Calinski-Harabasz准则有时称为方差比准则 (VRC),它可以用来确定聚类的最佳K值。Calinski Harabasz 指数定义为:
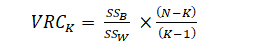
其中,K是聚类数,N是样本数,SSB是组与组之间的平方和误差,SSw是组内平方和误差。因此,如果SSw越小、SSB越大,那么聚类效果就会越好,即Calinsky criterion值越大,聚类效果越好。
1.下载permute、lattice、vegan包
install.packages(c("permute","lattice","vegan"))
2.引入permute、lattice、vegan包
library(permute)
library(lattice)
library(vegan)
3.读取数据
data <- read.csv("data/data.csv")
4.计算最佳K值
fit <- cascadeKM(data,3,10,iter=10,criterion="calinski") calinski.best <- as.numeric(which.max(fit$results[2,]))
5.图片保存
png(file="data/calinskibest.png") plot(fit, sortg = TRUE, grpmts.plot = TRUE) dev.off()
6.截图

封装DetermineClustersNumHelper.R类
# ============================ # 确定最佳聚类K值 # # ============================ # 引入包库 library(permute) library(lattice) library(vegan) # 获取最佳K值函数 get_best_calinski <- function(file_name){ # 获取故障数据 data <- read.csv(paste("data/km/",file_name,".csv",sep=""),header = T) # 计算 fit <- cascadeKM(data,3,10,iter=10,criterion="calinski") calinski.best <- as.numeric(which.max(fit$results[2,])) # 保存图片 png(file=paste("data/km/",file_name,calinski.best,".png",sep="")) plot(fit, sortg = TRUE, grpmts.plot = TRUE) dev.off() } # ========================================================================== # For example #file_list <- array(c("failure_data_normalization","failure_normal_data_normalization")) #for(file in file_list){
# # 调用函数 # get_best_calinski(file) #} # ==========================================================================