日志分析
概述

分析的前提
半结构化数据

文本分析

提取数据(信息提取)
一、空格分隔
with open('xxx.log')as f: for line in f: for field in line.split(): print(field)


#注意这里拼接的一些技巧 logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu =3 HTTP/1.1" 200 16691 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou .com/search/spider.html)"''' fields = [] flag = False tmp = '' #注意拼接"GET /020/media.html?menu=3 HTTP/1.1"这种字符串需借助标记变量! for field in logs.split(): if not flag and (field.startswith('[') or field.startswith('"')): if field.endswith(']') or field.endswith('"'):#处理首尾均有[]的字符串 fields.append(field.strip('[]"')) # 处理只有左中括号的字符串,但是该字符串应该与接下类的某一段含有右括号的字符拼接起来[19/Feb/2013:10:23:29 else:# tmp += field[1:] flag = True continue #处理[19/Feb/2013:10:23:29 +0800]中的+0800] if flag: if field.endswith(']') or field.endswith('"'): tmp += " " + field[:-1] fields.append(tmp) tmp = '' flag = False else: tmp +=" " + field continue fields.append(field)#直接加入不带有[]""的字符串
类型转换


import datetime def convert_time(timestr): return datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') #若上面的函数可简写成匿名函数形式 lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z')
请求信息的解析

def get_request(request:str): return dict(zip(['method','url','protocol'],request.split())) #上面的函数对应为如下匿名函数 lambda request:dict(zip(['method','url','protocol'],request.split()))
映射
![]()
1 import datetime 2 logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu 3 =3 HTTP/1.1" 200 16691 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou 4 .com/search/spider.html)"''' 5 6 def convert_time(timestr): 7 return datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') 8 9 # lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z') 10 11 def get_request(request:str): 12 return dict(zip(['method','url','protocol'],request.split())) 13 14 # lambda request:dict(zip(['method','url','protocol'],request.split())) 15 16 names = ('remote','','','datetime','request','status','length','','useragent') 17 ops = (None,None,None,convert_time,get_request,int,int,None,None) 18 19 def extract(line): 20 fields = [] 21 flag = False 22 tmp = '' 23 24 #"GET /020/media.html?menu=3 HTTP/1.1" 25 for field in logs.split(): 26 if not flag and (field.startswith('[') or field.startswith('"')): 27 if field.endswith(']') or field.endswith('"'):#处理首尾均有[]的字符串 28 fields.append(field.strip('[]"')) 29 # 处理只有左中括号的字符串,但是该字符串应该与接下类的某一段含有右括号的字符拼接起来[19/Feb/2013:10:23:29 30 else:# 31 tmp += field[1:] 32 flag = True 33 continue 34 #处理[19/Feb/2013:10:23:29 +0800]中的+0800] 35 if flag: 36 if field.endswith(']') or field.endswith('"'): 37 tmp += " " + field[:-1] 38 fields.append(tmp) 39 tmp = '' 40 flag = False 41 else: 42 tmp +=" " + field 43 continue 44 45 fields.append(field)#直接加入不带有[]""的字符串 46 47 # print(fields) 48 info = {} 49 for i,field in enumerate(fields): 50 name = names[i] 51 op = ops[i] 52 if op: 53 info[name] = (op(field)) 54 return info 55 56 print(extract(logs))
二、正则表达式提取
![]()
pattern = '''([d.]{7,}) - - [([/w +:]+)] "(w+) (S+) ([w/d.]+)" (d+) (d+) .+ "(.+)"''' names = ('remote','datetime','request','method','url','ptorocol','status','length','useragent') ops = (None,lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'),None,None,None,int,int,None)

pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[/w +:]+)] "(?P<method>w+) (?P<url>S+) (?P<protocol>[w/d.]+)" (?P<status>d+) (?P<length>d+) .+ "(?PM<useragent>.+)"''' ops = { 'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'), 'status':int, 'length':int }
import datetime import re logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"''' pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[w/ +:]+)] "(?P<method>w+) (?P<url>S+) (?P<protocol>[w/d.]+)" (?P<status>d+) (?P<length>d+) .+ "(?P<useragent>.+)"''' ops = { 'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'), 'status':int, 'length':int } regex = re.compile(pattern) def extract(line): matcher = regex.match(line)
#matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典
info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()}
return info print(extract(logs))
异常处理


![]()
![]()

![]()
滑动窗口
数据载入

时间窗口分析
概念

当width>interval(数据求值时会有重叠)
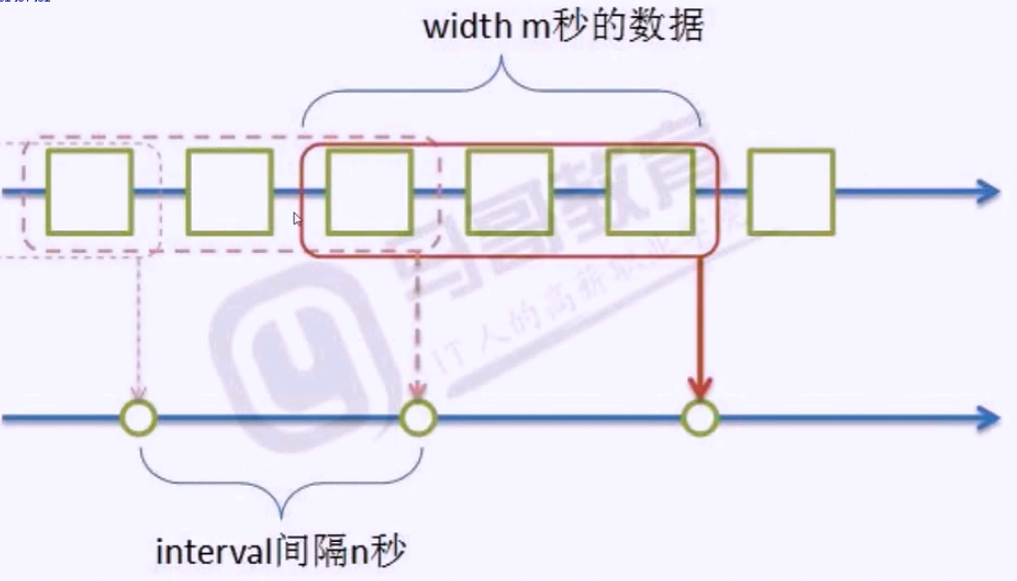
当width=interval(数据求值时没有重叠)
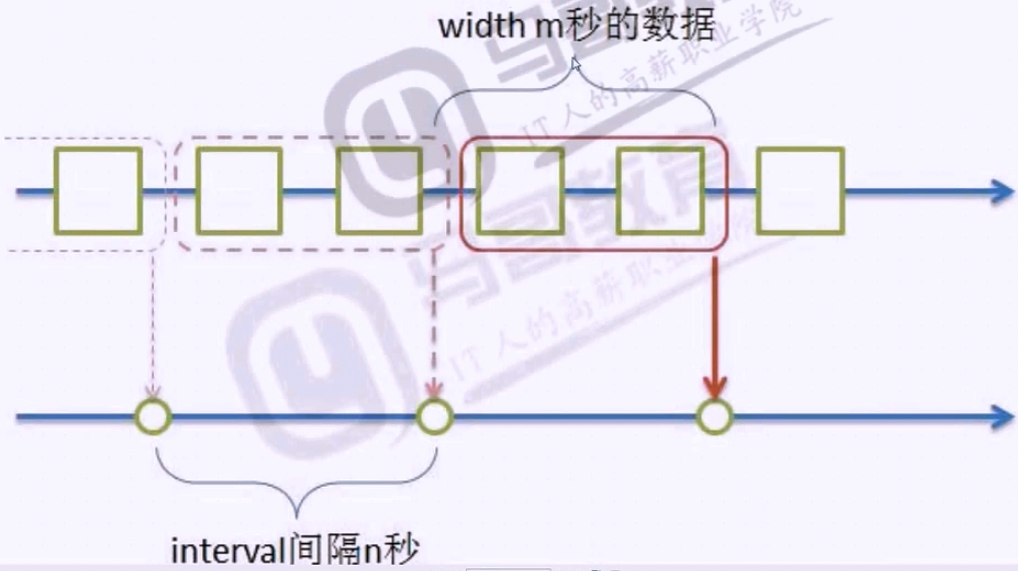
当width<interval(一般不采纳这种方案,会有数据缺失)
时序数据

数据分析基本程序结构

import random import datetime def source(): while True: yield {'datetime':datetime.datetime.now(),'value':random.randint(1,10)} #获取数据 src = source() items = [next(src) for _ in range(3)] # print(items) #处理函数 def handler(iterable): vals = [x['value'] for x in iterable] return sum(vals)/len(vals) print(handler(items)) #上述代码实模拟了一段时间内产生了数据,等了一段固定的时间取数据计算其平均值。
窗口函数实现
将上面的获取数据的程序扩展为windows函数,使用重叠的方案!
#代码实现: import random import datetime import time def source(): while True: yield {'value':random.randint(1,100),'datetime':datetime.datetime.now()} time.sleep(1) def windows(src,handler,int,interval:int): """ :param src:数据源、生成器、用来拿数据 :param handler: 数据处理函数 :param 时间窗口宽度,秒 :param interval: 处理时间间隔,秒 :return:None """ start = datetime.datetime.strptime('19710101 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z') current = datetime.datetime.strptime('19710101 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z') buffer = [] #窗口中待计算的数据 delta = datetime.timedelta(seconds=width-interval) for data in src: if data:#存入临时缓存区 buffer.append(x) current =data['datetime'] if (current - start).total_seconds() >= interval: ret = handler(buffer) print("{:.2f}".format(ret)) start = current #更新buffer,current - delta表示需要重叠的数据 buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数 def handler(iterable): vals = [x['value'] for x in iterable] return sum(vals) / len(vals) windows(source(),handler,10,5)
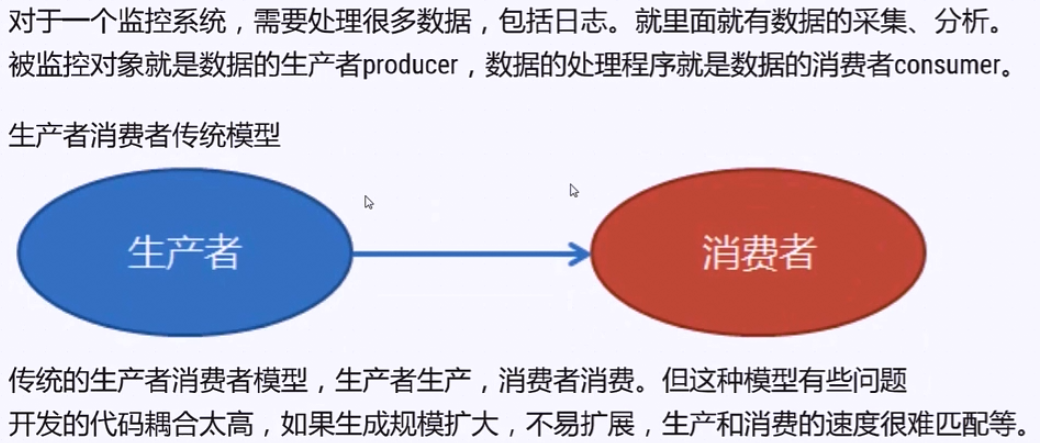
分发
生产者消费模型


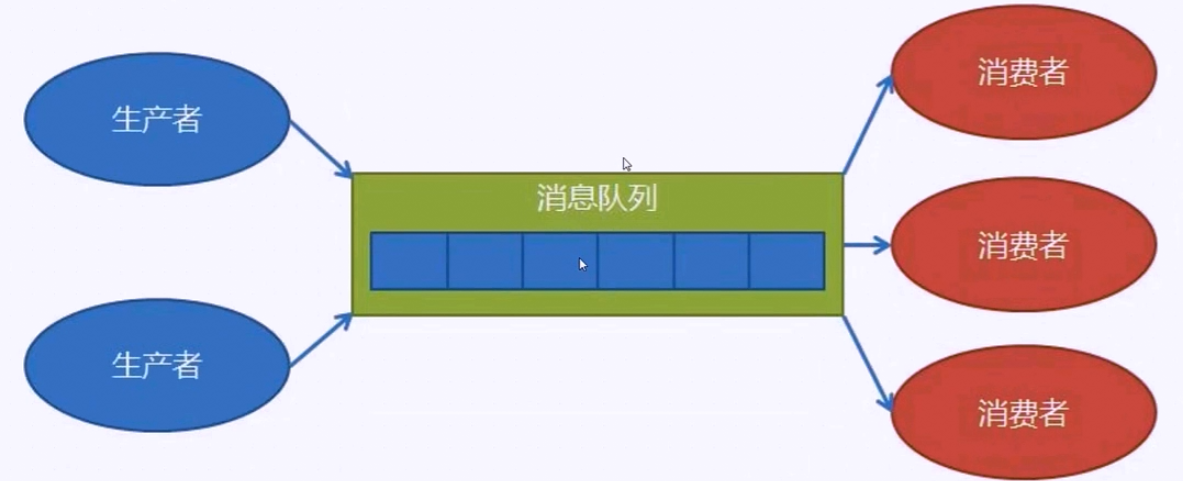
![]()

queue模块--队列
![]()





from queue import Queue import random q = Queue() print(q.put(random.randint(1,100))) print(q.put(random.randint(1,100))) print(q.get()) print(q.get()) print(q.get(timeout=2))#阻塞两秒后抛出空值异常
分发器的实现




![]()
![]()
import threading #定义线程 #target线程中运行的函数;args这个函数运行时需要的实参 t = threading.Thread(target=windows,args=(src,handler,width,interval)) #启动线程 t.start()
分发器代码实现

# Author: Baozi #-*- codeing:utf-8 -*- # Author: Baozi #-*- codeing:utf-8 -*- #日志分析项目 ''' 1.新建一个python文件test.py 2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串 ''' import threading from queue import Queue import datetime import re import random import time # logs = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"''' pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[w/ +:]+)] "(?P<method>w+) (?P<url>S+) (?P<protocol>[w/d.]+)" (?P<status>d+) (?P<length>d+) .+ "(?P<useragent>.+)"''' ops = { 'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'), 'status':int, 'length':int } regex = re.compile(pattern) def extract(line): matcher = regex.match(line) print(matcher.groupdict()) #matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典 info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()} return info def load(path:str): #单文件装载 with open(path)as f: for line in f: d = extract(line) if d: yield d else: #TODO 不合格的数据 continue ############################滑动窗口实现##################################################def windows(src:Queue,handler,int,interval:int): """ :param src:数据源、生成器、用来拿数据 :param handler: 数据处理函数 :param 时间窗口宽度,秒 :param interval: 处理时间间隔,秒 :return: """ start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z') current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z') buffer = [] #窗口中待计算的数据 delta = datetime.timedelta(seconds=width-interval) while True: data = src.get() if data: buffer.append(data) current =data['datetime'] if (current - start).total_seconds() >= interval: ret = handler(buffer) print(ret) start = current #buffer的处理 buffer = [x for x in buffer if x['datetime'] > current - delta] #处理函数 def handler(iterable): vals = [x['value'] for x in iterable] return sum(vals) / len(vals) def donothing_handler(iterable:list): print(iterable) return iterable ######################分发器实现########################################## #数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者 def dispatcher(src): queues = [] threads = [] def req(handler,width,interval): q = Queue() queues.append(q) t = threading.Thread(target=windows,args=(q,handler,width,interval)) threads.append(t) def run(): for t in threads: t.start() for x in src:#一条数据送到n个消费者各自的队列中 for q in queues: q.put(x) return req,run req,run = dispatcher(load('test.log')) #req注册窗口 req(donothing_handler,1,1) #启动 run()
完成分析功能

状态码分析

def status_handler(iterable): #一批时间窗口内的数据 status = {} for item in iterable: key = item['status'] if key not in status.keys(): status[key] = 0 status[key] = 1 total = sum(status.values()) return {k:v/total*100 for k,v in status.items()}
![]()
日志文件的加载

def openfile(path:str): with open(path)as f: for line in f: d = extract(line) if d: yield d else: # TODO 不合格的数据 continue def load(*path:str): #装载日志文件 for file in path: p = Path(file) if not p.exists(): continue if p.is_dir(): for x in p.iterdir(): if x.if_file(): yield from openfile(str(x)) elif p.is_file(): yield from openfile(str(p))

完整代码如下:
1 #日志分析项目 2 ''' 3 1.新建一个python文件test.py 4 2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串 5 ''' 6 import threading 7 from queue import Queue 8 import datetime 9 import re 10 import random 11 import time 12 from pathlib import Path 13 # logline = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"''' 14 pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[w/ +:]+)] "(?P<method>w+) (?P<url>S+) (?P<protocol>[w/d.]+)" (?P<status>d+) (?P<length>d+) .+ "(?P<useragent>.+)"''' 15 16 ops = { 17 'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'), 18 'status':int, 19 'length':int 20 } 21 regex = re.compile(pattern) 22 23 def extract(line): 24 matcher = regex.match(line) 25 print(matcher.groupdict()) 26 #matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典 27 info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()} 28 return info 29 30 def openfile(path:str): 31 with open(path)as f: 32 for line in f: 33 d = extract(line) 34 if d: 35 yield d 36 else: 37 # TODO 不合格的数据 38 continue 39 40 def load(*path:str): 41 #文件装载 42 for file in path: 43 p = Path(file) 44 if not p.exists(): 45 continue 46 if p.is_dir(): 47 for x in p.iterdir(): 48 if x.if_file(): 49 yield from openfile(str(x)) 50 elif p.is_file(): 51 yield from openfile(str(p)) 52 ##################################滑动窗口实现################################################## 53 def windows(src:Queue,handler,int,interval:int): 54 start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z') 55 current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z') 56 buffer = [] #窗口中待计算的数据 57 delta = datetime.timedelta(seconds=width-interval) 58 59 while True: 60 data = src.get() 61 if data: 62 buffer.append(data) 63 current =data['datetime'] 64 65 if (current - start).total_seconds() >= interval: 66 ret = handler(buffer) 67 print(ret) 68 start = current 69 #buffer的处理 70 buffer = [x for x in buffer if x['datetime'] > current - delta] 71 72 #处理函数 73 def status_handler(iterable): 74 #一批时间窗口内的数据 75 status = {} 76 for item in iterable: 77 key = item['status'] 78 if key not in status.keys(): 79 status[key] = 0 80 status[key] = 1 81 total = sum(status.values()) 82 return {k:v/total*100 for k,v in status.items()} 83 84 def handler(iterable): 85 vals = [x['value'] for x in iterable] 86 return sum(vals) / len(vals) 87 88 def donothing_handler(iterable:list): 89 print(iterable) 90 return iterable 91 ##########################数据分发器实现#################################### 92 #数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者 93 def dispatcher(src): 94 queues = [] 95 threads = [] 96 97 def req(handler,width,interval): 98 q = Queue() 99 queues.append(q) 100 101 t = threading.Thread(target=windows,args=(q,handler,width,interval)) 102 threads.append(t) 103 104 def run(): 105 for t in threads: 106 t.start() 107 108 for x in src:#一条数据送到n个消费者各自的队列中 109 for q in queues: 110 q.put(x) 111 112 return req,run 113 114 req,run = dispatcher(load('test.log')) 115 #req注册窗口 116 req(donothing_handler,1,1) 117 # req(status_handler,2,2) 118 119 #启动 120 run()
浏览器分析
useragent


信息提取

from user_agents import parse useragent = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36" uaobj = parse(useragent) print(uaobj.browser) print(uaobj.browser.family,uaobj.browser.version) #输出如下: Browser(family='Chrome', version=(67, 0, 3396), version_string='67.0.3396') Chrome (67, 0, 3396)
1 #日志分析完整代码(新增几个小模块) 2 # Author: Baozi 3 #-*- codeing:utf-8 -*- 4 #日志分析项目 5 ''' 6 1.新建一个python文件test.py 7 2.从日志文件中复制一条日志信息用于测试。logline存储这个日志字符串 8 ''' 9 import threading 10 from queue import Queue 11 import datetime 12 import re 13 import random 14 import time 15 from pathlib import Path 16 from user_agents import parse 17 from collections import defaultdict 18 19 # logline = '''138.60.212.153 - - [19/Feb/2013:10:23:29 +0800] "GET /020/media.html?menu=3 HTTP/1.1" 200 16997 "-" "Mozilla/5.0 (compatible; EasouSpider; +http://www.easou.com/search/spider.html)"''' 20 # pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[w/ +:]+)] "(?P<method>w+) (?P<url>S+) (?P<protocol>[w/d.]+)" (?P<status>d+) (?P<length>d+) .+ "(?P<useragent>.+)"''' 21 pattern = '''(?P<remote>[d.]{7,}) - - [(?P<datetime>[w/ +:]+)] "(?P<request>[^"]+)" (?P<status>d+) (?P<length>d+) .+ "(?P<useragent>.+)"''' 22 23 ops = { 24 'datetime': lambda timestr:datetime.datetime.strptime(timestr,'%d/%b/%Y:%H:%M:%S %z'), 25 'status':int, 26 'length':int, 27 'request':lambda request:dict(zip(('method','url','ptorocol'),request.split())), 28 'useragent':lambda useragent:parse(useragent) 29 } 30 regex = re.compile(pattern) 31 32 def extract(line): 33 matcher = regex.match(line) 34 print(matcher.groupdict()) 35 #matcher.groupdict()函数返回一个包含所有match匹配的命名分组的字典 36 info = {k:ops.get(k,lambda x:x)(v) for k,v in matcher.groupdict().items()} 37 return info 38 39 def openfile(path:str): 40 with open(path)as f: 41 for line in f: 42 d = extract(line) 43 if d: 44 yield d 45 else: 46 # TODO 不合格的数据 47 continue 48 49 def load(*path:str): 50 #文件装载 51 for file in path: 52 p = Path(file) 53 if not p.exists(): 54 continue 55 if p.is_dir(): 56 for x in p.iterdir(): 57 if x.if_file(): 58 yield from openfile(str(x)) 59 elif p.is_file(): 60 yield from openfile(str(p)) 61 ###################################滑动窗口实现############################################## 62 def windows(src:Queue,handler,int,interval:int): 63 start = datetime.datetime.strptime('1971/01/01 00:00:00 +0800','%Y/%m/%d %H:%M:%S %z') 64 current = datetime.datetime.strptime('1971/01/01 00:00:01 +0800','%Y/%m/%d %H:%M:%S %z') 65 buffer = [] #窗口中待计算的数据 66 delta = datetime.timedelta(seconds=width-interval) 67 68 while True: 69 data = src.get() 70 if data: 71 buffer.append(data) 72 current =data['datetime'] 73 74 if (current - start).total_seconds() >= interval: 75 ret = handler(buffer) 76 print(ret) 77 start = current 78 #buffer的处理 79 buffer = [x for x in buffer if x['datetime'] > current - delta] 80 81 #处理函数 82 #状态码分析 83 def status_handler(iterable): 84 #一批时间窗口内的数据 85 status = {} 86 for item in iterable: 87 key = item['status'] 88 if key not in status.keys(): 89 status[key] = 0 90 status[key] = 1 91 total = sum(status.values()) 92 return {k:v/total*100 for k,v in status.items()} 93 94 #浏览器分析 95 ua_dict = defaultdict(lambda :0) 96 def browser_handler(iterable:list): 97 for item in iterable: 98 ua = item['useragent'] 99 key = (ua.browser.family,ua.browser.version_string) 100 ua_dict[key] =1 101 return ua_dict 102 103 def handler(iterable): 104 vals = [x['value'] for x in iterable] 105 return sum(vals) / len(vals) 106 107 def donothing_handler(iterable:list): 108 print(iterable) 109 return iterable 110 ###########################数据分发器实现##################################### 111 #数据分发器:这里做一个简单的一对多副本发送,一个数据通过分发器,发送到n个消费者 112 def dispatcher(src): 113 queues = [] 114 threads = [] 115 116 def req(handler,width,interval): 117 q = Queue() 118 queues.append(q) 119 t = threading.Thread(target=windows,args=(q,handler,width,interval)) 120 threads.append(t) 121 122 def run(): 123 for t in threads: 124 t.start() 125 126 for x in src:#一条数据送到n个消费者各自的队列中 127 for q in queues: 128 q.put(x) 129 return req,run 130 131 req,run = dispatcher(load('test.log')) 132 #req注册窗口 133 # req(donothing_handler,1,1) 134 # req(status_handler,2,2) 135 req(browser_handler,2,2) 136 137 #启动 138 run()