前言:
CPU在摩尔定律的指导下以每18个月翻一番的速度在发展,然而内存和硬盘的发展速度远远不及CPU。这就造成了高性能能的内存和硬盘价格及其昂贵。然而CPU的高度运算需要 高速的数据。为了解决这个问题,CPU厂商在CPU中内置了少量的高速缓存以解决IO速度和CPU运算速度之间的不匹配问题。
首先在电脑中,CPU读取RAM中的数据数据的流程是,通过I/O总线(BUS),将数据从RAM中获取需要操作的数据进CPU需要如下几个步骤
- CPU中的三级缓存从RAM中获取该数据。
- CPU中的二级缓存从三级缓存中获取改数据。
- CPU中的一级缓存从二级缓存中获取改数据。
- CPU中的寄存器从一级缓存中获取该数据。然后进行想对应的处理运算。
- 然后一步步返回给RAM
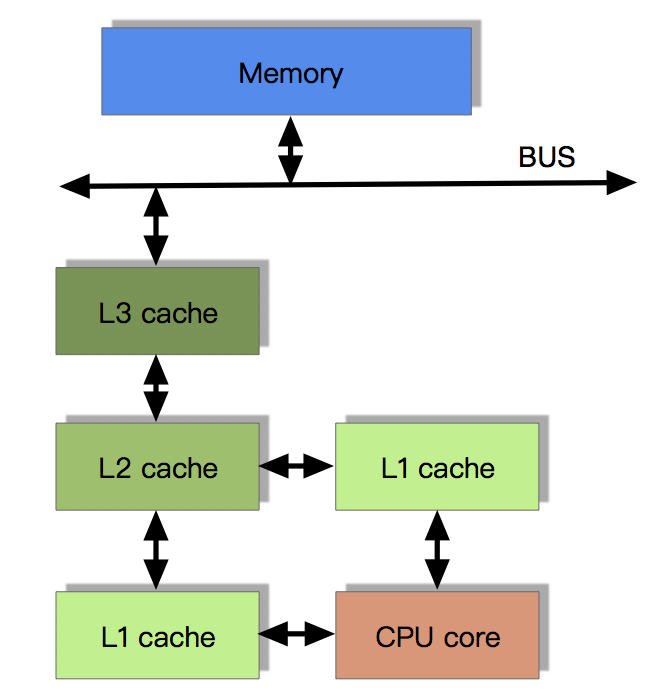
这是一个单核CPU的处理过程,那么现在随着技术的不断发展和CPU的不断升级,出现了多核CPU 或者一个主板上面有多个CPU的存在,那么上面的操作,在某些时候可能就是不安全的,
因为可能多个线程控制的CPU会同时对该数据进行处理和运算。那么我们该如何解决这种办法呢?
首先我们可能想到在BUS IO总线上进行锁定,但是换个角度思考,如果总线锁定了,那么会对后面其他CPU的执行命令造成堵塞。
多核CPU多级缓存一致性协议MESI
多核CPU的情况下有多个一级缓存,如何保证缓存内部数据的一致,不让系统数据混乱。这里就引出了一个一致性的协议MESI。
加入了这个一致性的方法,就解决了缓存可能造成的不一致的问题。具体流程是怎么走的呢?
- 首先还是前面的流程,当CPU1进行读取数据的时候,把数据读取到自己的 缓存中时,会给该数据内容打上一个标记E(独享),该数据就我有,其他人都没有(在此时,CPU会时刻监听其他CPU的状态)。
- 与此同时,CPU2也后去到了该数据,然后CPU获取到该数据也有其他CPU进行缓存,那么就会给该数据打上 一个S(共享)的状态,且CPU1也 会将该状态改成S。
- CPU1继续进行,处理完该数据,将状态改成M(修改)将改缓存行进行锁定,与此同时其他CPU 不断的监控状态,获取到之后 将自己的状态改成I(无效)然后进行废弃。
- 如果同时多个CPU 都将数据修改成M状态,那么底层就会触发一个选举机制,只选出一个人来进行修改M
缓存行(Cache line):缓存存储数据的单元。CPU 最小的储存单元。
| 状态 | 描述 | 监听任务 |
|---|---|---|
| M 修改 (Modified) | 该Cache line有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中。 | 缓存行必须时刻监听所有试图读该缓存行相对就主存的操作,这种操作必须在缓存将该缓存行写回主存并将状态变成S(共享)状态之前被延迟执行。 |
| E 独享、互斥 (Exclusive) | 该Cache line有效,数据和内存中的数据一致,数据只存在于本Cache中。 | 缓存行也必须监听其它缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成S(共享)状态。 |
| S 共享 (Shared) | 该Cache line有效,数据和内存中的数据一致,数据存在于很多Cache中。 | 缓存行也必须监听其它缓存使该缓存行无效或者独享该缓存行的请求,并将该缓存行变成无效(Invalid)。 |
| I 无效 (Invalid) | 该Cache line无效。 | 无 |
什么时候缓存一致性协议失效呢?
当缓存的数据长度大于一个缓存行的时候,就会失效。换句话说就是一个缓存行可以储存多个数据,但是一个数据不可以跨多个缓存行。
未完待续!!
接下来我们要了解一下什么是用户态和内核态:URL: