目标
- 文件的概念
- 文件的基本操作
- 文件/文件夹的常用操作
- 文本文件的编码方式
01,文件的概念
1.1 文件的概念和作用
- 计算机的 文件,就是存储在某种 长期存储设备 上的一段 数据
- 长期存储设备包括:硬盘、U盘、移动硬盘、光盘。。。
文件的作用
将数据长期保存下来,在需要的时候使用
1.2 文件的存储方式
- 在计算机中,文件是以 二进制 的方式保存在磁盘上的
文本文件和二进制文件
-
文本文件
- 可以使用 文本编辑软件 查看
- 本质上还是二进制wenjian
- 例如:python的源程序
-
二进制文件
- 保存的内容 不是给人直接阅读的,而是 提供给其它软件使用的
- 例如:图片文件、音频文件、视频文件等等
- 二进制文件不能直接使用 文本编辑软件 查看
02,文件的基本操作
2.1 操作文件的套路
在 计算机 中要操作文件的套路非常固定,一共包含三个步骤:
1,打开文件
2,读写文件
- 读 将文件的内容读入内存
- 写 将内存的内容写进文件
3,关闭文件
2.2 操作文件的函数/方法
- 在
python中要操作文件需要记住1个函数和3个方法
| 序号 | 函数/方法 | 说明 |
|---|---|---|
| 01 | open | 打开文件,并且返回文件操作对象 |
| 02 | read | 将文件内容读取到内存 |
| 03 | write | 将指定内容写入文件 |
| 04 | close | 关闭文件 |
open函数负责打开文件,并且返回文件对象read/write/close三个方法都需要通过 文件对象 来调用
2.3 read 方法 - - 读取文件
open函数的第一个参数是要打开的文件名(文件名区分大小写)- 如果文件 存在,返回 文件操作对象
- 如果文件 不存在 ,会 抛出异常
read方法可以一次性 读入 并 返回 文件的 所有内容close方法负责 关闭文件- 如果 **忘记关闭文件,会造成系统资源消耗,而且会影响到后续对文件的访问
- 注意:方法执行后,会把 文件指针 移动到 文件的末尾
# 1,打开文件
file = open("README")
# 2,读取文件
text = file.read()
print(text)
# 3,关闭文件
file.close()
# 结果呈现
HELLO
HELLO
hello hello
提示
- 在开发中,通常会先编写 打开 和 关闭 的代码,再编写中间针对文件的 读写 操作
文件指针
- 文件指针 标记 从哪个位置开始读取数据
- 第一次打开 文件时,通常 文件指针会指向文件的开始位置
- 当执行了
read方法后,文件指针 会移动到 读取内容的末尾- 默认情况下会移动到 文件末尾
思考
- 如果执行了一次
read方法,读取了所有内容,那么再次调用read方法,还能获取到内容么?
答案
- 不能
- 第一次读取之后,文件指针移动到了文件末尾,再次调用不会再次获取内容
# 1,打开文件
file = open("README")
# 2,读取文件
text = file.read()
print(text)
print(len(text))
print("-" * 20)
text = file.read()
print(text)
print(len(text))
# 3,关闭文件
file.close()
# 结果呈现
HELLO
HELLO
hello hello
23
--------------------
0
2.4 打开文件的方式
open函数默认以 只读方式 打开文件,并且放回文件对象
f = open("文件名", “访问方式”, "指定编码方式")
f = open("file_info", mode='r', encoding="utf-8" )
# 推荐使用
with open("file_info", mode='r', encoding="utf-8" ) as f:
print(f.read())
| 访问方式 | 说明 |
|---|---|
| r | 以 只读 方式打开文件。文件的指针将会放在文件的开头,这是 默认模式。如果文件不存在,抛出异常 |
| w | 以 只写 方式打开文件。如果文件存在会被覆盖。如果不存在,创建新文件 |
| a | 以 追加 方式打开文件。如果该文件已经存在,文件指针将会放在文件的末尾。如果文件不存在,创建新文件进行写入 |
| r+ | 以 读写 方式打开文件。文件的指针警徽放在文件的开头,如果文件不存在,抛出异常 |
| w+ | 以 读写 方式打开文件。如果文件存在会被覆盖,如果文件不存在创建新文件 |
| a+ | 以 读写 方式打开文件。如果该文件存在,文件指针将会放在文件的末尾,如果该文件不存在,创建新文件进行写入 |
提示
- 频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候是以 只读、只写 的方式来操作文件
2.5 按行读取文件内容
read方法默认会把文件的 所有内容 一次性读取到内存- 如果文件太大,对内存的占用非常严重
readline 方法
readline方法可以一次读取一行内容- 方法执行后,会把 文件指针 移动到下一行,准备再次读取
读取大文件的正确姿势
# 1,打开文件
file = open("README")
# 2,写取文件
while True:
text = file.readline()
# 判断是否读取到内容
if not text:
break
print(text)
# 3,关闭文件
file.close()
# 结果呈现
Hello1
Hello2
Hello3
Hello4
Hello5
Hello6
2.6 文件读写案例 - - 复制文件
目标
用代码的方式,实现文件复制过程
小文件复制
- 打开一个已有文件,读取完整内容,并写入到另一个文件
# 打开文件
file_read = open("README")
file_write = open("README_BAK", "w")
# 读写过程
text = file_read.read()
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()
# 结果呈现
Hello1
Hello2
Hello3
大文件复制
- 打开一个已有文件,逐行读取内容,并顺序写入到另一个文件
# 打开文件
file_read = open("README")
file_write = open("README_BAK", "w")
# 读写过程
while True:
text = file_read.readline()
# 判断是否读取到内容
if not text:
break
file_write.write(text)
# 关闭文件
file_read.close()
file_write.close()
# 结果呈现
Hello1
Hello2
Hello3
Hello4
Hello5
Hello6
2.7 文件指针操作方法
| 序号 | 方法名 | 说明 |
|---|---|---|
| 01 | seek | 指定光标移动到某个位置 |
| 02 | tell | 获取光标当前位置 |
| 03 | truncate | 截取文件 |
03,文件/目录的常用管理操作
- 在 终端/文件浏览器、中可以执行常规的 文件/目录 管理操作,例如:
- 创建、重命名、删除、改变路径、查看目录内容、....
- 在
python中,如果希望通过程序实现上述功能,需要导入os模块
文件操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | rename | 重命名文件 | os.rename(源文件名, 目标文件名) |
| 02 | remove | 删除文 | os.remove(文件名) |
目录操作
| 序号 | 方法名 | 说明 | 示例 |
|---|---|---|---|
| 01 | listdir | 目录列表 | os.listdir(目录名) |
| 02 | mkdir | 创建目录 | os.mkdir(目录名) |
| 03 | rmdir | 删除目录 | os.rmdir(删除目录) |
| 04 | getcwd | 获取当前目录 | os.getcwd() |
| 05 | chdir | 修改工作目录 | os.chdir(目录名) |
| 06 | path.isdir | 判断是否是文件 | os.path.isdir(文件路径) |
提示
文件或者目录从这都支持 相对路径 和 绝对路径
实例1:注册登录
注册一个账号密码,登录机会3次
# 注册
username = input("请输入您要注册的账号:")
password = input("请输入您要注册的密码:")
with open("register_login_list_info",mode='w',encoding="utf-8") as f:
f.write("{}
{}".format(username, password))
print("注册成功!!!")
# 登录
login_list = []
count = 0
while count < 3:
login_username = input("请输入您要登录的账号:")
login_password = input("请输入您要登录的密码:")
with open("register_login_list_info", mode='r+', encoding="utf-8") as f1:
for i in f1:
login_list.append(i)
if login_username == login_list[0].strip() and login_password == login_list[1].strip():
print("登录成功!!!")
break
else:
print("账号密码错误!!!")
count += 1
实例2 修改文件内容
modify_file_content.py
import os
with open("work_name",mode="r", encoding="utf-8") as f, open("work_name_bak", mode="w", encoding="utf-8") as f1:
for line in f:
if '小雨' in line:
line = line.replace("小雨", "小水")
# 写文件
f1.write(line)
# 删除源文件
os.remove("work_name")
# 重名文件名
os.rename("work_name_bak", "work_name")
源文件内容 work_name
运维:小风
开发:小雨
修改后的文件内容 work_name
运维:小风
开发:小水
04,文本文件的编码格式
- 文本文件存储的内容是基于 字符编码 的文件,常见的编码有
ASCII编码,UNICODE编码等- Python 2.x 默认使用的是
ASCII编码 - Python 3.x 默认使用的是
UTF-8编码
- Python 2.x 默认使用的是
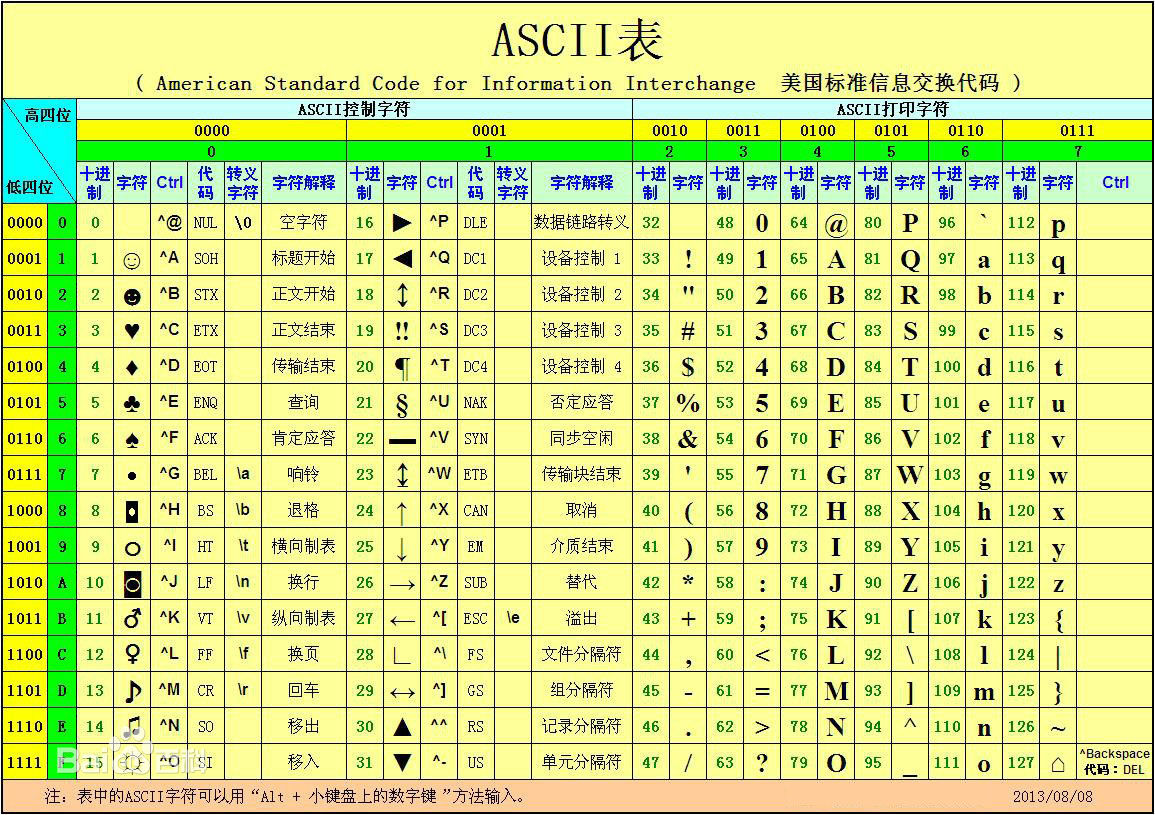
4.1 ASCII 编码 和 UNICODE 编码
ASCII 编码
- 计算机中只有
256个ASCII字符 - 一个
ASCII在内存中占用 1个字节 的空间8个0/1的排列组合方式一共有256种,也就是2 ** 8
UTF-8 编码格式
- 计算机中使用 1-6个字节 来表示一个
UTF-8字符,函盖了 地球上几乎所有地区的文字 - 大多数汉字会使用 3个字节 表示
UTF-8是UNICODE编码的一种编码格式
4.2 Python 2.x 中如何使用中文
-
Python 2.x 默认使用的是
ASCII编码 -
Python 3.x 默认使用的是
UTF-8编码 -
在Python 2.x 文件的 第一行 增加以下代码,解释器会以
utf-8的编码来处理 python 文件
# *-* coding:utf8 *-*
注 这方式是官方推荐是使用的
- 也可以
# conding=utf8
unicode 字符串
- 在
python 2.x中,即使指定了文件使用UTF-8的编码格式,但是在遍历字符串时,仍然会 以字节为单位遍历 字符串 - 更能够 正确的遍历字符串,在定义字符串时,需要 在zi字符串的引导前,增加一个小字母
u告诉解释器这是一个unicode字符串,(使用UTF-8编码格式的字符串)
# *-* coding:utf8 *-*
# 引号前面的u告诉解释器这是一个utf-8编码格式的字符串
hello_str = u"hello 世界"
print(hello_str)
for i in hello_str:
print(i)
# 结果呈现
hello 世界
h
e
l
l
o
世
界