一、什么是字典
1、python内置的数据结构之一,与列表一样是一个可变序列
2、以键值对的方式存储数据,字典是一个无序的序列
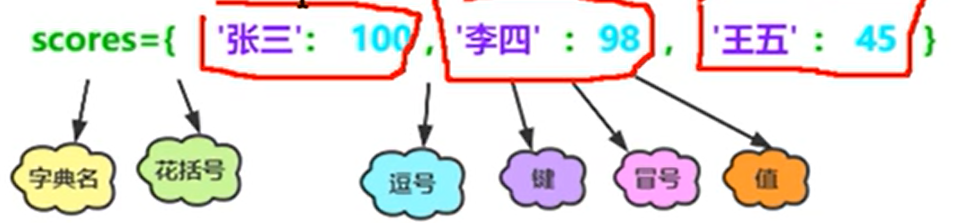
3、字典示意图
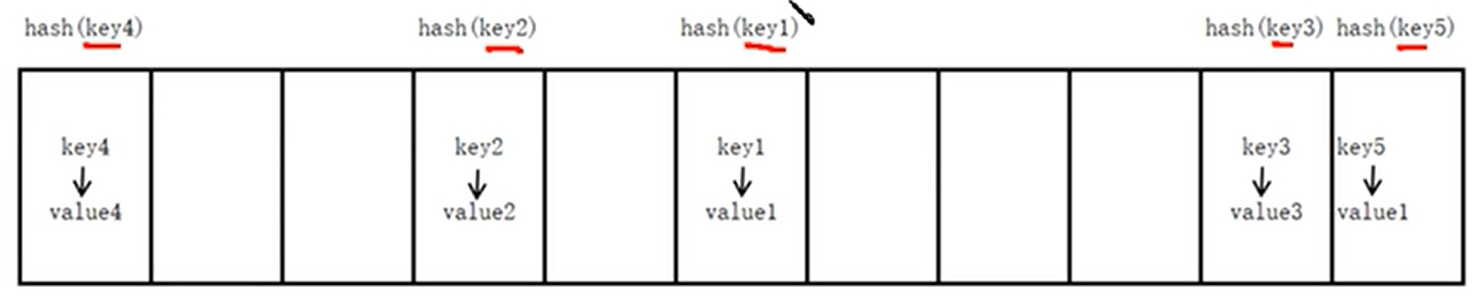
4、字典的实现原理
- 字典的实现原理与查字典类似,查字典是先根据部首或拼音查找对应的页码,python中的字典是根据key值查找value所在的位置
二、字典的创建
1、最常用的方式:使用花括号
2、使用内置函数dict()
#第一种字典的创建方法
scores={'小秦同学在上学':90,'梅达':97,'柳阳':98}
print(scores)
print(type(scores))
#第二种字典的创建方法
student=dict(name='Jack',age=20)
print(student)
print(type(student))
#空字典的创建
d={}
print(d)
print(type(d))
运算结果:
{'小秦同学在上学': 90, '梅达': 97, '柳阳': 98}
<class 'dict'>
{'name': 'Jack', 'age': 20}
<class 'dict'>
{}
<class 'dict'>
三、字典元素的获取
1、字典中元素的获取——[]和get()方法
2、[]取值和get()方法的区别
- 在[]中,如果key不存在,则会报错,抛出keyError异常
- get()方法取值,如果字典中不存在指定的key值,不会报错而是返回None,可以通过设置默认的value,以便指定的key不存在时返回
score={'秦健峰':100,'梅达':50,'刘阳':80}
print(score)
print(score['刘阳'])
#print(score['meida']) #没有该key值,报错KeyError: 'meida'
print(score.get('秦健峰'))
print(score.get('全家福'))#返回None
print(score.get('全家福',99)) #如果’全家福‘不存在,则返回设置的默认值
运算结果:
{'秦健峰': 100, '梅达': 50, '刘阳': 80}
80
100
None
99
四、字典常用操作
- key的判断-看其是否存在
- 删除key-value对
- 新增元素
- 修改元素
score={'秦健峰':100,'梅达':50,'刘阳':80}
print(score)
#判断key是否存在
print('qjf' in score)
print('qjf' not in score)
print('梅达' in score)
print(score['梅达'])
#删除指定的key-value对
#del score['qjf'] #没有该key,则会报错
del score['梅达']
print(score)
#清空key-value对
#score.clear()
#print(score)
#增加新的元素
score['qjf']=99
print(score)
#修改元素
score['qjf']=100
print(score)
运算结果:
{'秦健峰': 100, '梅达': 50, '刘阳': 80}
False
True
True
50
{'秦健峰': 100, '刘阳': 80}
{'秦健峰': 100, '刘阳': 80, 'qjf': 99}
{'秦健峰': 100, '刘阳': 80, 'qjf': 100}
Process finished with exit code 0
五、获取字典视图
- 获取字典中所有key——key()
- 获取字典中所有value——values()
- 获取字典中所有key-value对——items()
#获取所有的key
score={'秦健峰':100,'梅达':50,'刘阳':80}
keys=score.keys()
print(keys)
print(type(keys))
#将dict_keys转变为列表
keys=list(keys)
print(keys) #['秦健峰', '梅达', '刘阳']
#获取所有的value值
values=score.values()
print(values)
print(type(values))
#将dict_values转变为列表
values=list(values)
print(values,type(values)) #[100, 50, 80]
#获取key-value对的值
items=score.items()
print(items)
print(type(items))
#将dict_items转变为列表
items=list(items)
print(items) #[('秦健峰', 100), ('梅达', 50), ('刘阳', 80)] 引入元组概念
运行结果:
dict_keys(['秦健峰', '梅达', '刘阳'])
<class 'dict_keys'>
['秦健峰', '梅达', '刘阳']
dict_values([100, 50, 80])
<class 'dict_values'>
[100, 50, 80] <class 'list'>
dict_items([('秦健峰', 100), ('梅达', 50), ('刘阳', 80)])
<class 'dict_items'>
[('秦健峰', 100), ('梅达', 50), ('刘阳', 80)]
Process finished with exit code 0
六、字典元素的遍历
score={'秦健峰':100,'梅达':50,'刘阳':80}
#字典元素的遍历
#for循环遍历取得到的是key
for i in score:
print(i)
#查看key对应的value
for i in score:
print(i,score[i],score.get(i))
运算结果:
秦健峰
梅达
刘阳
秦健峰 100 100
梅达 50 50
刘阳 80 80
七、字典的特点
- 字典中所有元素都是一个key-value对,key不允许重复,value可以重复
- 字典中的元素是无序的
- 字典中的key必须是不可变对象
- 字典也可以根据需要动态伸缩
- 字典会浪费较大的内存,是一种使用空间换时间的数据结构
八、字典生成式——也就是生成字典
使用内置函数zip():用于将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回由这些元组组成的列表
items=['Fruits','Books','Others']
prices=[96,78,85]
d={item:price for item,price in zip(items,prices)}#{'Fruits': 96, 'Books': 78, 'Others': 85}
print(d)
#使用upper()可以将字符全部变为大写
d={item.upper():price for item,price in zip(items,prices)}#{'FRUITS': 96, 'BOOKS': 78, 'OTHERS': 85}
print(d)