概述:
NodeJS宣称其目标是“旨在提供一种简单的构建可伸缩网络程序的方法”,那么它的出现是为了解决什么问题呢,它有什么优缺点以及它适用于什么场景呢?
本文就个人使用经验对这些问题进行探讨。
一. NodeJS的特点
我们先来看看NodeJS官网上的介绍:
Node.js is a platform built on Chrome's JavaScript runtime for easily building fast, scalable network applications. Node.js uses an event-driven, non-blocking I/O model that makes it lightweight and efficient, perfect for data-intensive real-time applications that run across distributed devices.
其特点为:
1. 它是一个Javascript运行环境
2. 依赖于Chrome V8引擎进行代码解释
3. 事件驱动
4. 非阻塞I/O
5. 轻量、可伸缩,适于实时数据交互应用
6. 单进程,单线程
二. NodeJS带来的对系统瓶颈的解决方案
它的出现确实能为我们解决现实当中系统瓶颈提供了新的思路和方案,下面我们看看它能解决什么问题
1. 并发连接
举个例子,想象一个场景,我们在银行排队办理业务,我们看看下面两个模型
(1)系统线程模型:
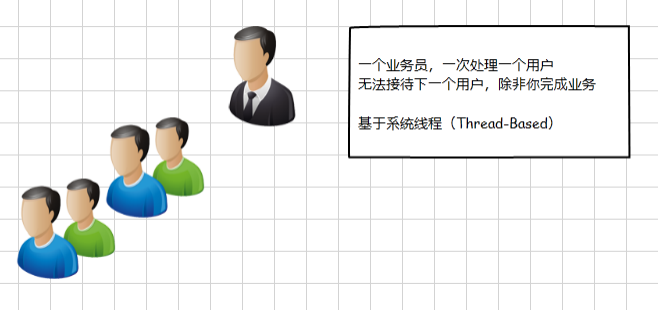
这种模型的问题显而易见,服务端只有一个线程,并发请求(用户)到达只能处理一个,其余的要先等待,这就是阻塞,正在享受服务的请求阻塞后面的请求了
(2)多线程、线程池模型:
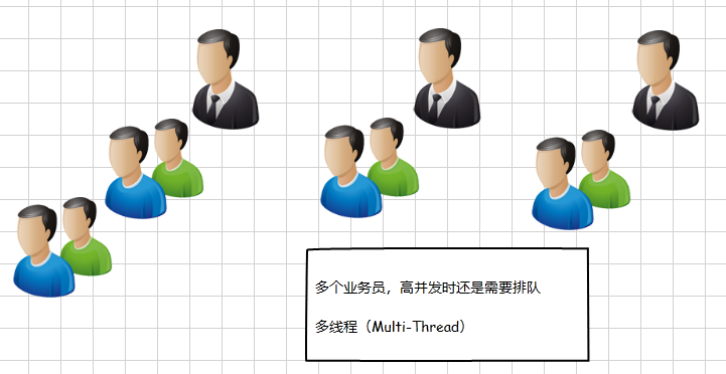
这个模型已经比上一个有所进步,它调节服务端线程的数量来提高对并发请求的接收和响应,但并发量高的时候,请求仍然需要等待,它有个更严重的问题:
回到代码层面上来讲,我们看看客户端请求与服务端通讯的过程:
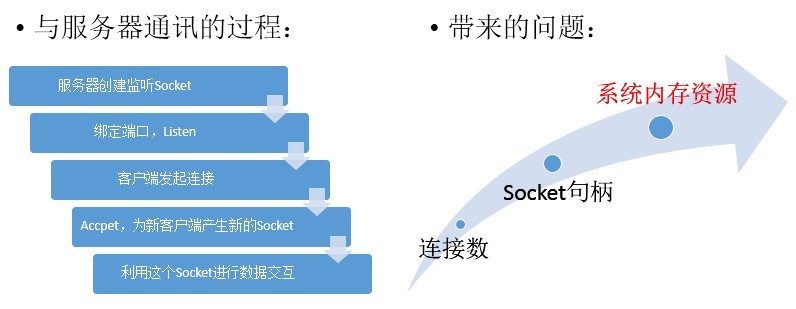
服务端与客户端每建立一个连接,都要为这个连接分配一套配套的资源,主要体现为系统内存资源,以PHP为例,维护一个连接可能需要20M的内存
这就是为什么一般并发量一大,就需要多开服务器
那么NodeJS是怎么解决这个问题的呢?
我们来看另外一个模型,想象一下我们在快餐店点餐吃饭的场景
(3)异步、事件驱动模型
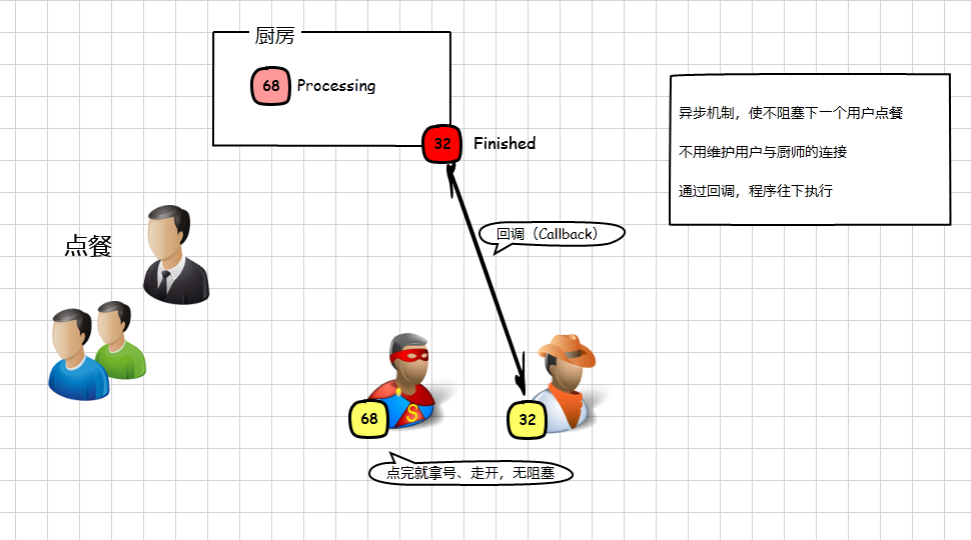
我们同样是要发起请求,等待服务器端响应;但是与银行例子不同的是,这次我们点完餐后拿到了一个号码,
拿到号码,我们往往会在位置上等待,而在我们后面的请求会继续得到处理,同样是拿了一个号码然后到一旁等待,接待员能一直进行处理。
等到饭菜做号了,会喊号码,我们拿到了自己的饭菜,进行后续的处理(吃饭)
这个喊号码的动作在NodeJS中叫做回调(Callback),能在事件(烧菜,I/O)处理完成后继续执行后面的逻辑(吃饭),
这体现了NodeJS的显著特点,异步机制、事件驱动
整个过程没有阻塞新用户的连接(点餐),也不需要维护已经点餐的用户与厨师的连接
基于这样的机制,理论上陆续有用户请求连接,NodeJS都可以进行响应,因此NodeJS能支持比Java、PHP程序更高的并发量
虽然维护事件队列也需要成本,再由于NodeJS是单线程,事件队列越长,得到响应的时间就越长,并发量上去还是会力不从心
总结一下NodeJS是怎么解决并发连接这个问题的:
更改连接到服务器的方式,每个连接发射(emit)一个在NodeJS引擎进程中运行的事件(Event),放进事件队列当中,
而不是为每个连接生成一个新的OS线程(并为其分配一些配套内存)
2. I/O阻塞
NodeJS解决的另外一个问题是I/O阻塞,看看这样的业务场景:需要从多个数据源拉取数据,然后进行处理
(1)串行获取数据,这是我们一般的解决方案,以PHP为例
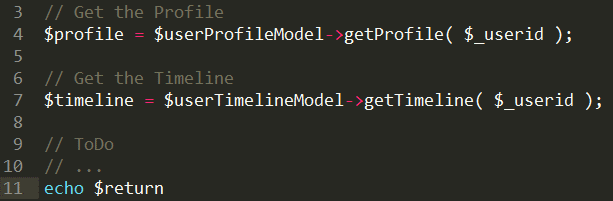
假如获取profile和timeline操作各需要1S,那么串行获取就需要2S
(2)NodeJS非阻塞I/O,发射/监听事件来控制执行过程
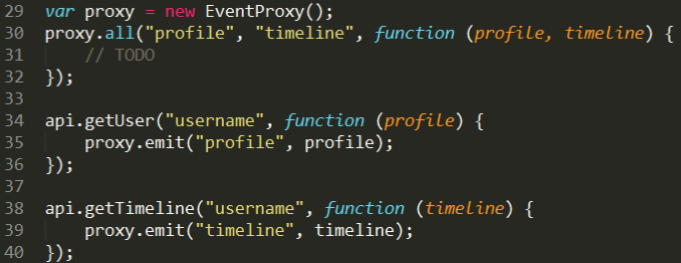
NodeJS遇到I/O事件会创建一个线程去执行,然后主线程会继续往下执行的,
因此,拿profile的动作触发一个I/O事件,马上就会执行拿timeline的动作,
两个动作并行执行,假如各需要1S,那么总的时间也就是1S
它们的I/O操作执行完成后,发射一个事件,profile和timeline,
事件代理接收后继续往下执行后面的逻辑,这就是NodeJS非阻塞I/O的特点
总结一下:
Java、PHP也有办法实现并行请求(子线程),但NodeJS通过回调函数(Callback)和异步机制会做得很自然
三. NodeJS的优缺点
优点:
1. 高并发(最重要的优点)
2. 适合I/O密集型应用
缺点:
1. 不适合CPU密集型应用;CPU密集型应用给Node带来的挑战主要是:由于JavaScript单线程的原因,如果有长时间运行的计算(比如大循环),将会导致CPU时间片不能释放,使得后续I/O无法发起;
解决方案:分解大型运算任务为多个小任务,使得运算能够适时释放,不阻塞I/O调用的发起;
2. 只支持单核CPU,不能充分利用CPU
3. 可靠性低,一旦代码某个环节崩溃,整个系统都崩溃
原因:单进程,单线程
解决方案:(1)Nnigx反向代理,负载均衡,开多个进程,绑定多个端口;
(2)开多个进程监听同一个端口,使用cluster模块;
4. 开源组件库质量参差不齐,更新快,向下不兼容
5. Debug不方便,错误没有stack trace
四. 适合NodeJS的场景
1. RESTful API
这是NodeJS最理想的应用场景,可以处理数万条连接,本身没有太多的逻辑,只需要请求API,组织数据进行返回即可。
它本质上只是从某个数据库中查找一些值并将它们组成一个响应。
由于响应是少量文本,入站请求也是少量的文本,因此流量不高,一台机器甚至也可以处理最繁忙的公司的API需求。
2. 统一Web应用的UI层
目前MVC的架构,在某种意义上来说,Web开发有两个UI层,一个是在浏览器里面我们最终看到的,另一个在server端,负责生成和拼接页面。
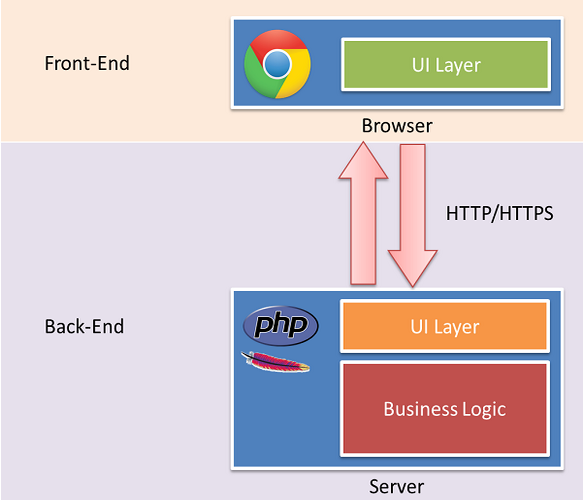
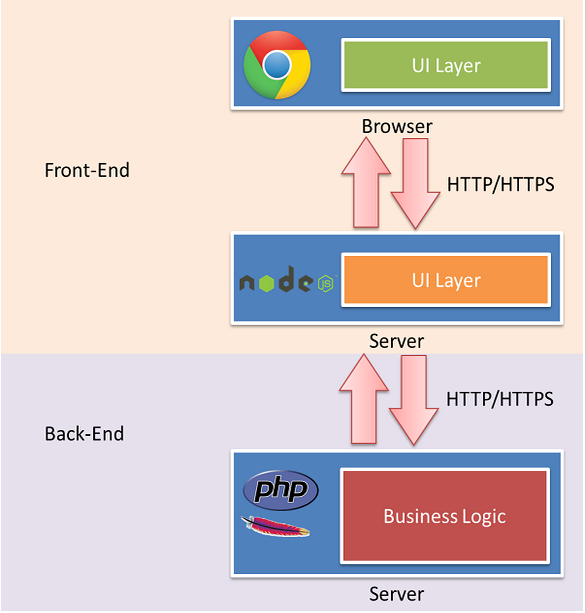
不讨论这种架构是好是坏,但是有另外一种实践,面向服务的架构,更好的做前后端的依赖分离。
如果所有的关键业务逻辑都封装成REST调用,就意味着在上层只需要考虑如何用这些REST接口构建具体的应用。
那些后端程序员们根本不操心具体数据是如何从一个页面传递到另一个页面的,他们也不用管用户数据更新是通过Ajax异步获取的还是通过刷新页面
3. 大量Ajax请求的应用
例如个性化应用,每个用户看到的页面都不一样,缓存失效,需要在页面加载的时候发起Ajax请求,
NodeJS能响应大量的并发请求
总而言之,NodeJS适合运用在高并发、I/O密集、少量业务逻辑的场景;
适合I/O密集型的应用,如在线多人聊天,多人在线小游戏,实时新闻,博客,微博之类的。
不适合的场景有:cpu密集型的应用,如计算圆周率,视频解码等业务场景较多的。
那么什么是I/O密集型,CPU密集型呢?下面详细介绍下:
CPU密集型(CPU-bound)
CPU密集型也叫计算密集型,指的是系统的硬盘、内存性能相对CPU要好很多,此时,系统运作大部分的状况是CPU Loading 100%,CPU要读/写I/O(硬盘/内存),I/O在很短的时间就可以完成,而CPU还有许多运算要处理,CPU Loading很高。
在多重程序系统中,大部份时间用来做计算、逻辑判断等CPU动作的程序称之CPU bound。例如一个计算圆周率至小数点一千位以下的程序,在执行的过程当中绝大部份时间用在三角函数和开根号的计算,便是属于CPU bound的程序。
CPU bound的程序一般而言CPU占用率相当高。这可能是因为任务本身不太需要访问I/O设备,也可能是因为程序是多线程实现因此屏蔽掉了等待I/O的时间。
IO密集型(I/O bound)
IO密集型指的是系统的CPU性能相对硬盘、内存要好很多,此时,系统运作,大部分的状况是CPU在等I/O (硬盘/内存) 的读/写操作,此时CPU Loading并不高。
I/O bound的程序一般在达到性能极限时,CPU占用率仍然较低。这可能是因为任务本身需要大量I/O操作,而pipeline做得不是很好,没有充分利用处理器能力。
CPU密集型 vs IO密集型
我们可以把任务分为计算密集型和IO密集型。
计算密集型任务的特点是要进行大量的计算,消耗CPU资源,比如计算圆周率、对视频进行高清解码等等,全靠CPU的运算能力。这种计算密集型任务虽然也可以用多任务完成,但是任务越多,花在任务切换的时间就越多,CPU执行任务的效率就越低,所以,要最高 效地利用CPU,计算密集型任务同时进行的数量应当等于CPU的核心数。
计算密集型任务由于主要消耗CPU资源,因此,代码运行效率至关重要。Python这样的脚本语言运行效率很低,完全不适合计算密集型任务。对于计算密集型任务,最好用C语言编写。
第二种任务的类型是IO密集型,涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差。
总之,计算密集型程序适合C语言多线程,I/O密集型适合脚本语言开发的多线程。
五. 结尾
其实NodeJS能实现几乎一切的应用
我们考虑的点只是适不适合用它来做
出处:https://www.cnblogs.com/sysuys/p/3460614.html#3964192
六. 参考文献
[2] 理解Node.js事件驱动编程
[3] 是否不擅长CPU密集型业务
[4] 使用 Node.js 的优势和劣势都有哪些?有大公司用吗?
[5] Node.js给前端带来了什么