 1.512005 1.331759
3 y ,two 1.383214 1.025692
4 x one -0.475737 -1.182826
# 调用
f1 = df['data1'].groupby(df['key1'])
f1
运行结果:
<pandas.core.groupby.groupby.SeriesGroupBy object at 0x00000275906596D8>
# 求平均值
f1.mean() # 调用mean函数求出平均值
运行结果:
key1
x 0.106183
y 2.895220
Name: data1, dtype: float64
5、其他
读取文件:pd.read_csv('./a.csv')
另存:df.tocsv('./a.csv',index=False) # index判断是否添加索引
mean(axis=0,skipna=False)
sum(axis=1)
sort_index(axis, …, ascending) # 按行或列索引排序
sort_values(by, axis, ascending) # 按值排序
apply(func, axis=0) # 将自定义函数应用在各行或者各列上,func可返回标量或者Series
applymap(func) # 将函数应用在DataFrame各个元素上
map(func) # 将函数应用在Series各个元素上
三、matplotlib (绘图和可视化)
Matplotlib是一个强大的Python绘图和数据可视化的工具包。
pip install matplotlib import matplotlib.pyplot as plt
# 防止乱码问题,只对windows游泳
plt.rcParams['font.sans-serif'] = ['SimHei']
1、绘制线形图(plot)
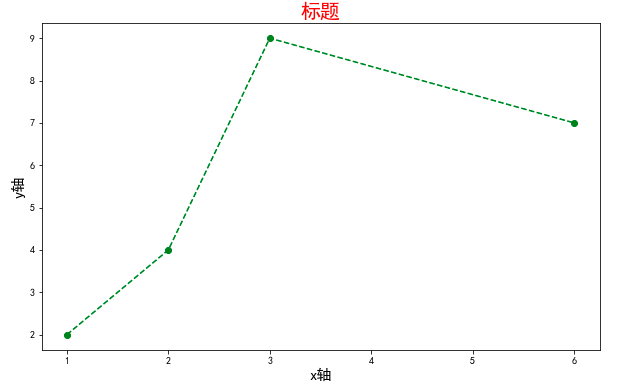
1)代码
x = [1,2,3,6] y = [2,4,9,7] plt.figure(figsize=(10,6)) # 图大小 plt.title('标题', fontsize=20, color='red') plt.xlabel('x轴', fontsize=15) plt.ylabel('y轴', fontsize=15) # plt.plot(x,y, color='green', marker='v', linestyle='--') plt.plot(x, y, 'go--') # g:green, o:焦点, --:连线用虚线 plt.show() # 展示图命令
2)图例
2、绘制柱状图 (bar)
1)数据获取
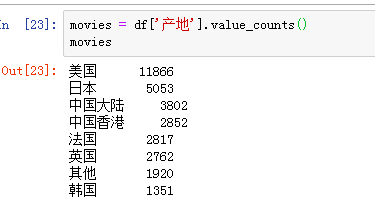
2)代码
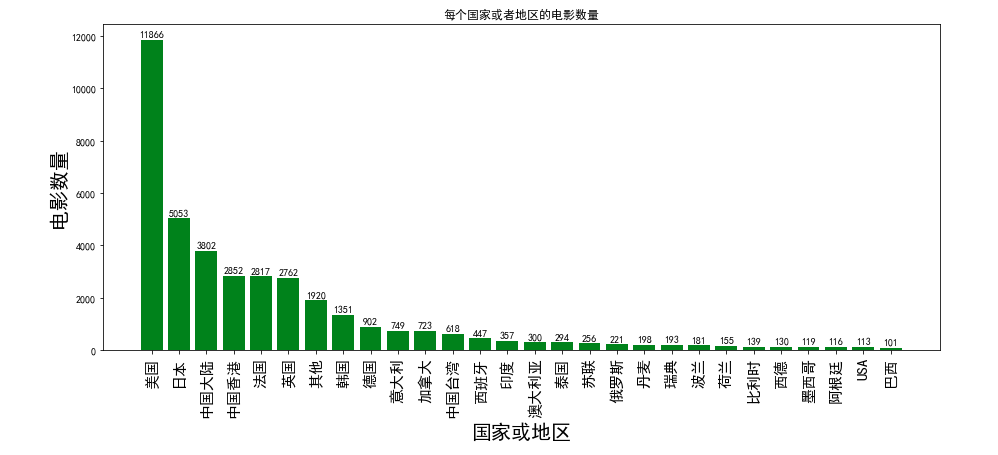
x = movies.index y = movies.values plt.figure(figsize=(15,6)) plt.title('每个国家或者地区的电影数量') plt.xlabel('国家或地区', fontsize=20) plt.ylabel('电影数量', fontsize=20) plt.xticks(rotation=90, fontsize=15) plt.bar(x, y, color='green') # 柱状图 # plt.text? for a,b in zip(x,y): # 每隔10个显示 zip(x[::10],y[::10]) plt.text(a, b+100, b, ha='center') # 四个参数分别对应:x轴,y轴 ,柱顶的值,中心分部 plt.show()
3)图例
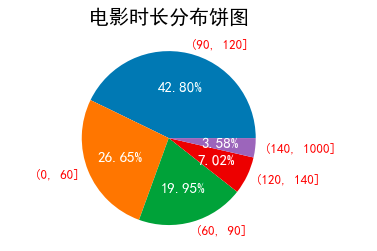
3、绘制饼图 (pie)
1)、数据准备
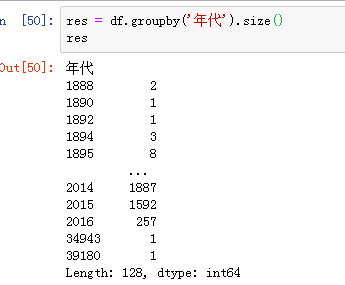
2)代码:
### df_res 是待分割的源数据 [0,60,90,120, 140, 1000] 是区间 左开右闭 res = pd.cut(df_res, [0,60,90,120, 140, 1000]) res = res.value_counts() # 求分割后各组值 x = res.index y = res.values plt.title('电影时长分布饼图', fontsize=20) patch, l_text, p_text = plt.pie(y, labels = x, autopct='%.2f%%') # autopct 内部百分比 for p in p_text: # 圈内属性 p.set_size(15) p.set_color('white') for l in l_text: # 外圈属性 l.set_size(13) l.set_color('r') plt.show()
3)图例:
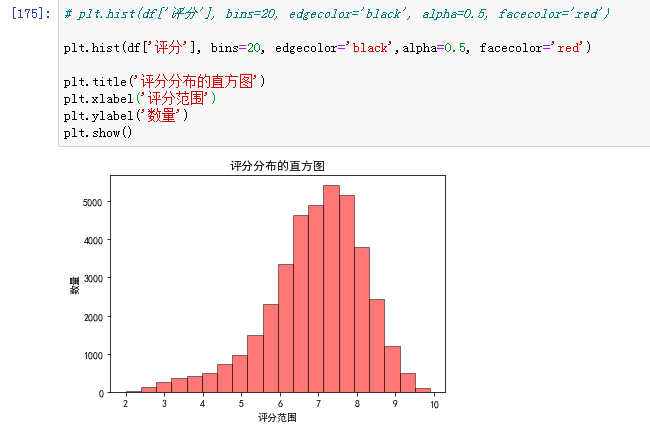
4、直方图(hist)