算法其他篇
目录:
1.1 python中字典对象实现原理 返回顶部
注:字典类型是Python中最常用的数据类型之一,它是一个键值对的集合,字典通过键来索引,关联到相对的值,理论上它的查询复杂度是 O(1)
1、哈希表 (hash tables)
1. 哈希表(也叫散列表),根据关键值对(Key-value)而直接进行访问的数据结构。
2. 它通过把key和value映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。
3. 而这个映射函数叫做哈希函数,存放值的数组叫做哈希表。
4. 通过把每个对象的关键字k作为自变量,通过一个哈希函数h(k),将k映射到下标h(k)处,并将此对象存储在这个位置。
2、具体操作过程
1. 数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,
将value存储在以该数字为下标的数组空间里。
2. 数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
3、{“name”:”zhangsan”,”age”:26} 字典如何存储的呢?
1. 比如字典{“name”:”zhangsan”,”age”:26},那么他们的字典key为name、age,假如哈希函数h(“name”) = 1、h(“age”)=3,
2. 那么对应字典的key就会存储在列表对应下标的位置,[None, “zhangsan”, None, 26 ]
4、解决hash冲突

1.2 顺序表 返回顶部
1、顺序表特点
1. 线性表的逻辑顺序与物理顺序一致,数据元素之间的关系是以元素在计算机内“物理位置相邻”来体现。
2. 对顺序表中的所有表项,即可以进行顺序的访问,也可以随机的访问,也就是说,
既可以从表的第一个表项开始逐个访问表项也可以按照表项的序号(下标)直接的访问。
3. 无需为表示结点间的逻辑关系而增加额外的存储空间,存储利用率提高。
4. 可以方便的存储表中的任一结点,存储速度快。
缺点:
1)在表中插入新元素或删除无用元素时,为了保持其他元素的相对次序不变,平均需要移动一半元素,运行效率低
2)由于顺序表要求占用连续的空间,如果预先进性存储分配,则当表长度变化较大时,难以确定合适的存储空间带大小
3)若按可能达到的最大的长度预先分配表的空间,则容易造成一部分空间长期的限制而得不到充分的利用
2、链表
1. 链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
2. 链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
3. 每个结点包括两个部分:数据域和指针域
特点:
1)可以方便的进行扩充。
2)可以方便的删除和插入。
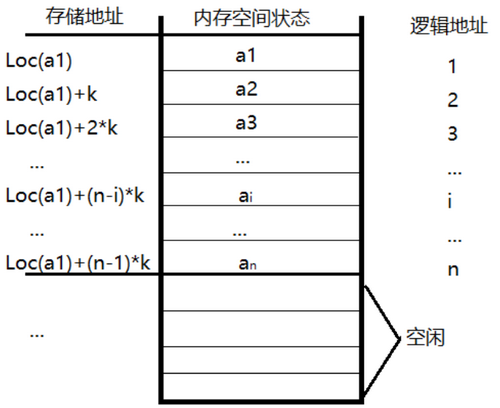
3、顺序表的线性存储示意图
1. 假设线性表中有n个元素,每个元素占k个存储单元,第一个元素的地址为Loc(a1),则第i个元素的地址Loc(ai):
2. Loc(ai) = Loc(a1) + (i-1) * k; # 其中Loc(a1)称为基地址。
4、顺序表增删改查原理


# 1、顺序表的初始化 顺序表的初始化就是把顺序表 初始化为空的顺序表;只需把顺序表的长度length置为0即可; # 2、求顺序表的长度 顺序表的长度就是就顺序表中的元素的个数,由于在插入和删除操作中都有对数据表的长度进行修改,所以求表长只需返回length的值即可; # 3、按序号查找 查找顺序表中第i个元素的值(按序号查找),如果找到,将将该元素值赋给e。 查找第i个元素的值时,首先要判断查找的序号是否合法,如果合法,返回第i个元素对应的值。 # 4、插入元素 在数据表的第i个位置插入元素,在顺序表的第i个位置插入元素e 首先将顺序表第i个位置的元素依次向后移动一个位置,然后将元素e插入第i个位置,移动元素要从后往前移动元素, 即:先移动最后一个元素,在移动倒数第二个元素,依次类推; 插入元素之前要判断插入的位置是否合法,顺序表是否已满,在插入元素之后要将表长L->length++; # 5、删除操作 删除表中的第i个元素e,删除数据表中的第i个元素,需要将表中第i个元素之后的元素依次向前移动一位,将前面的元素覆盖掉。 移动元素时要想将第i+1个元素移动到第i个位置,在将第i+2个元素移动i+1的位置,直到将最后一个元素移动到它的前一个位置。 进行删除操作之前要判断顺序表是否为空,删除元素之后,将表长L->length--; # 6、按内容查找 查找数据元素e在表中的位置,可以从表头开始一直遍历表中元素。 如果找到与要查找元素e相等的元素,则返回元素在表中的位置,数组下标从0开始。 则元素在表中对应的位置序号值应为对应数组下标加1,没有找到则返回0。 # 7、头插 头插,即在表头插入元素e,在表头插入元素,需要将表中的元素依次后移一位, 然后将要插入的元素e赋给数字的首元素,执行插入操作后将表长L->length++; 需要注意的是移动元素要从顺序表的最后一个元素开始移动, 如果从第1个元素开始移动,会使得第1个元素的值覆盖第2个元素的值,然后把第二个元素后移则会使第2个元素的值 (原来第1个元素值)覆盖第3个元素的值,依次类推,最后出插入元素外,其余元素值均为原顺序表中第一个元素的值。 # 8、头删 删除顺序表中的第一个元素,只要将顺序表中的元素从第2个开始,依次向前移动1位,覆盖原来顺序表中元素对应位置的前一个值 在删除元素之前要判断顺序表是否为空,删除顺序表元素之后将顺序表长度L->length--; # 9、尾插 在顺序表表尾插入元素e,L->data[L->length] = e;将元素e的值赋给顺序表中最后一个元素的下一个元素; 尾插操作,需要判断顺序表是否已满,尾插后将顺序表长度L->length++; # 10、尾删 删除表尾元素,只需将顺序表的长度减1,类似于出栈操作,栈顶指针top –。 # 11、清空顺序表 清空顺序表就是将表中的元素删除。删除表中的元素只需将表的长度置为0。 # 12、判断表是否为空 如果顺序表的长度为0,则顺序表为空,返回1,否则,返回0; # 13、打印表中元素 依次打印顺序表中的元素,如果顺序表为空则输出提示。
1.3 python 列表(list) 返回顶部
1、python列表
1. 在CPython中,列表被实现为长度可变的数组。
2. 列表对象在 C 程序中的数据结构:有一个指针数组用来保存列表元素的指针,和一个可以在列表中放多少元素的标记。
3. 内存的槽的个数并不是当前列表就有这么多的元素,列表元素的个数和 len(列表)是一样,就是真正的元素的个数。
4. 但分配的槽的大小,会比元素个数大一点,目的就是为了防止在每次添加元素的时候都去调用分配内存的函数。
2、C中数组存储方式
1. 必须牢记:定义并初始化一个数组后,在内存里分配了两个空间,一个用于存放数组的引用变量,一个用于存放数组本身。
2. 数组引用变量只是一个引用,这个引用变量可以指向任何有效的内存,只有当该引用指向有效内存后,才可通过该数组变量来访问数组元素。
3. 如果我们希望在程序中访问数组,则只能通过这个数组的引用变量来访问它。
4. 实际的数组元素被存储在堆(heap)内存中;数组引用变量是一个引用类型的变量,被存储在栈(stack)内存中。
3、python列表操作时间复杂度
index() O(1)
append O(1)
pop() O(1)
pop(i) O(n)
insert(i,item) O(n)
del operator O(n)
reverse O(n)
sort O(nlogn)
4、列表和元组比较
1. 列表是动态的,其大小可以改变(重新分配);
2. 而元组是不可变的,一旦创建就不能修改。
3. list和tuple在c实现上是很相似的,对于元素数量大的时候,都是一个数组指针,指针指向相应的对象,找不到tuple比list快的理由。
4. 但对于小对象来说,tuple会有一个对象池,所以小的、重复的使用tuple还有益处的。
5、tuple使用场景
1. 实际情况中的确也有不少大小固定的列表结构,例如二维地理坐标等;
2. 另外tuple也给元素天然地赋予了只读属性;
6、列表与字典比较
1. list是有序的,dict是无序的
2. list通过索引访问,dict使用key访问
3. list随着数量的正常增长要想查找元素的时间复杂度为O(n), dict不随数量而增长而变化,时间负责都为O(1)
7、列表和字典应用场景
1. list一般可作为队列、堆栈使用,而dict一般作为聚合统计或者快速使用特征访问等
2. list 是记录简单有序数据的,就是一对一的那种,可以理解为一维数组.
3. dict 是记录复杂无序数据,就是一对多,可以理解为多维数组.