# 通过脚本同时运行几个spider
目录结构:
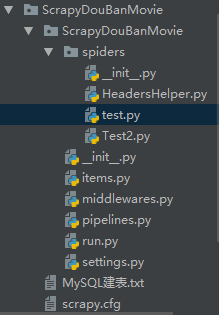
1.在命令行能通过的情况下创建两个spider如
TestSpider
Test2Spider
2.在items.py的同级目录创建run.py文件,有三种方式,任选其一,其代码如下:
方式一: 通过CrawlerProcess同时运行几个spider
run_by_CrawlerProcess.py源代码:
1 # 通过CrawlerProcess同时运行几个spider 2 from scrapy.crawler import CrawlerProcess 3 # 导入获取项目配置的模块 4 from scrapy.utils.project import get_project_settings 5 # 导入蜘蛛模块(即自己创建的spider) 6 from spiders.test import TestSpider 7 from spiders.test2 import Test2Spider 8 9 # get_project_settings() 必须得有,不然"HTTP status code is not handled or not allowed" 10 process = CrawlerProcess(get_project_settings()) 11 process.crawl(TestSpider) # 注意引入 12 #process.crawl(Test2Spider) # 注意引入 13 process.start()
方式二:通过CrawlerRunner同时运行几个spider
run_by_CrawlerRunner.py源代码:
1 # 通过CrawlerRunner同时运行几个spider 2 from twisted.internet import reactor 3 from scrapy.crawler import CrawlerRunner 4 from scrapy.utils.log import configure_logging 5 # 导入获取项目配置的模块 6 from scrapy.utils.project import get_project_settings 7 # 导入蜘蛛模块(即自己创建的spider) 8 from spiders.test import TestSpider 9 from spiders.test2 import Test2Spider 10 11 configure_logging() 12 # get_project_settings() 必须得有,不然"HTTP status code is not handled or not allowed" 13 runner = CrawlerRunner(get_project_settings()) 14 runner.crawl(TestSpider) 15 #runner.crawl(Test2Spider) 16 d = runner.join() 17 d.addBoth(lambda _: reactor.stop()) 18 reactor.run() # the script will block here until all crawling jobs are finished
方式三:通过CrawlerRunner和链接(chaining) deferred来线性运行来同时运行几个spider
run_by_CrawlerRunner_and_Deferred.py源代码:
1 # 通过CrawlerRunner和链接(chaining) deferred来线性运行来同时运行几个spider 2 from twisted.internet import reactor, defer 3 from scrapy.crawler import CrawlerRunner 4 from scrapy.utils.log import configure_logging 5 # 导入获取项目配置的模块 6 from scrapy.utils.project import get_project_settings 7 # 导入蜘蛛模块(即自己创建的spider) 8 from spiders.test import TestSpider 9 from spiders.test2 import Test2Spider 10 11 configure_logging() 12 # get_project_settings() 必须得有,不然"HTTP status code is not handled or not allowed" 13 runner = CrawlerRunner(get_project_settings()) 14 15 @defer.inlineCallbacks 16 def crawl(): 17 yield runner.crawl(TestSpider) 18 #yield runner.crawl(Test2Spider) 19 reactor.stop() 20 21 crawl() 22 reactor.run() # the script will block here until the last crawl call is finished
3.修改两个spider文件引入items,和外部类的如(HeadersHelper.py)的引入模式(以run.py所在目录为中心)
原导入模式:
from ..items import ScrapydoubanmovieItem from .HeadersHelper import HeadersHelper
注释:这种导入能够在命令行scrapy crawl Test正常运行
修改为:
from items import ScrapydoubanmovieItem from .HeadersHelper import HeadersHelper
注释:修改后这种导入在命令行scrapy crawl Test会报错,但通过运行run.py文件,能够同时运行两个spider
4.按照运行python文件的方式运行run.py,可以得到结果